Re-muestreo e interpolación con .resample()
Manipulación de series temporales en Python

Stefan Jansen
Founder & Lead Data Scientist at Applied Artificial Intelligence
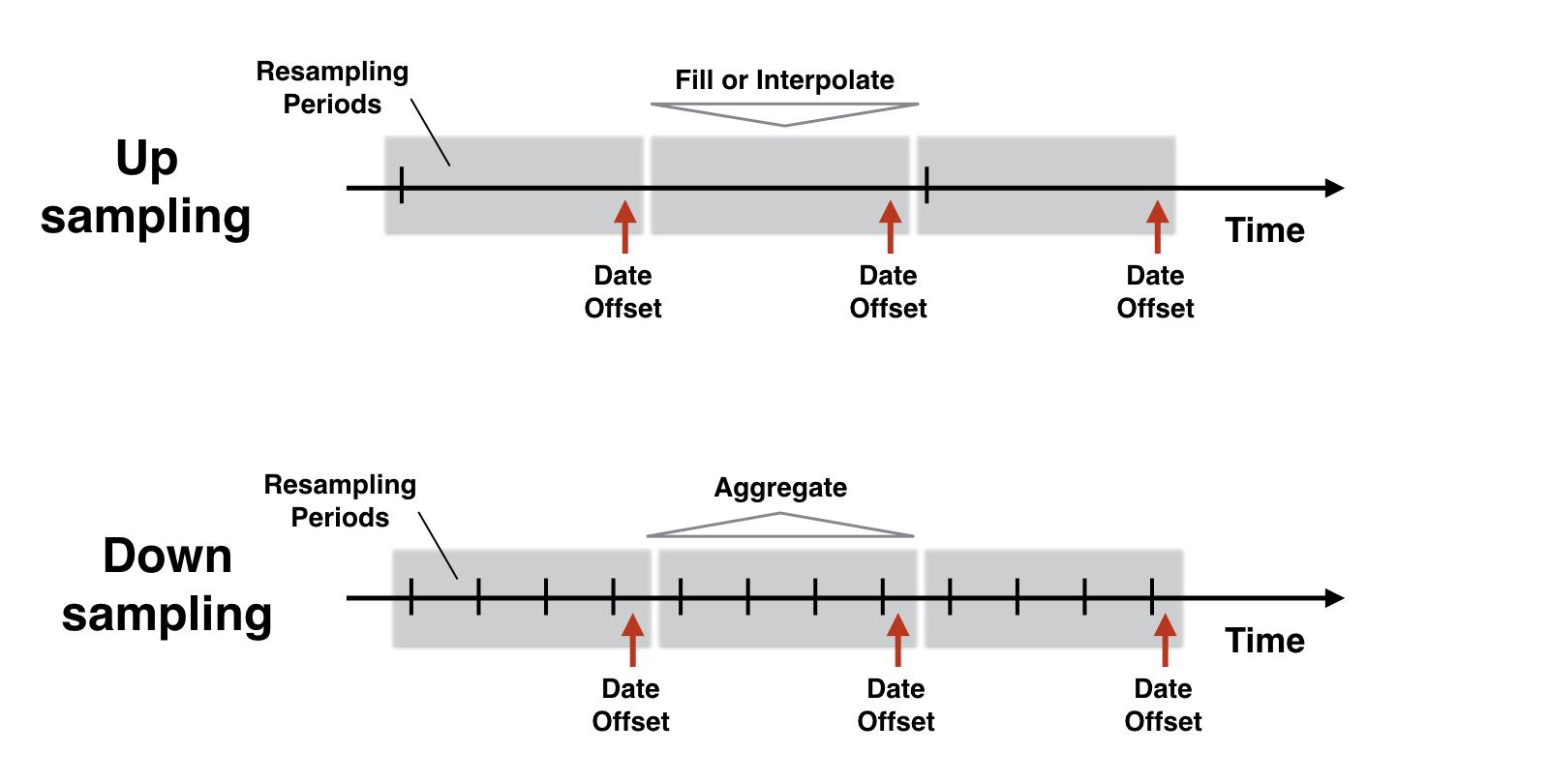
Lógica de remuestreo
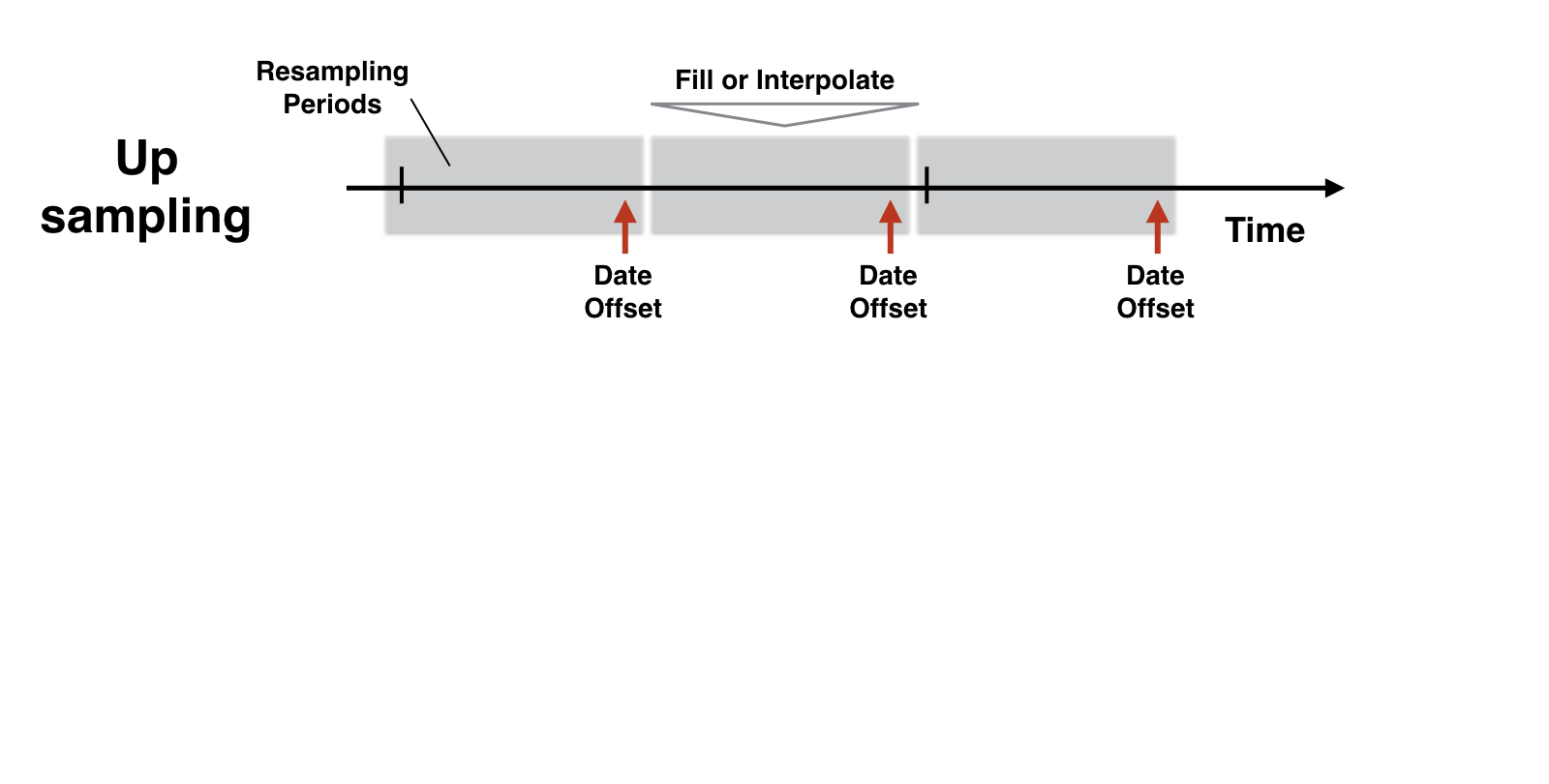
Lógica de remuestreo
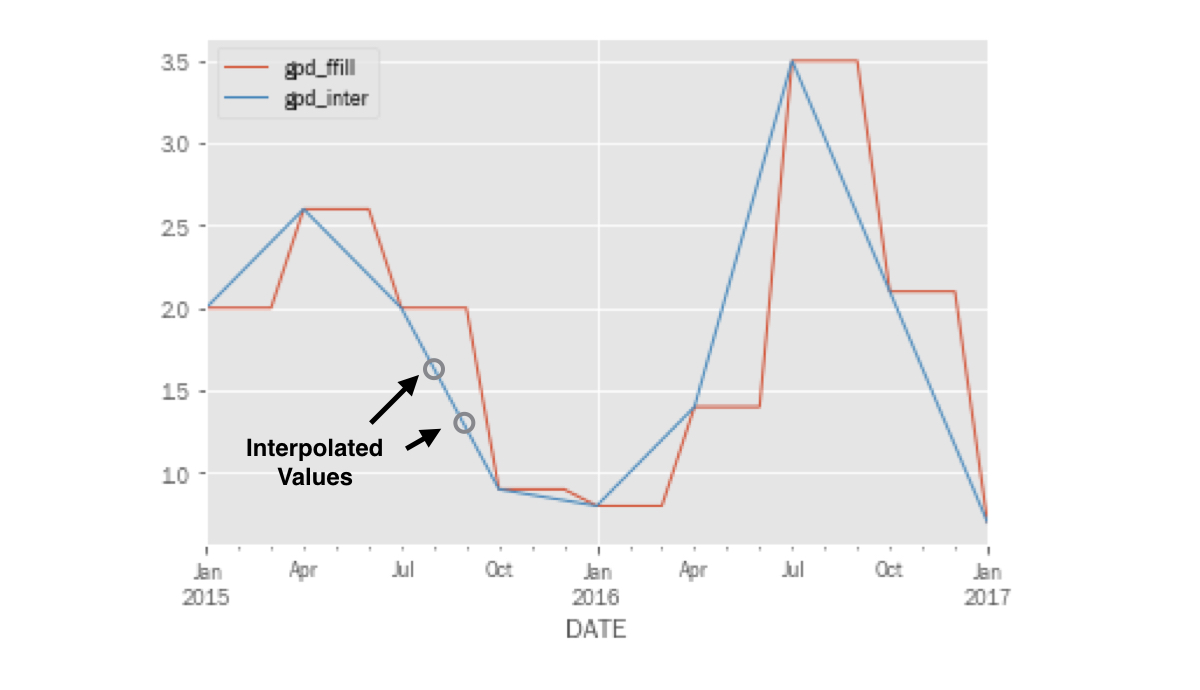
Graficar crecimiento del PIB interpolado
