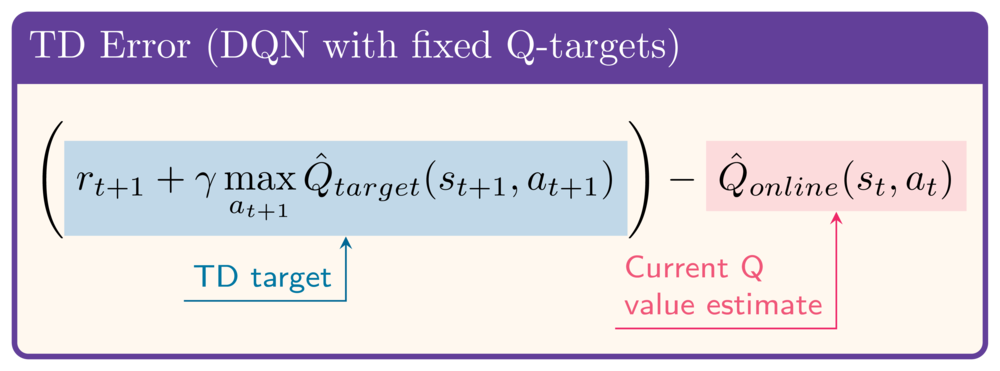
Double DQN
Deep Reinforcement Learning in Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
Double Q-learning
- Q-learning overestimates Q-values, compromising learning efficiency
- This is due to maximization bias
