Operaciones RDD en PySpark
Fundamentos de big data con PySpark

Upendra Devisetty
Science Analyst, CyVerse
Resumen de operaciones en PySpark

- Las transformaciones crean nuevos RDD
- Las acciones calculan sobre los RDD
Transformaciones de RDD
- Las transformaciones usan evaluación perezosa (Lazy)

Transformaciones básicas de RDD
map(),filter(),flatMap()yunion()
Transformación map()
- La transformación map() aplica una función a todos los elementos del RDD
![]()
RDD = sc.parallelize([1,2,3,4])
RDD_map = RDD.map(lambda x: x * x)
Transformación filter()
- La transformación filter devuelve un RDD nuevo solo con los elementos que cumplen la condición

RDD = sc.parallelize([1,2,3,4])
RDD_filter = RDD.filter(lambda x: x > 2)
Transformación flatMap()
- La transformación flatMap() devuelve varios valores por cada elemento del RDD original
![]()
RDD = sc.parallelize(["hello world", "how are you"])
RDD_flatmap = RDD.flatMap(lambda x: x.split(" "))
Transformación union()
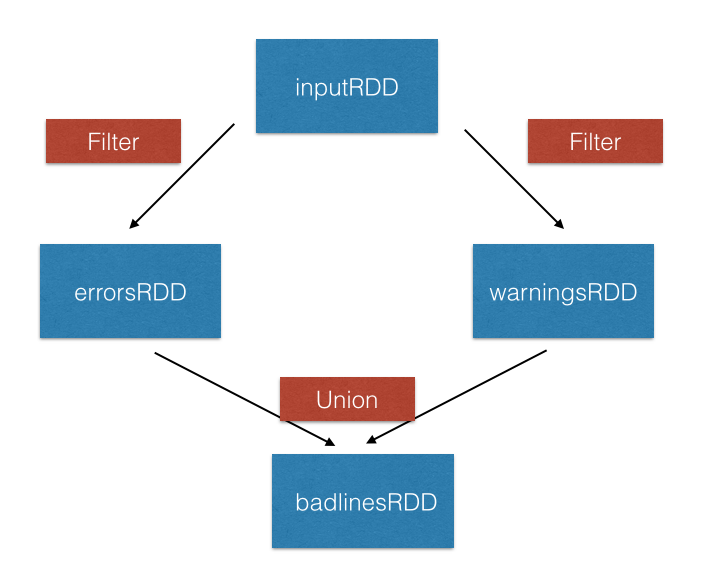
inputRDD = sc.textFile("logs.txt")
errorRDD = inputRDD.filter(lambda x: "error" in x.split())
warningsRDD = inputRDD.filter(lambda x: "warnings" in x.split())
combinedRDD = errorRDD.union(warningsRDD)