pd.concat([gdp_1, gdp_2], axis=1).loc['2015':].plot()
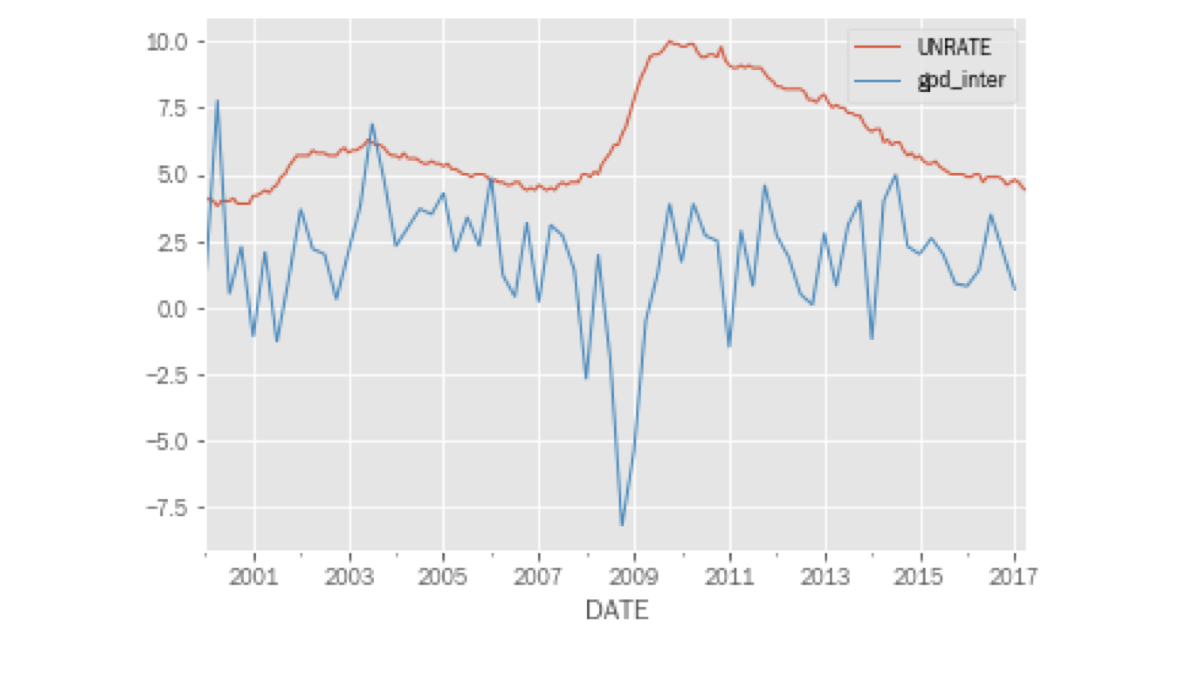
Combinar crecimiento del PIB y desempleo
pd.concat([unrate, gdp_inter], axis=1).plot();