Transformar variables
Introducción a la regresión con statsmodels en Python

Maarten Van den Broeck
Content Developer at DataCamp
Conjunto de datos de perca

No es una relación lineal
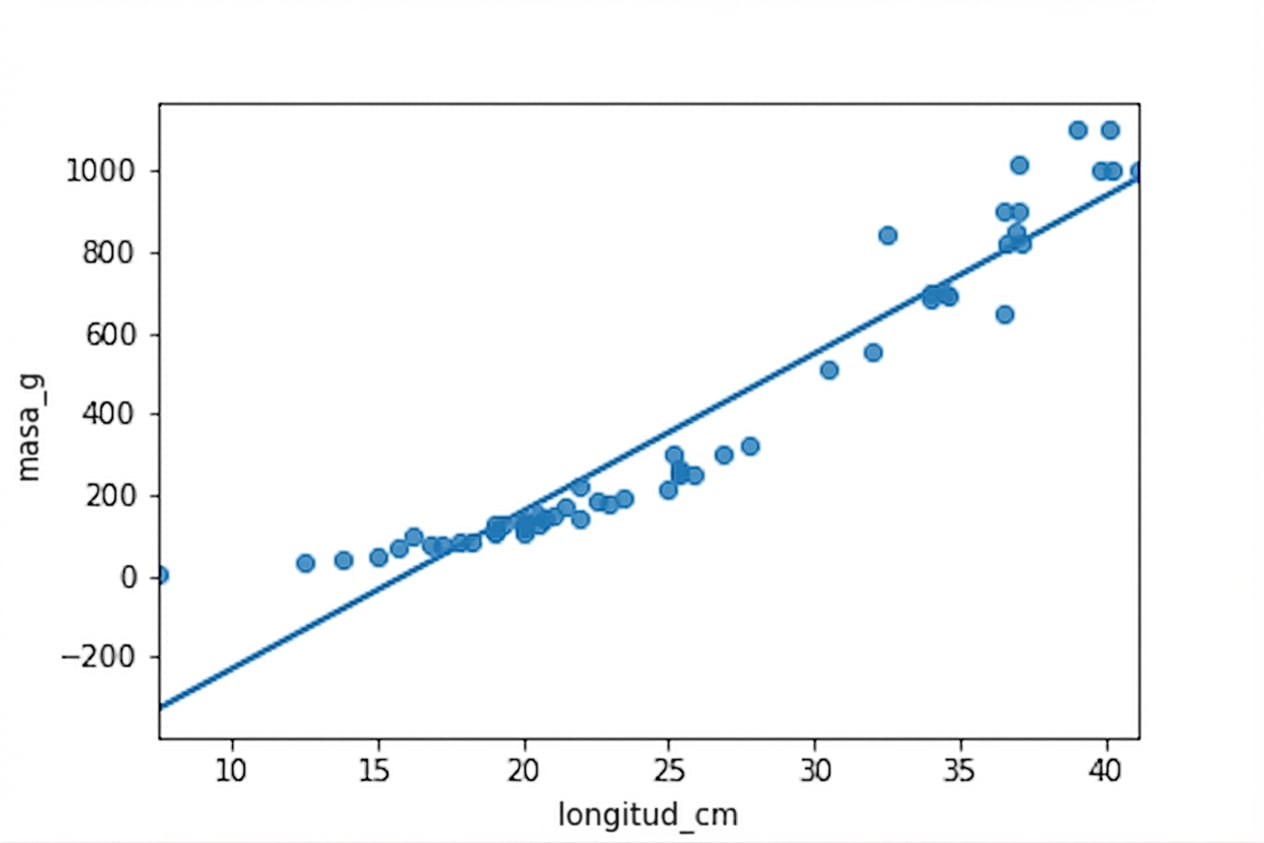
Besugo vs. perca

Graficar masa vs. longitud al cubo
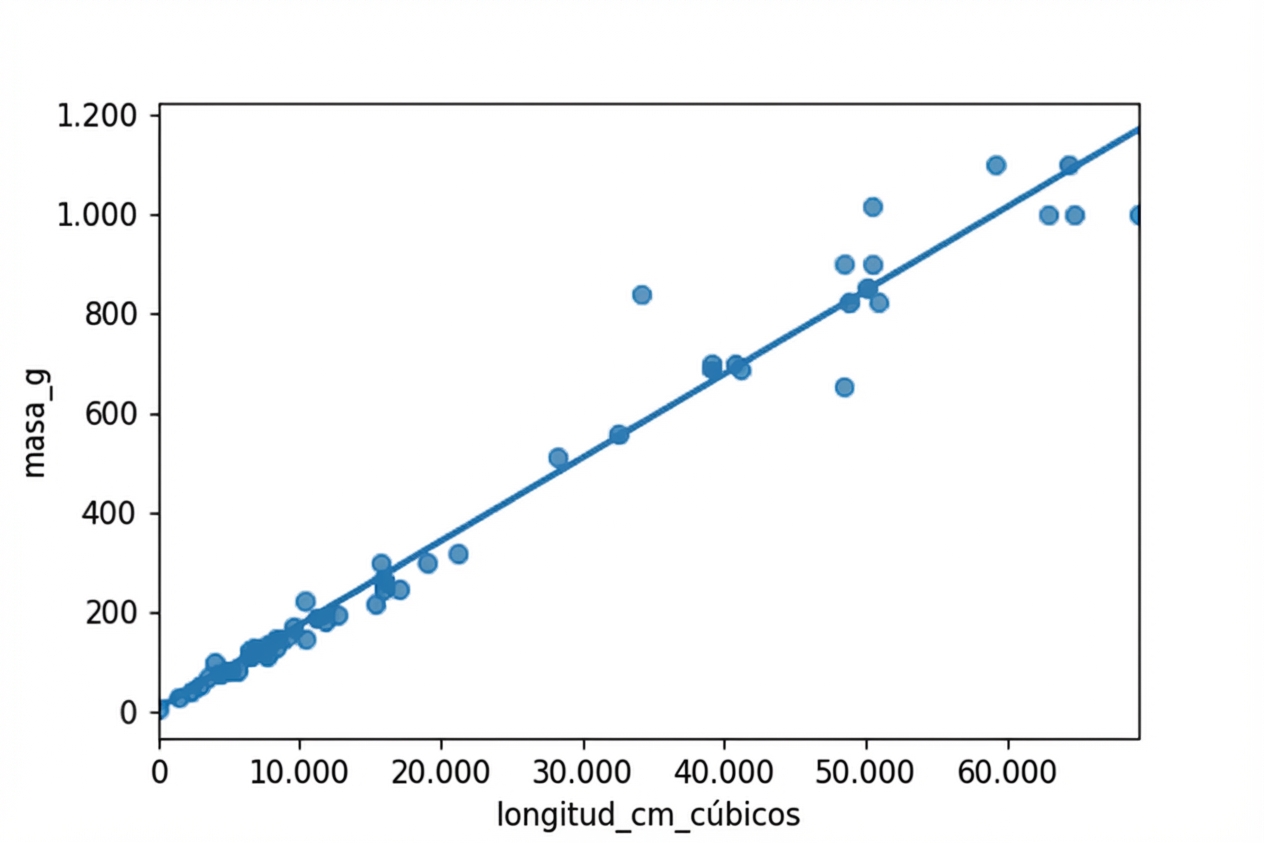
Graficar masa vs. longitud al cubo
fig = plt.figure()