- Double Q-Learning eliminates bias by decoupling action selection and value estimation
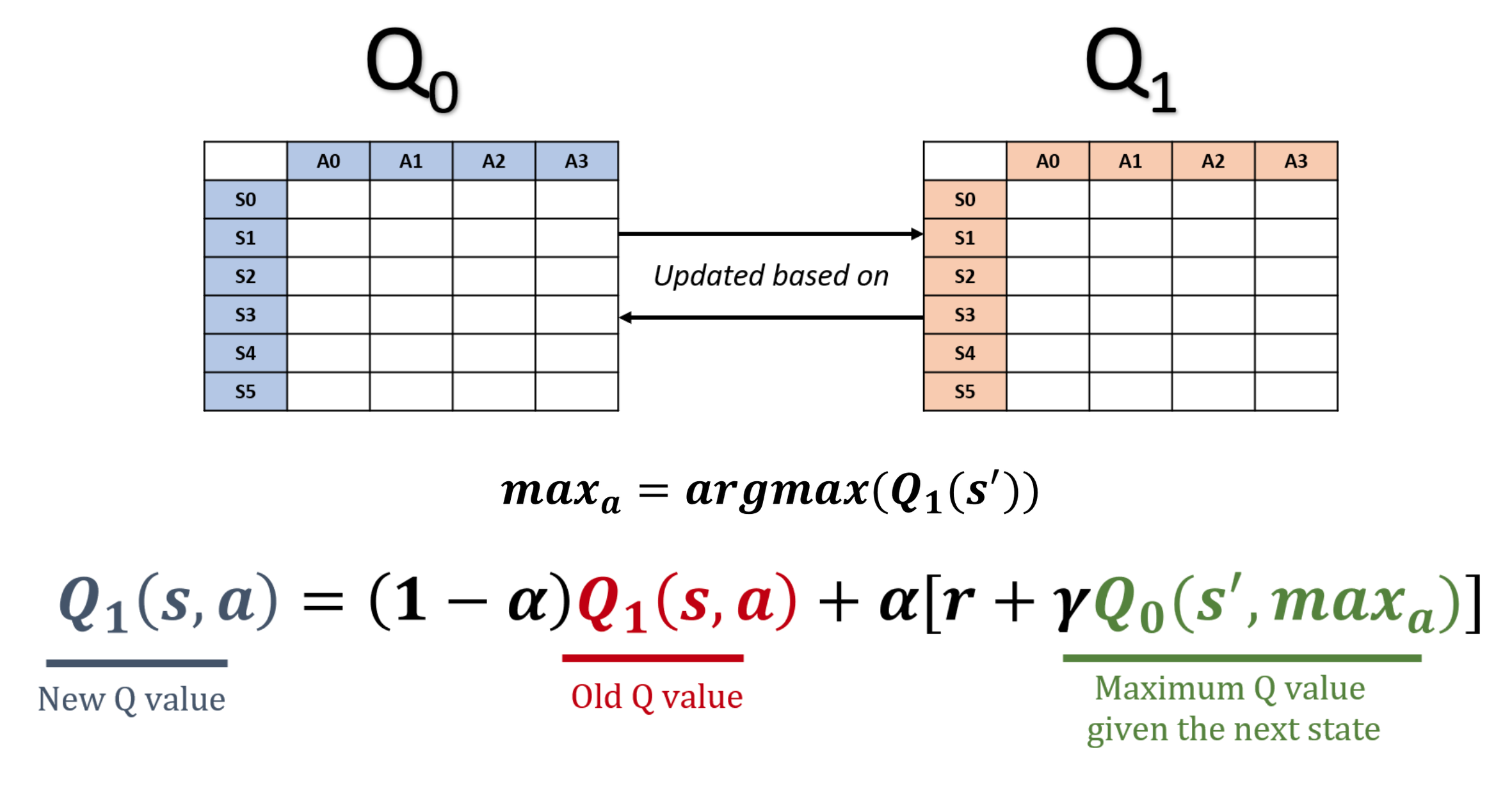
The idea behind DDQN

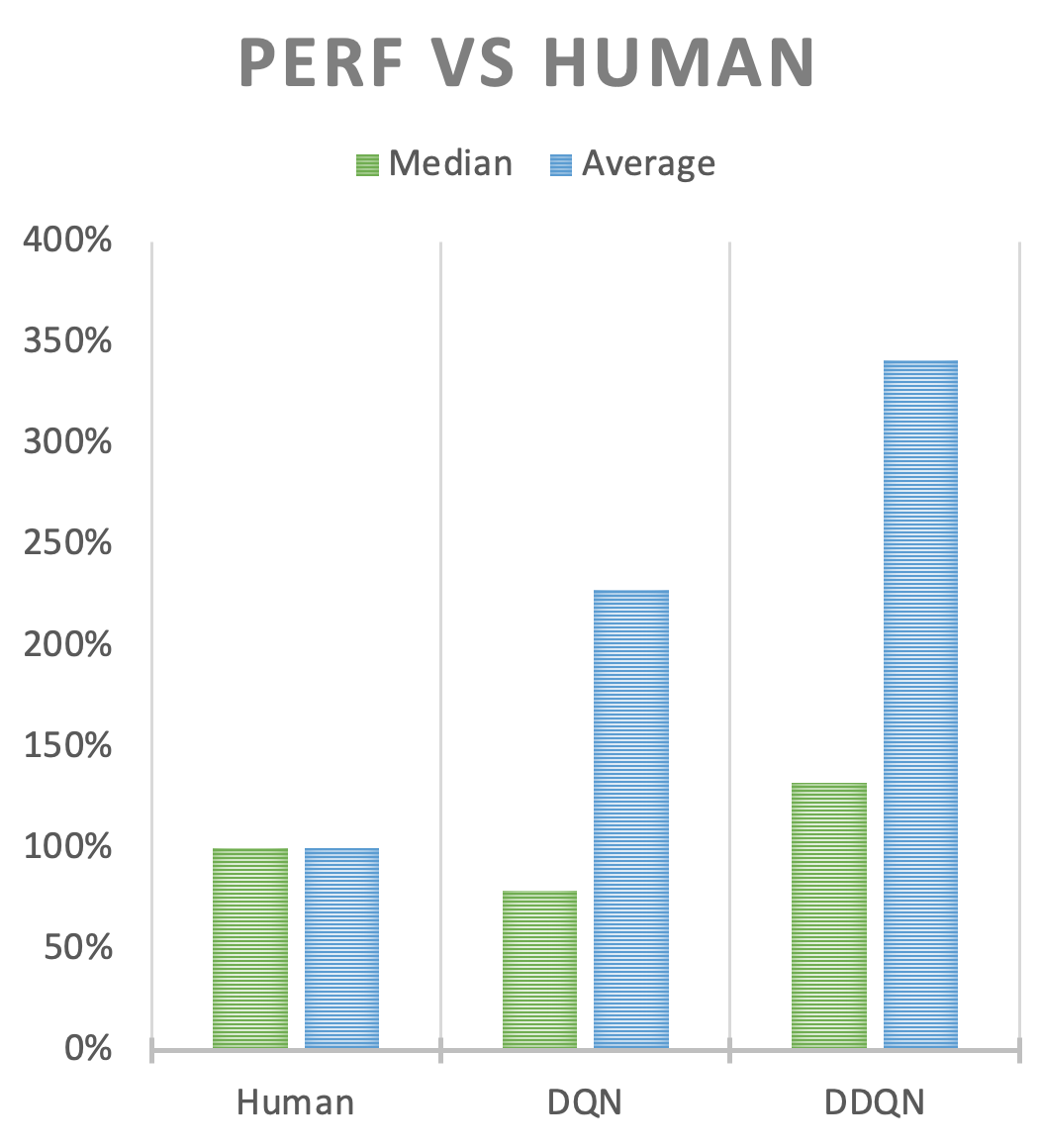
DDQN performance
1 https://arxiv.org/abs/2303.11634

