Entropy bonus and PPO
Deep Reinforcement Learning in Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
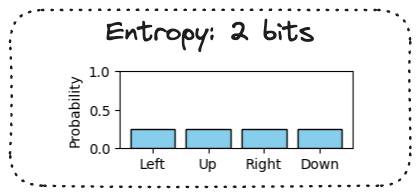
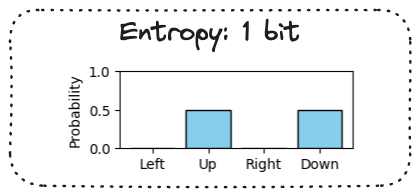
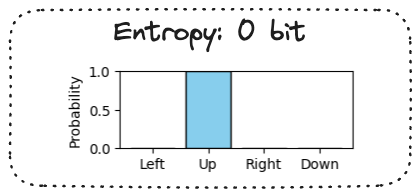
Entropy bonus

Entropy of a probability distribution

- If $\ln$ instead of $\log_2$: result measured in $nats$.
- $1\ nat = \frac{1}{\ln 2}\ bit \approx 1.44 \ bit$