Aprimorar o desempenho do modelo
Introdução ao Aprendizado Profundo com o PyTorch

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Etapas para maximizar desempenho


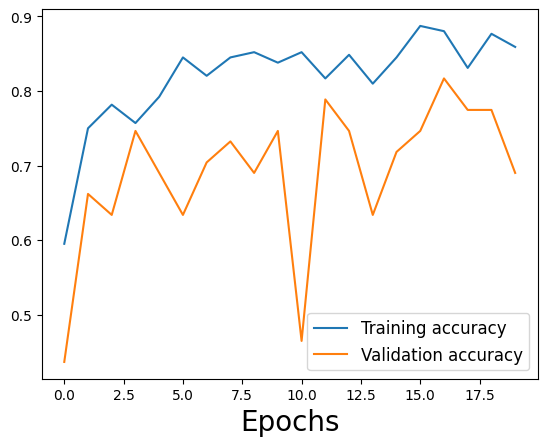
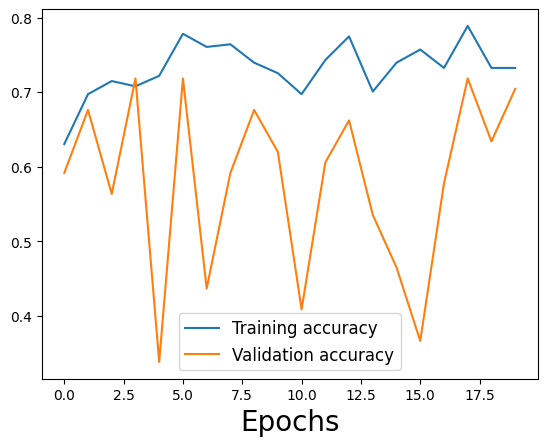
Etapa 2: reduzir o sobreajuste
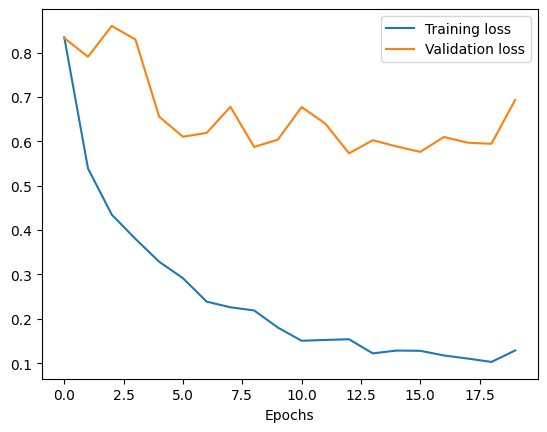
Etapa 2: reduzir o sobreajuste
