Einstichproben-Anteilstests
Hypothesentests in Python

James Chapman
Curriculum Manager, DataCamp
p-Wert berechnen
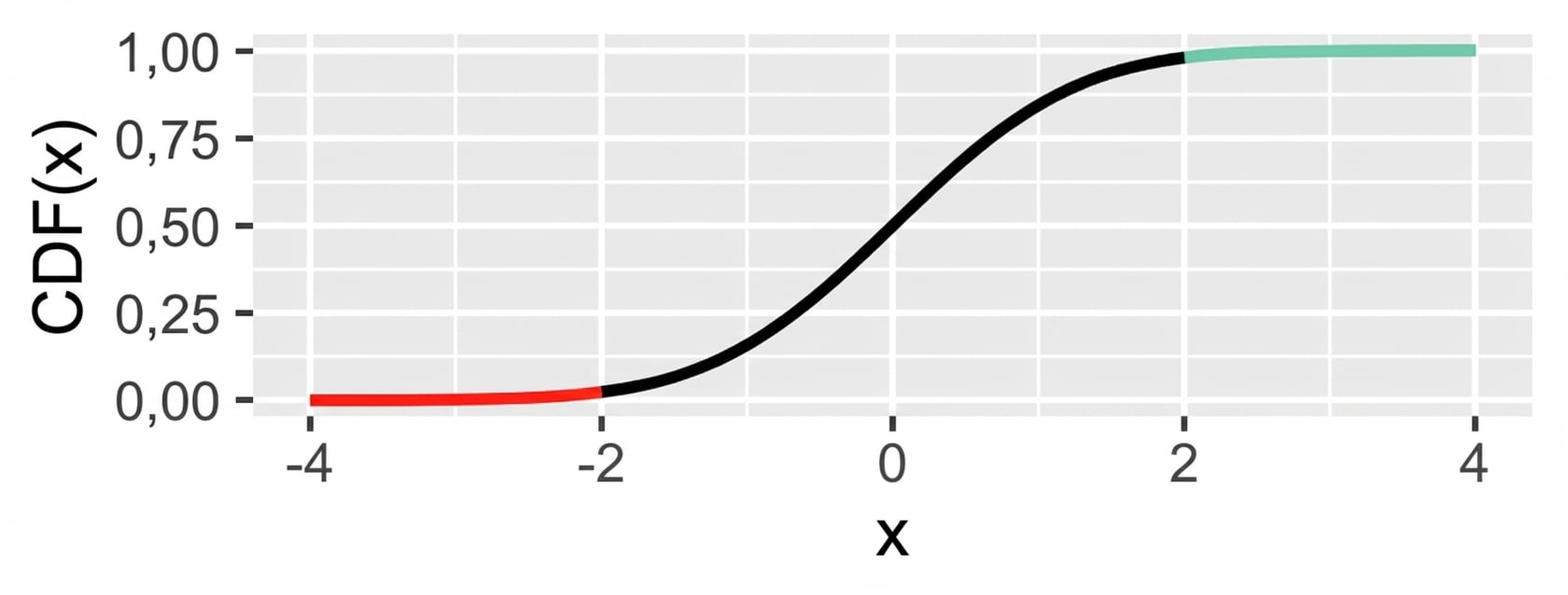 Linksschwanz ("kleiner als"):
Linksschwanz ("kleiner als"):
from scipy.stats import norm
p_value = norm.cdf(z_score)
Rechtsschwanz ("größer als"):
p_value = 1 - norm.cdf(z_score)

