Limitações da correlação
Introdução à estatística em Python

Maggie Matsui
Content Developer, DataCamp
Relações não lineares
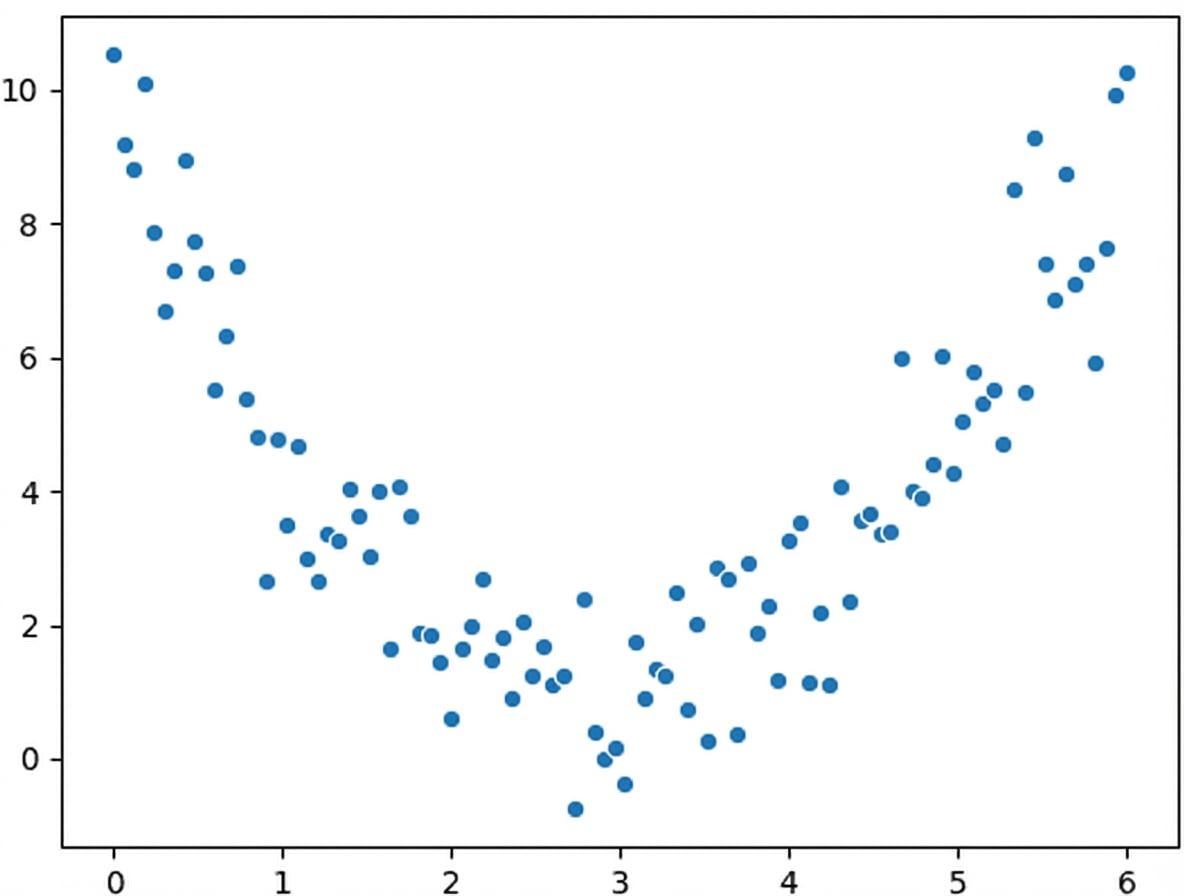
$$r = 0.18$$
Relações não lineares
O que vemos:
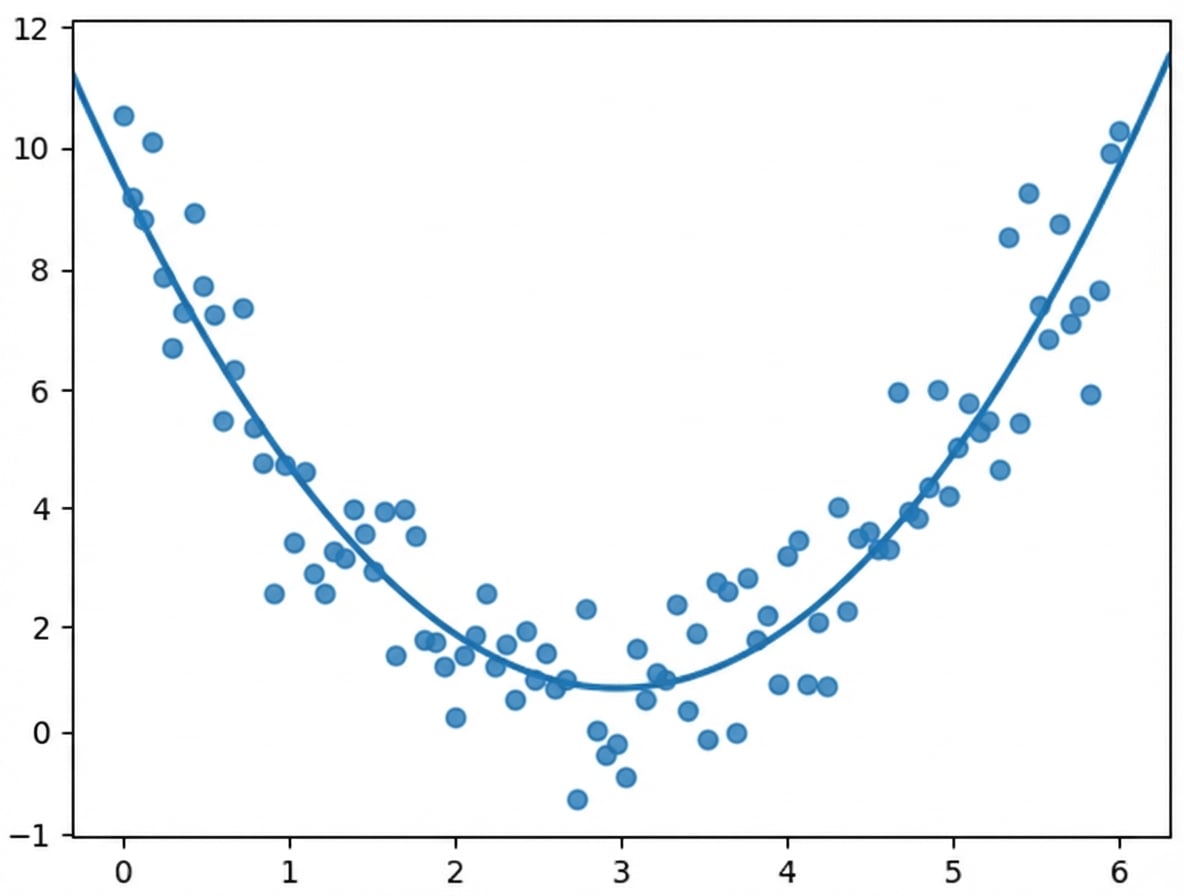