sns.regplot(x="length_cm_cubed", y="mass_g",
data=perch, ci=None)
sns.scatterplot(data=prediction_data,
x="length_cm_cubed", y="mass_g",
color="red", marker="s")
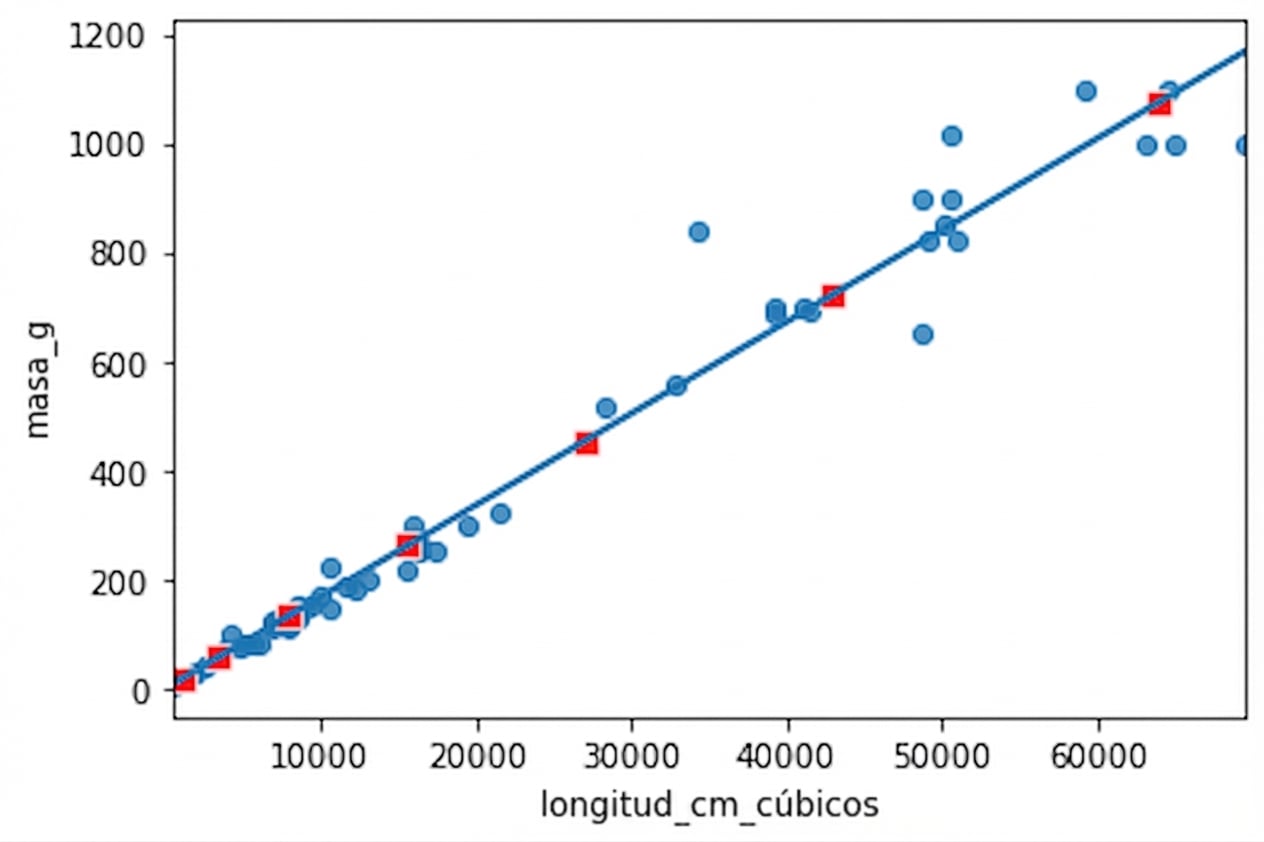
