Taxa de aprendizado e momentum
Introdução ao Aprendizado Profundo com o PyTorch

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
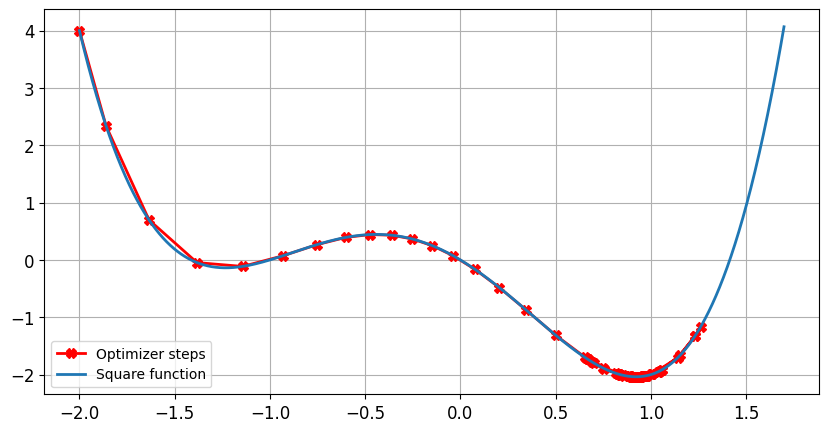
Impacto da taxa de aprendizado: taxa de aprendizado ideal

- Tamanho da etapa diminui perto de zero, conforme o gradiente fica menor
Impacto da taxa de aprendizado: taxa de aprendizado pequena

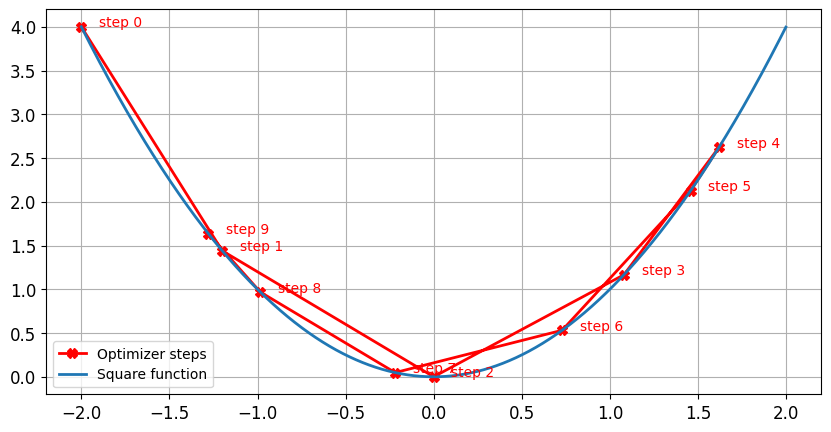
Impacto da taxa de aprendizado: alta taxa de aprendizado
Funções convexas e não convexas
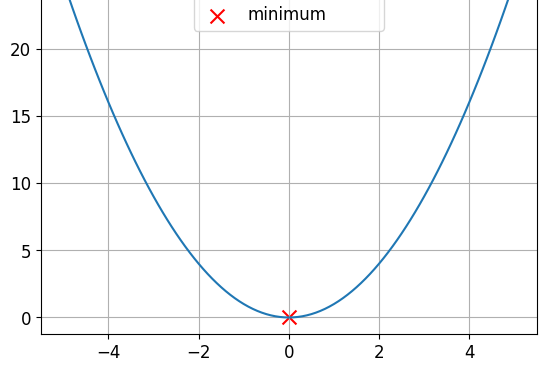
Essa é uma função convexa.
Essa é uma função não convexa.
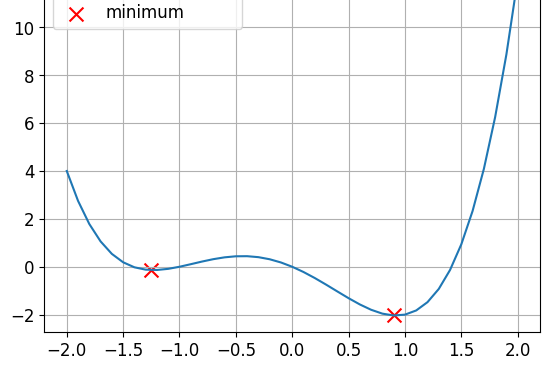
- Funções de perda não são convexas
Sem momentum
lr = 0.01momentum = 0, após 100 etapas o mínimo encontrado parax = -1.23ey = -0.14
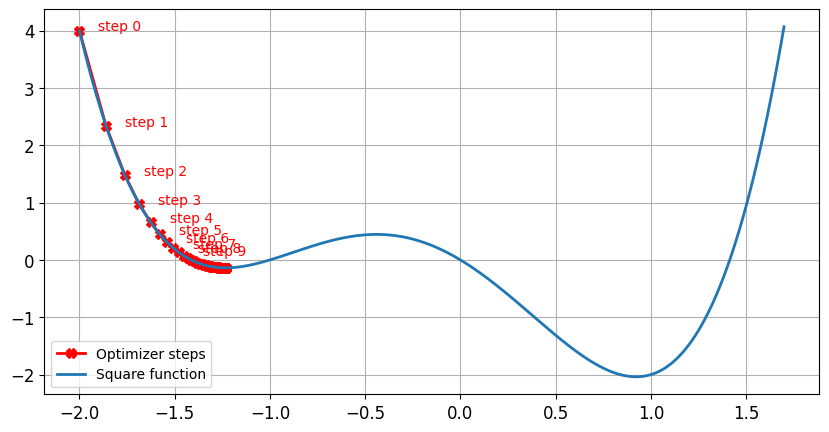
Com momentum
lr = 0.01momentum = 0.9, após 100 etapas o mínimo encontrado parax = 0.92ey = -2.04