O que o coeficiente de correlação vê:
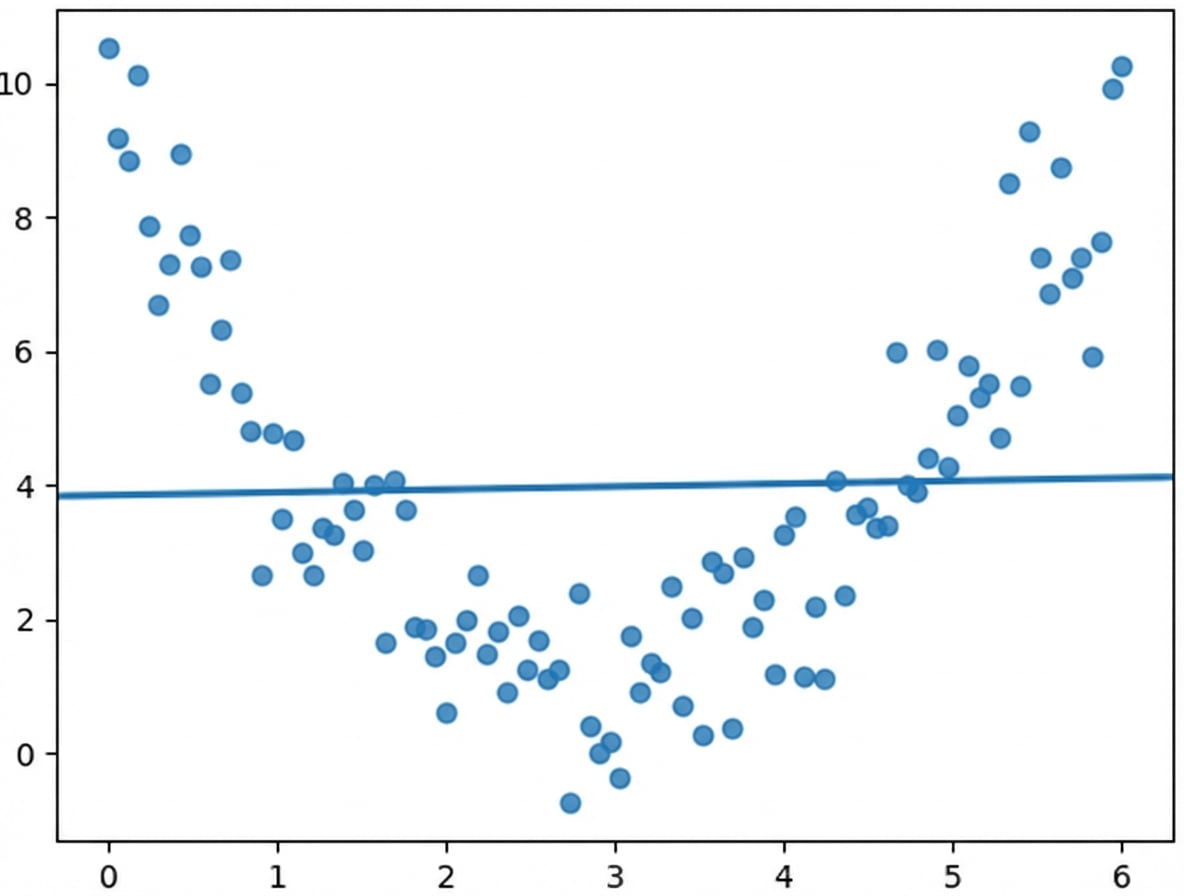
A correlação só leva em conta as relações lineares