fig = plt.figure()
sns.regplot(x="length_cm", y="mass_g",
data=perch, ci=None)
sns.scatterplot(data=prediction_data,
x="length_cm", y="mass_g",
color="red", marker="s")
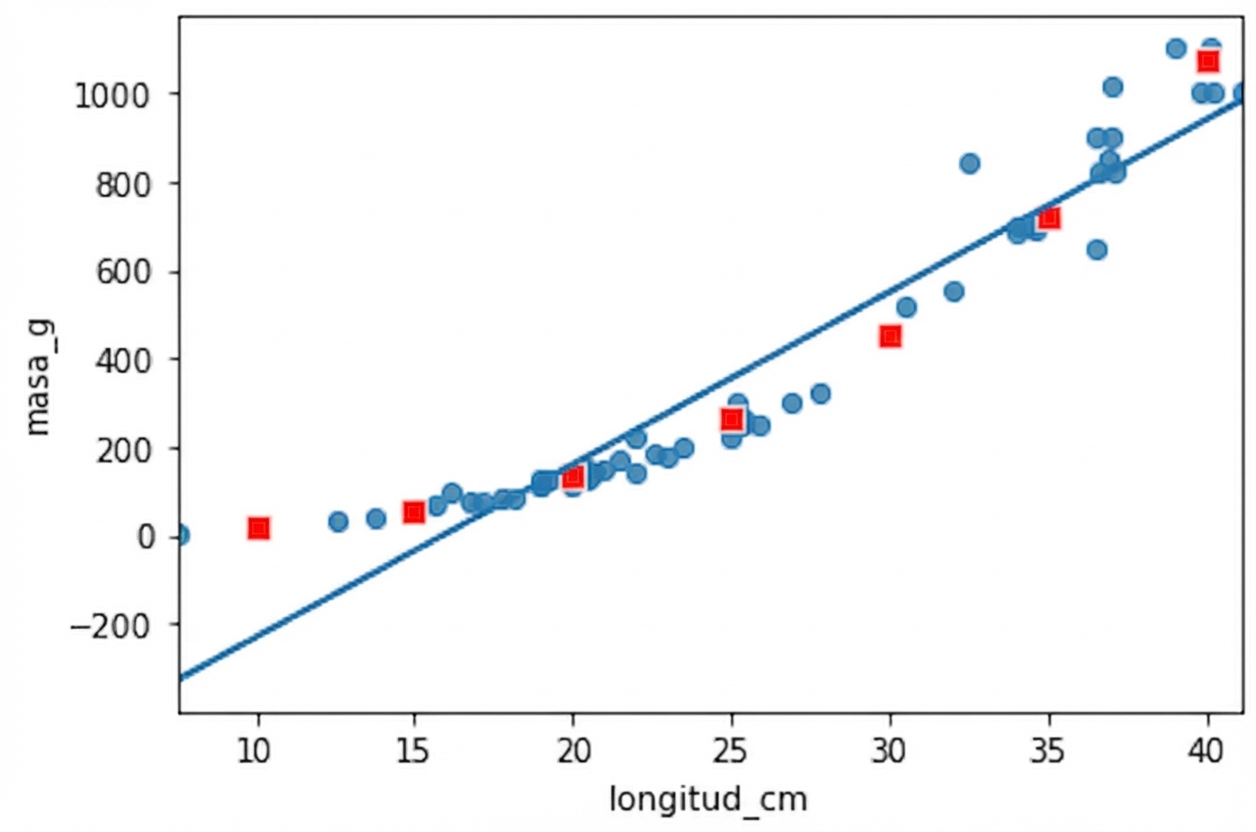
El gráfico está apelotonado
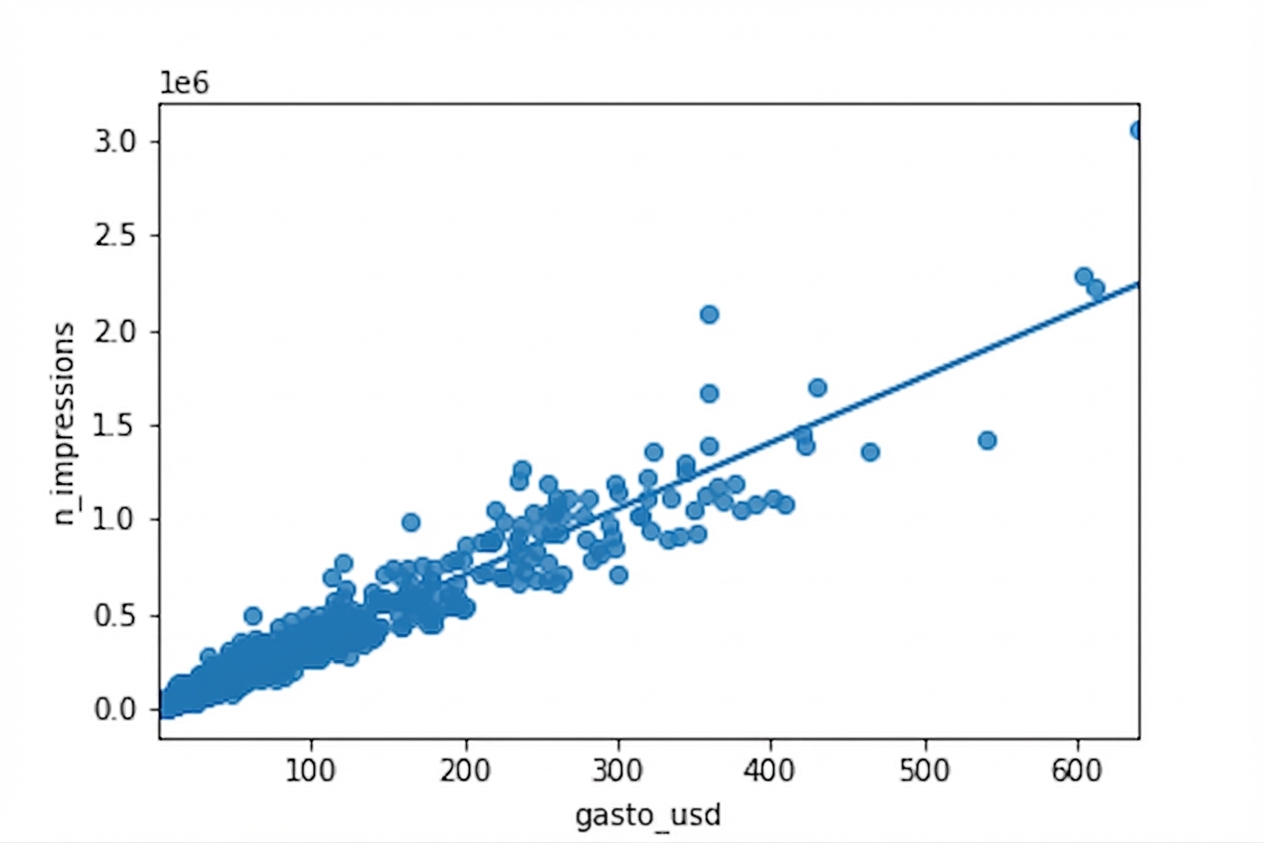
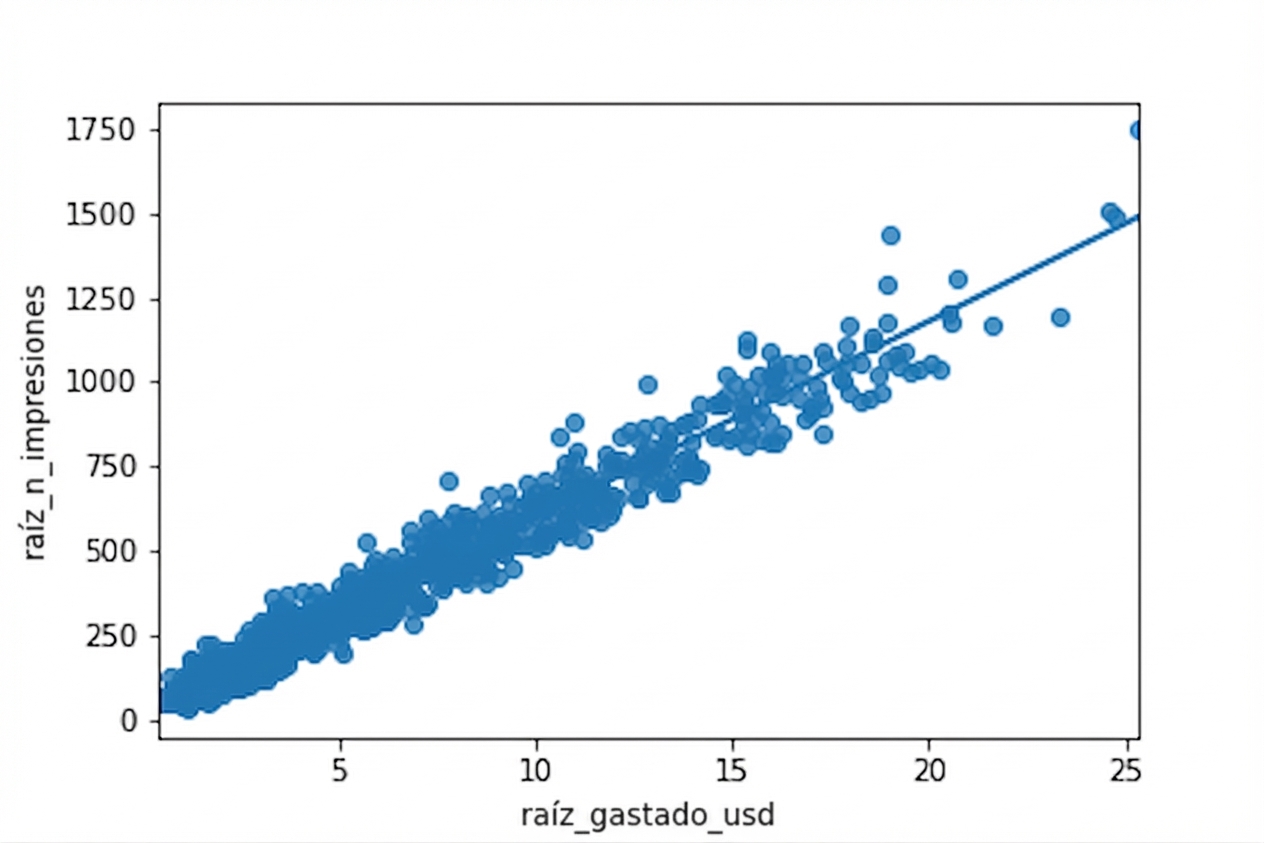
Raíz cuadrada vs. raíz cuadrada