Introducción al clustering
Fundamentos de big data con PySpark

Upendra Devisetty
Science Analyst, CyVerse
Clustering con K-means
- K-means es el método de clustering más usado
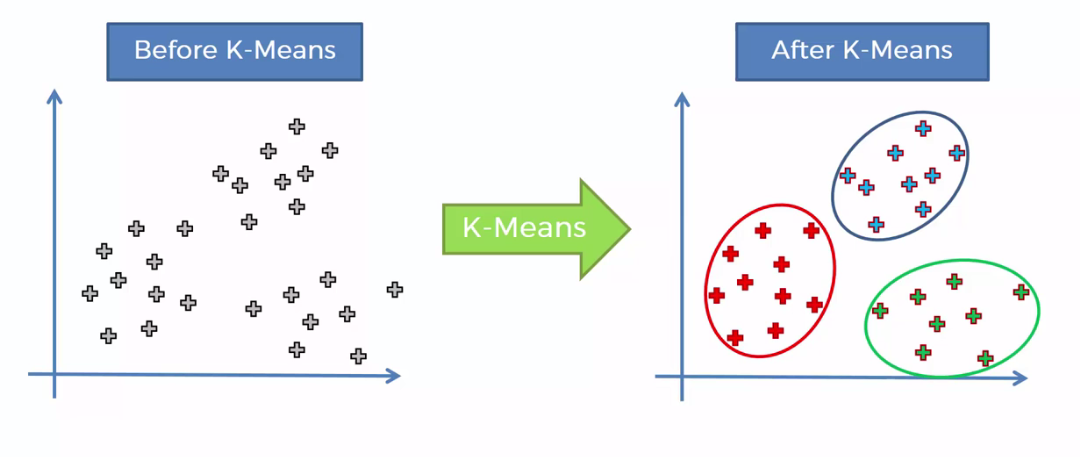
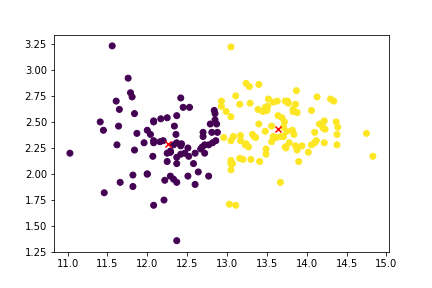
Visualizar clusters con K-means
Fundamentos de big data con PySpark
Upendra Devisetty
Science Analyst, CyVerse