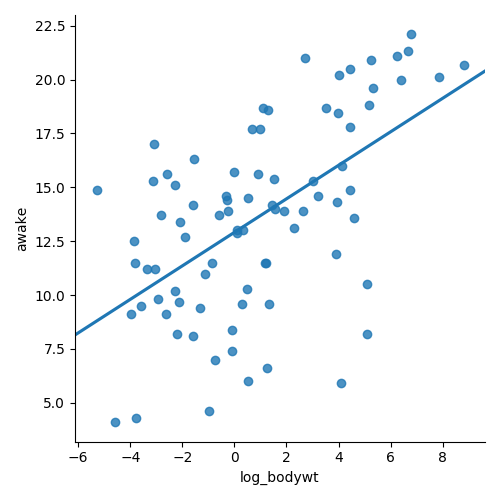
Sempre visualize seus dados
Peso corporal vs. tempo acordado
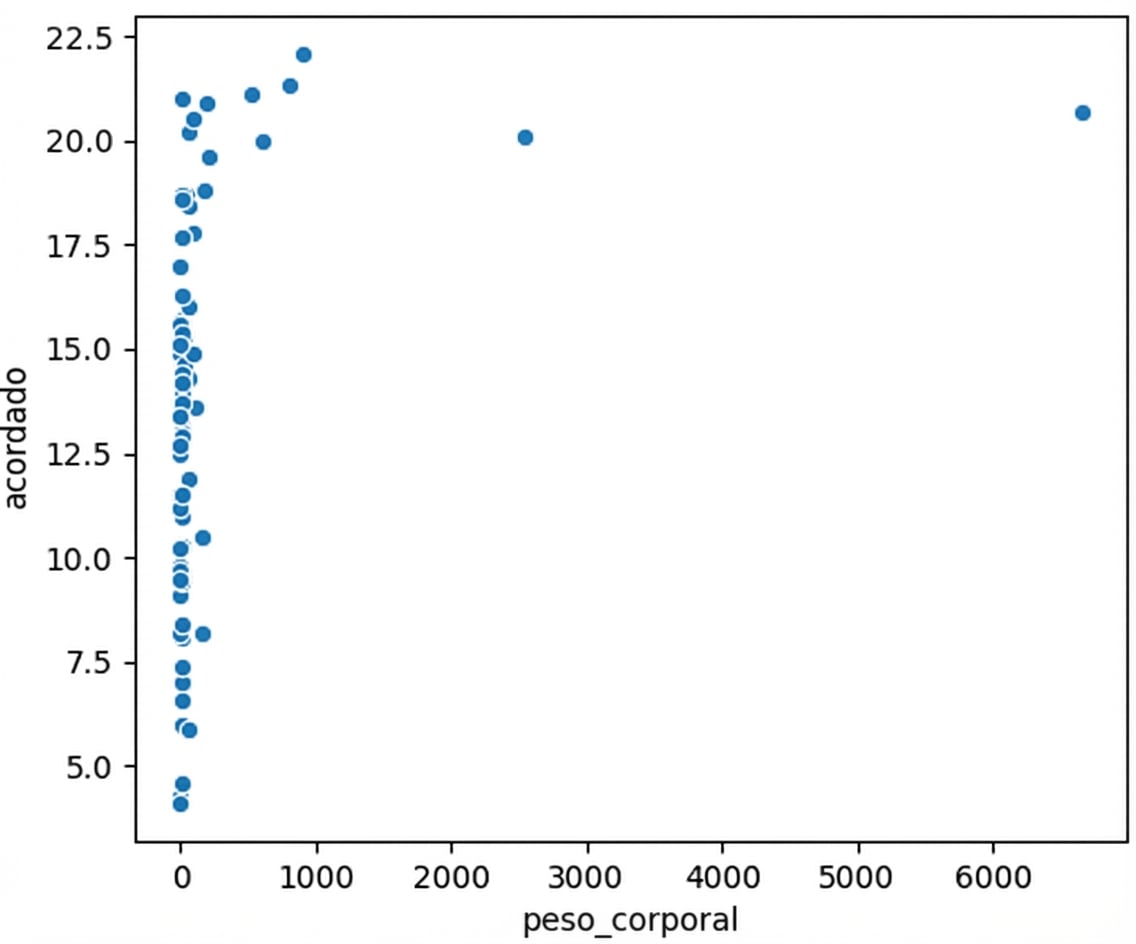
