Introducción a los RDD de PySpark
Fundamentos de big data con PySpark

Upendra Devisetty
Science Analyst, CyVerse
¿Qué es un RDD?
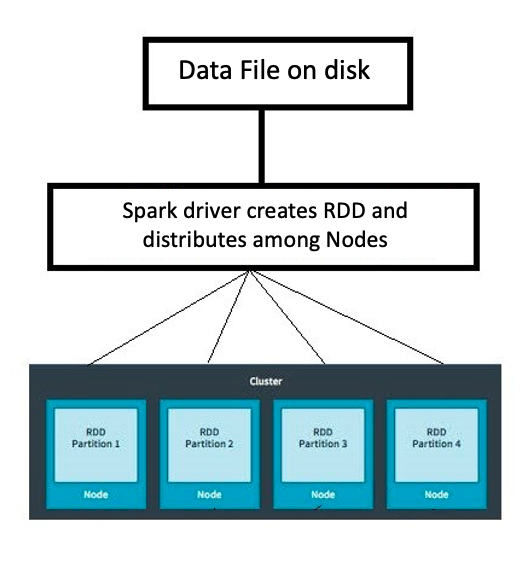
- RDD = Resilient Distributed Datasets
Fundamentos de big data con PySpark
Upendra Devisetty
Science Analyst, CyVerse