$$
Modelo original sobreajusta dados de treinamento
$$
Modelo atualizado com muita regularização
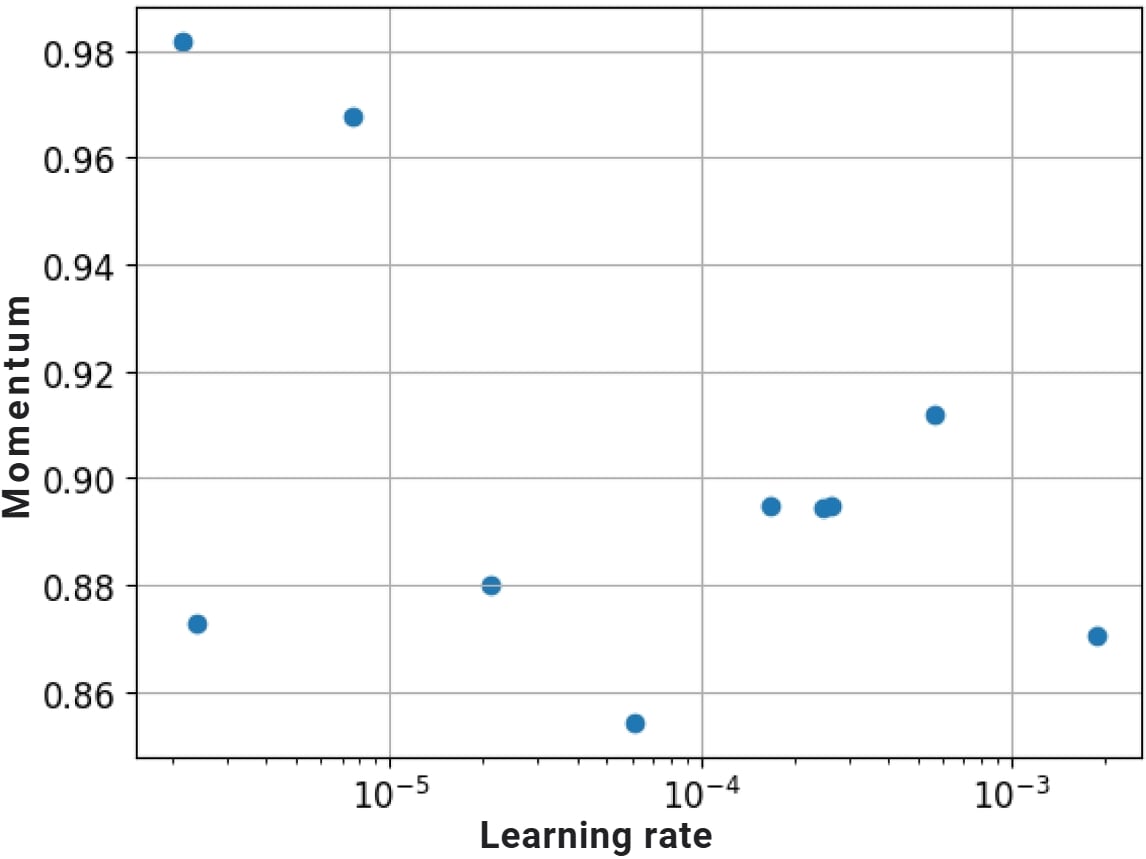
Etapa 3: ajuste fino de hiperparâmetros
- Busca em grade
for factor in range(2, 6):
lr = 10 ** -factor
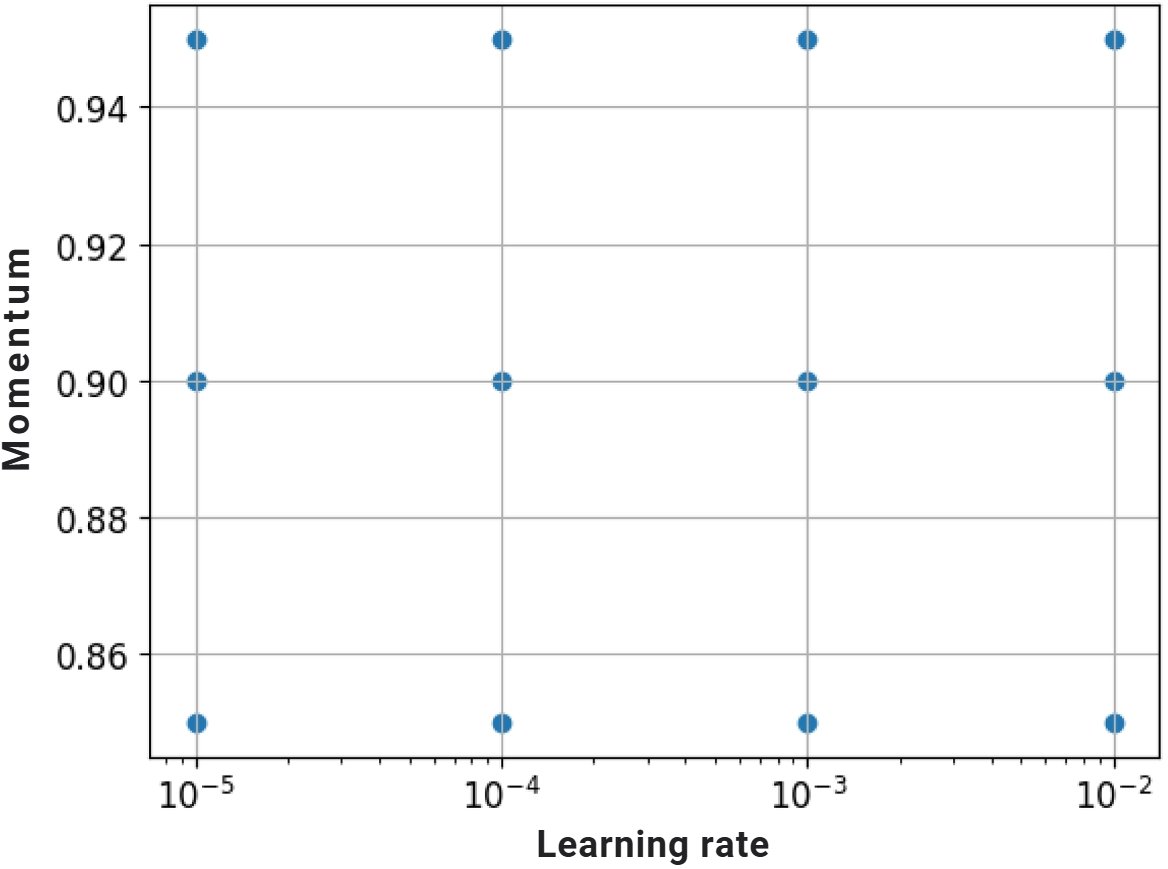
- Busca aleatória
factor = np.random.uniform(2, 6)
lr = 10 ** -factor