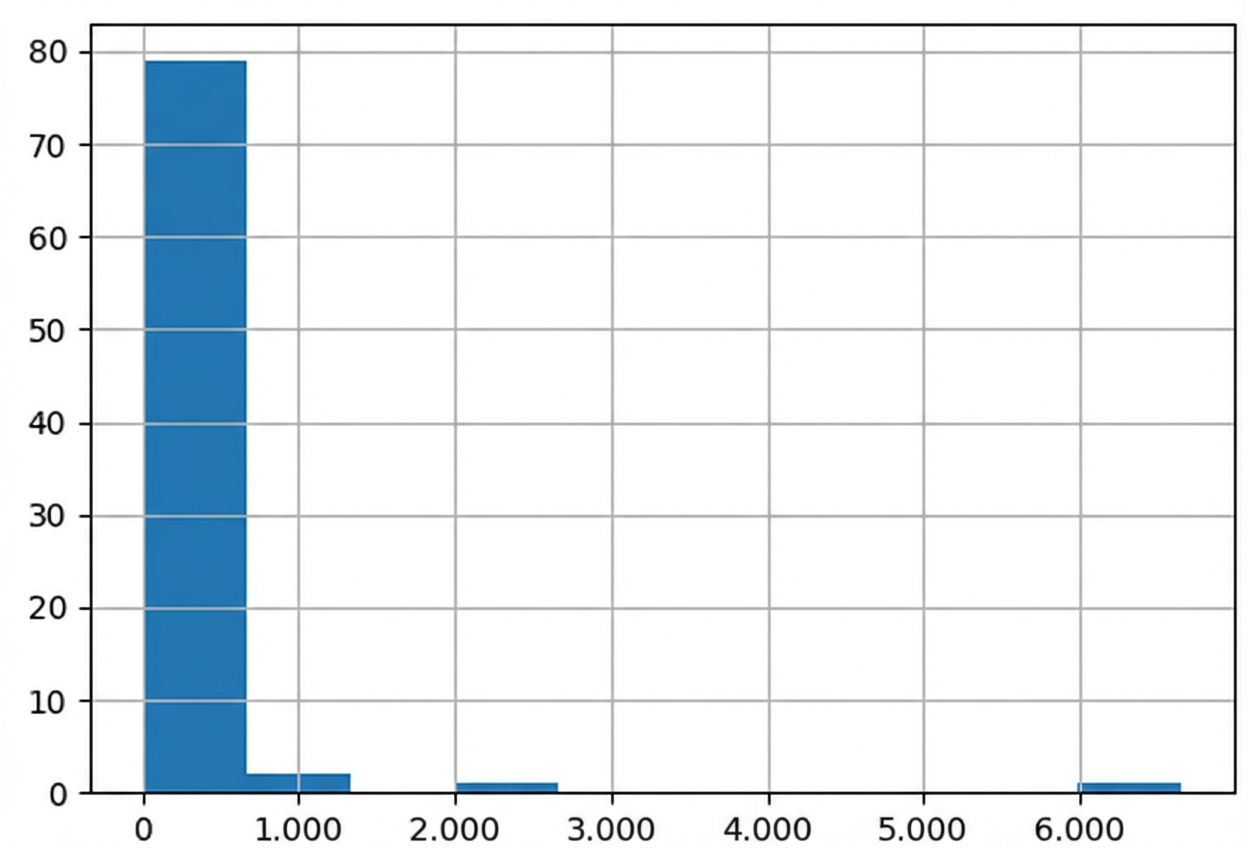
Distribuição de peso corporal
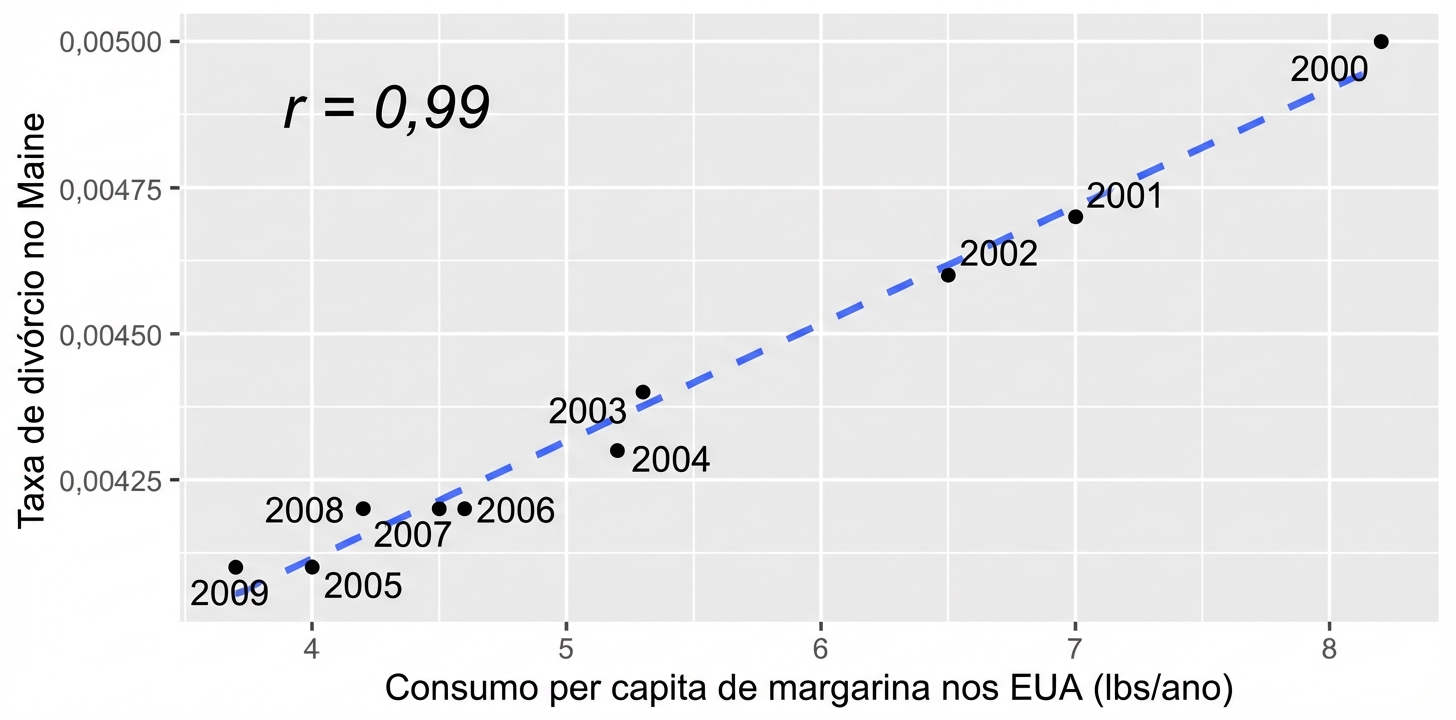
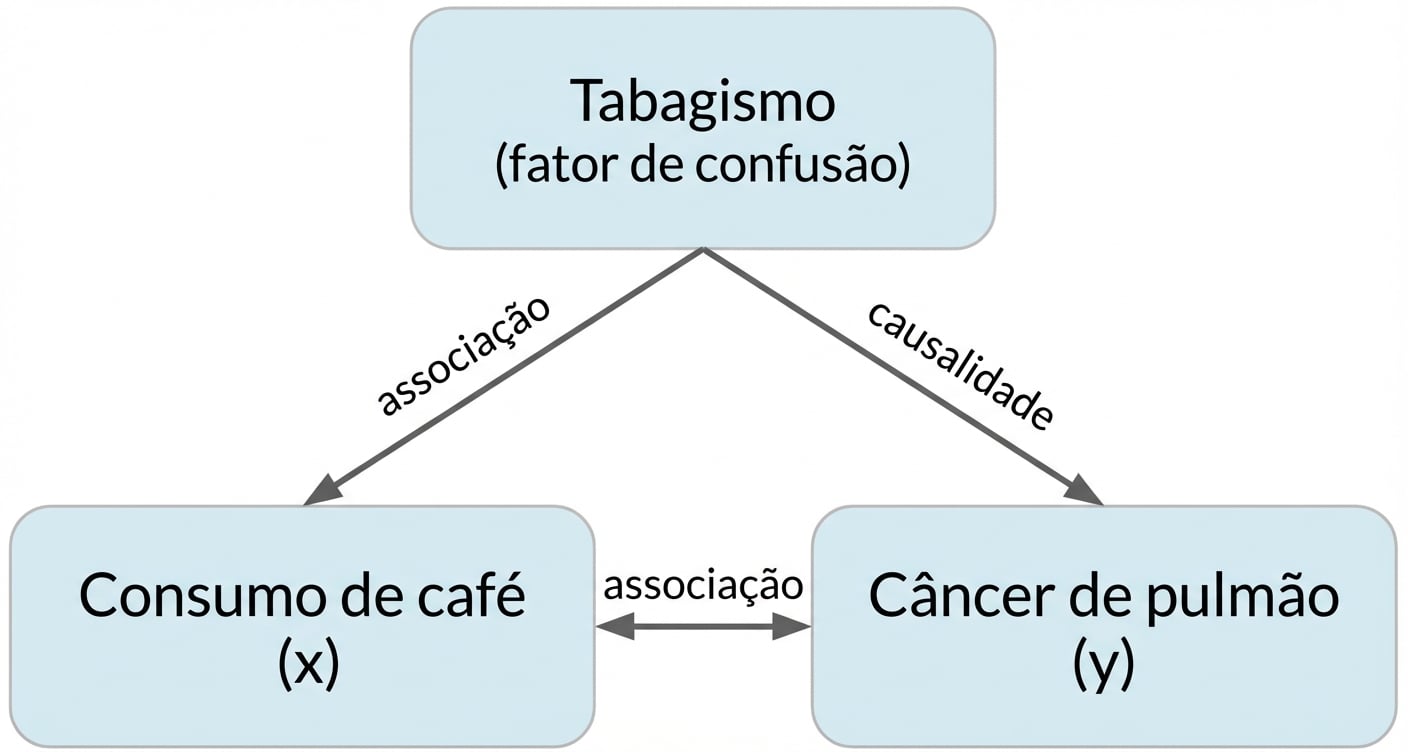
