Die Anklage muss „ohne vernünftigen Zweifel“ Beweise für ein Schuldspruch liefern
Alter beim ersten Programmieren
age_first_code_cut klassifiziert, wann Stack-Overflow-Nutzende mit dem Programmieren begonnen haben
"adult" heißt Start mit 14 oder älter
"child" heißt Start vor 14
Frühere Forschung: 35 % der Softwareentwickler/innen starteten als Kinder
Gibt es Evidenz, dass bei Data Scientists der Anteil höher ist?
Definitionen
Eine Hypothese ist eine Aussage über einen unbekannten Populationsparameter
Ein Hypothesentest prüft zwei konkurrierende Hypothesen
Die Nullhypothese ($H_{0}$) ist die bestehende Annahme
Die Alternativhypothese ($H_{A}$) ist die neue, „herausfordernde“ Annahme der Forschenden
Für unser Problem:
$H_{0}$: Der Anteil von Data Scientists, die als Kinder mit dem Programmieren starteten, beträgt 35 %
$H_{A}$: Der Anteil von Data Scientists, die als Kinder mit dem Programmieren starteten, ist größer als 35 %
1 „Naught“ ist britisches Englisch für „null“. Aus historischen Gründen ist „H-naught“ die internationale Konvention für die Aussprache der Nullhypothese.
Strafprozess vs. Hypothesentest
Entweder $H_{A}$ oder $H_{0}$ ist wahr (nicht beide)
Zunächst wird $H_{0}$ als wahr angenommen
Am Ende: „$H_{0}$ verwerfen“ oder „$H_{0}$ nicht verwerfen“
Ist die Evidenz aus der Stichprobe „signifikant“ für $H_{A}$, verwerfe $H_{0}$, sonst wähle $H_{0}$
Signifikanzniveau entspricht „ohne vernünftigen Zweifel“ beim Hypothesentesten
Einseitige vs. zweiseitige Tests
Hypothesentests prüfen, ob die Stichprobenstatistik in den Endbereichen der Nullverteilung liegt
Test
Endbereich
Alternative ungleich Null
zweiseitig
Alternative größer als Null
rechtsseitig
Alternative kleiner als Null
linksseitig
$H_{A}$: Der Anteil von Data Scientists, die als Kinder mit dem Programmieren starteten, ist größer als 35 %
Das ist ein rechtsseitiger Test
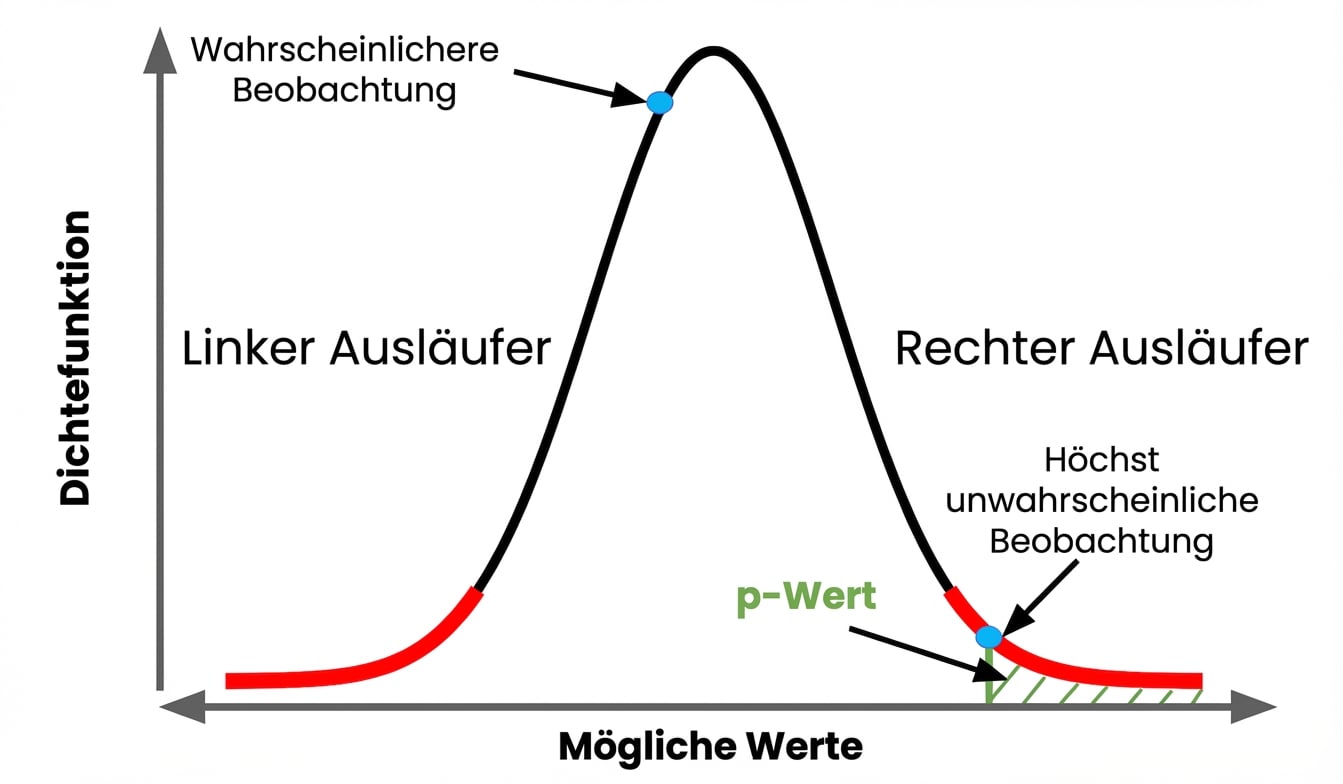
p-Werte
p-Werte: Wahrscheinlichkeit eines Ergebnisses, angenommen die Nullhypothese ist wahr
Großer p-Wert, starke Unterstützung für $H_{0}$
Statistik liegt nicht im Endbereich der Nullverteilung