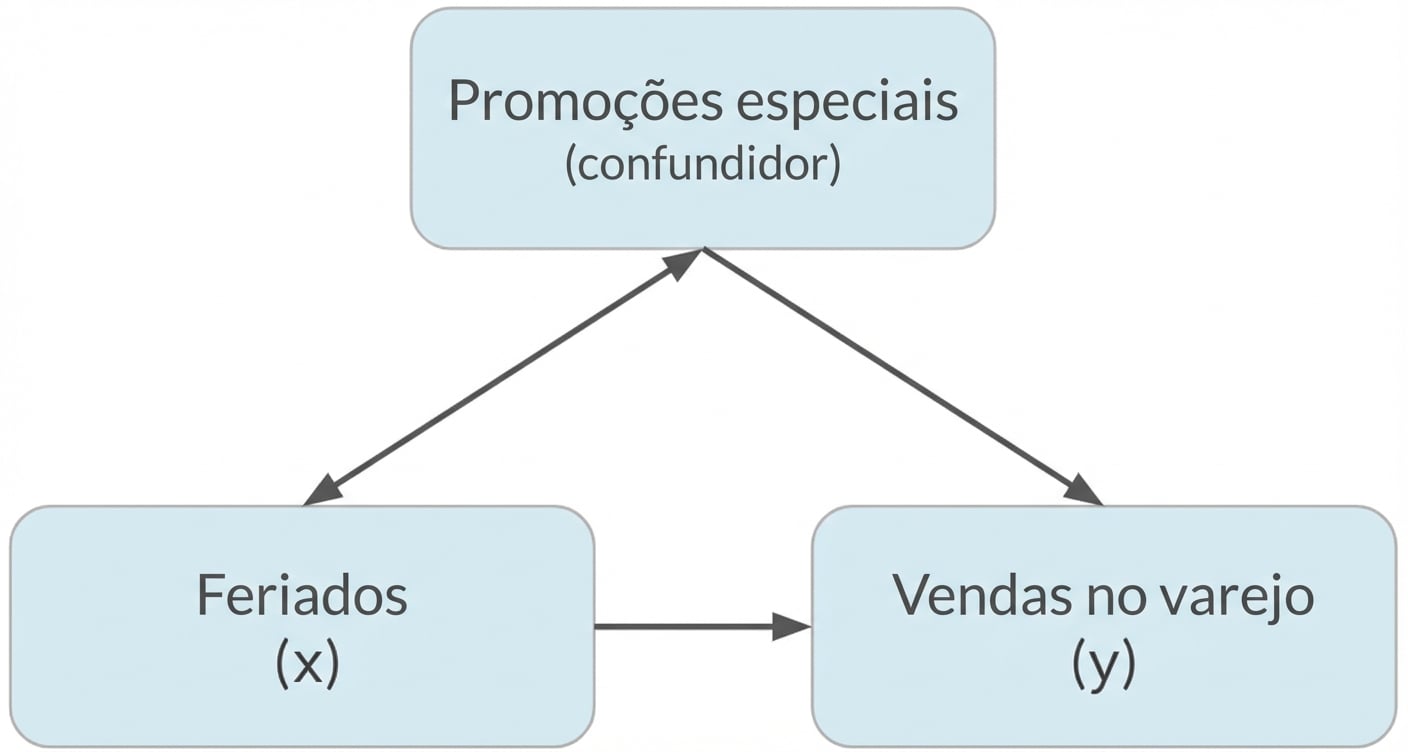
Correlação não implica causalidade
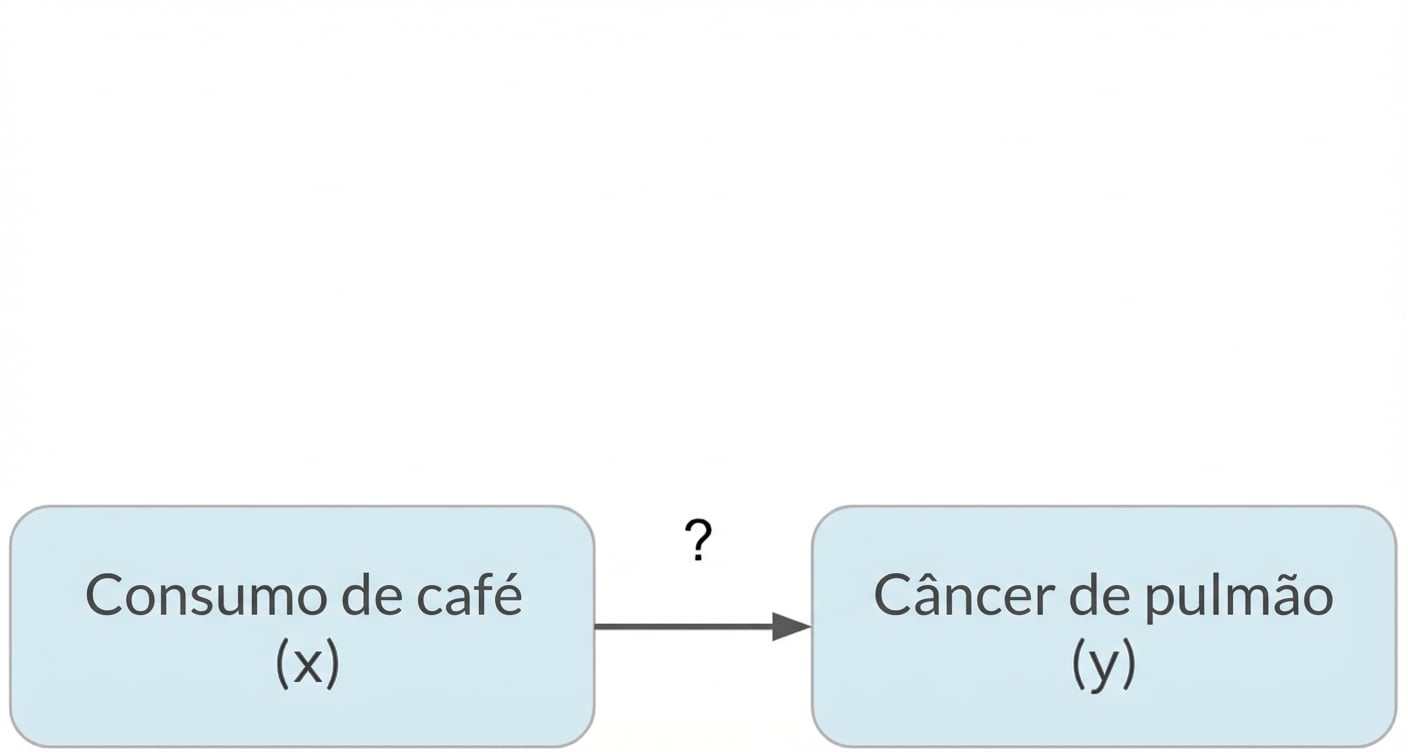
x estar correlacionado com y não significa que x causa y
Fator de confusão
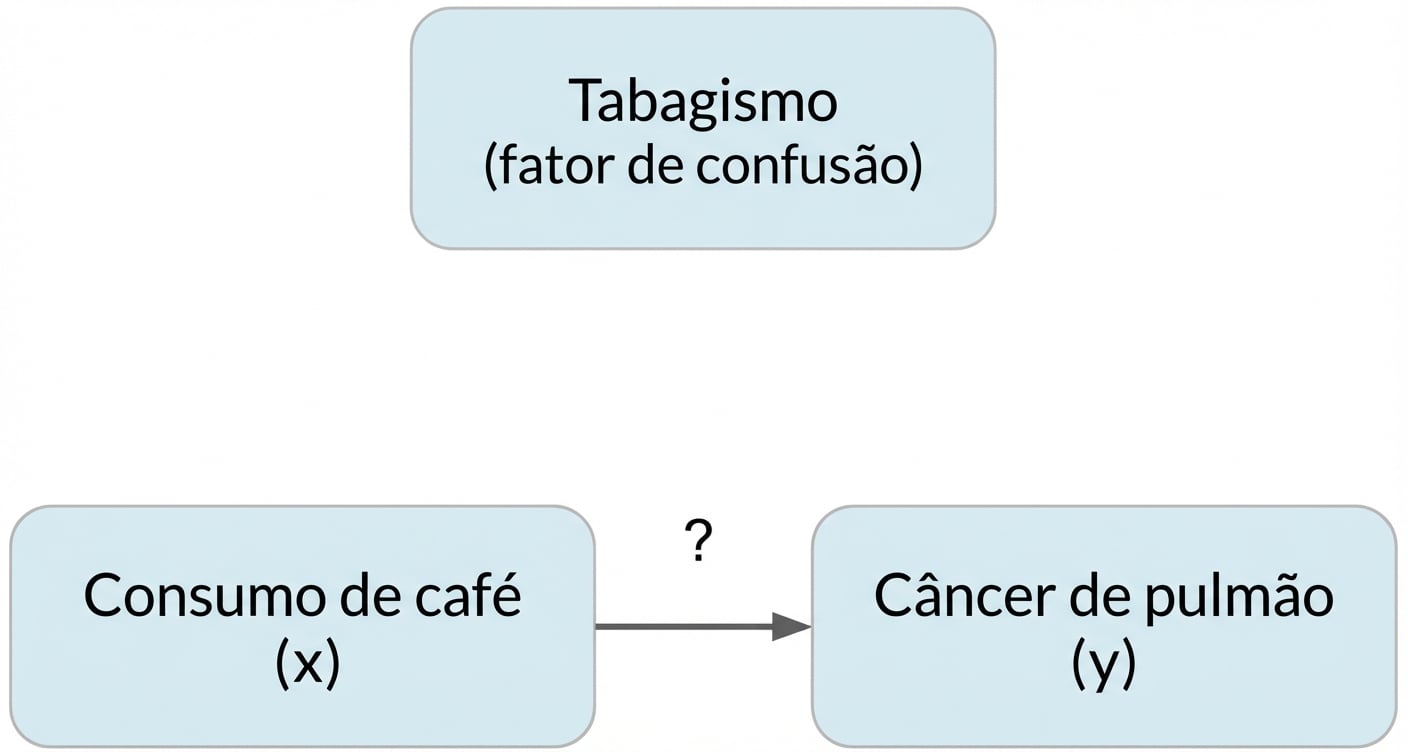
Fator de confusão
Fator de confusão
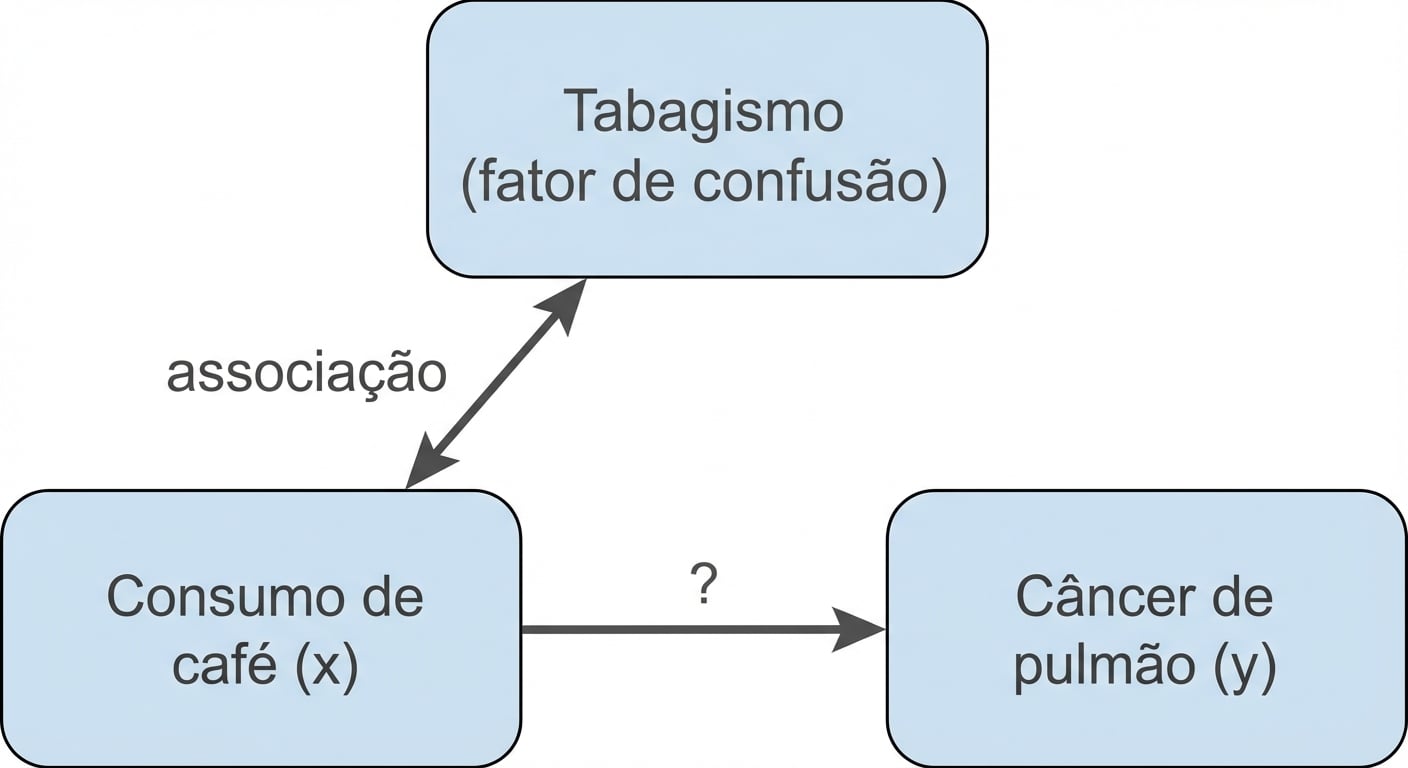
Fator de confusão
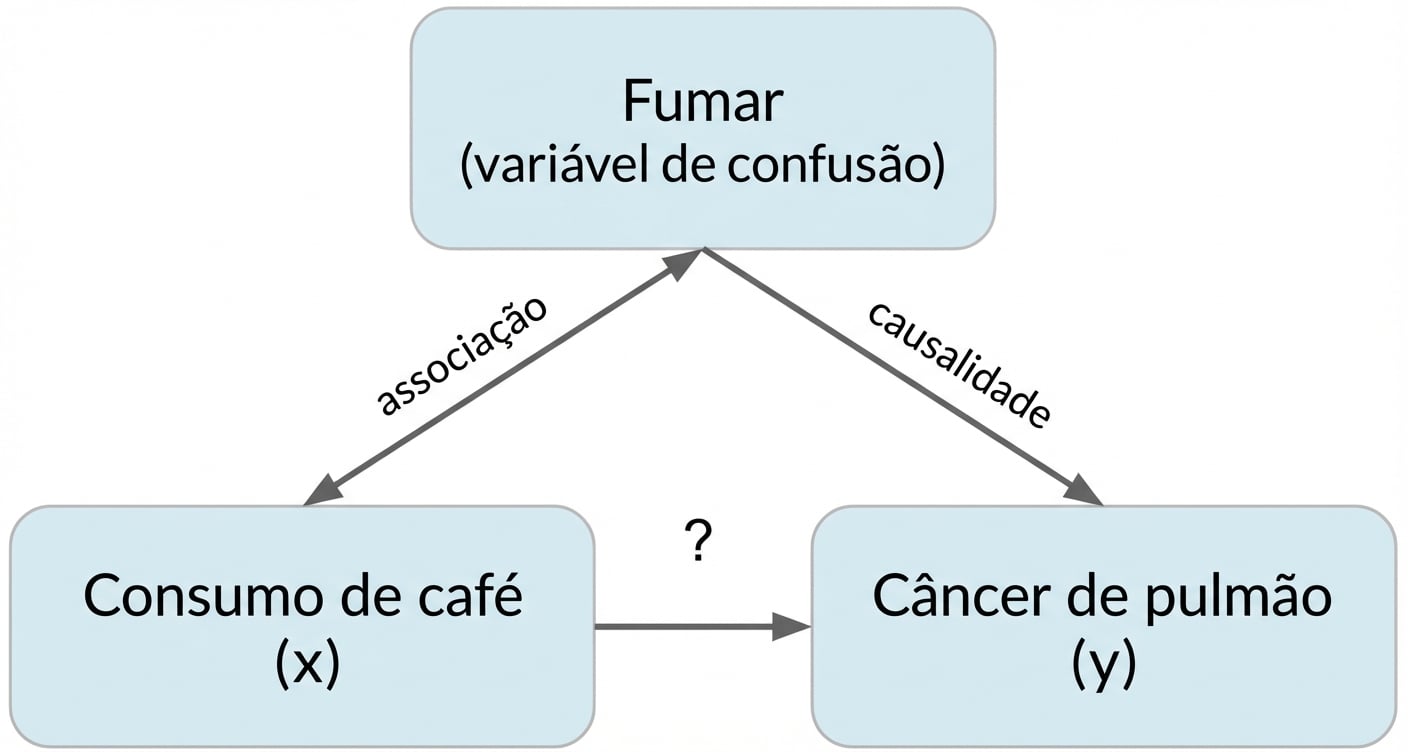
Fator de confusão


{kind=link}