Introduction to policy gradient
Deep Reinforcement Learning in Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
Introduction to Policy methods in DRL
Q-learning:
- Learn the action value function Q
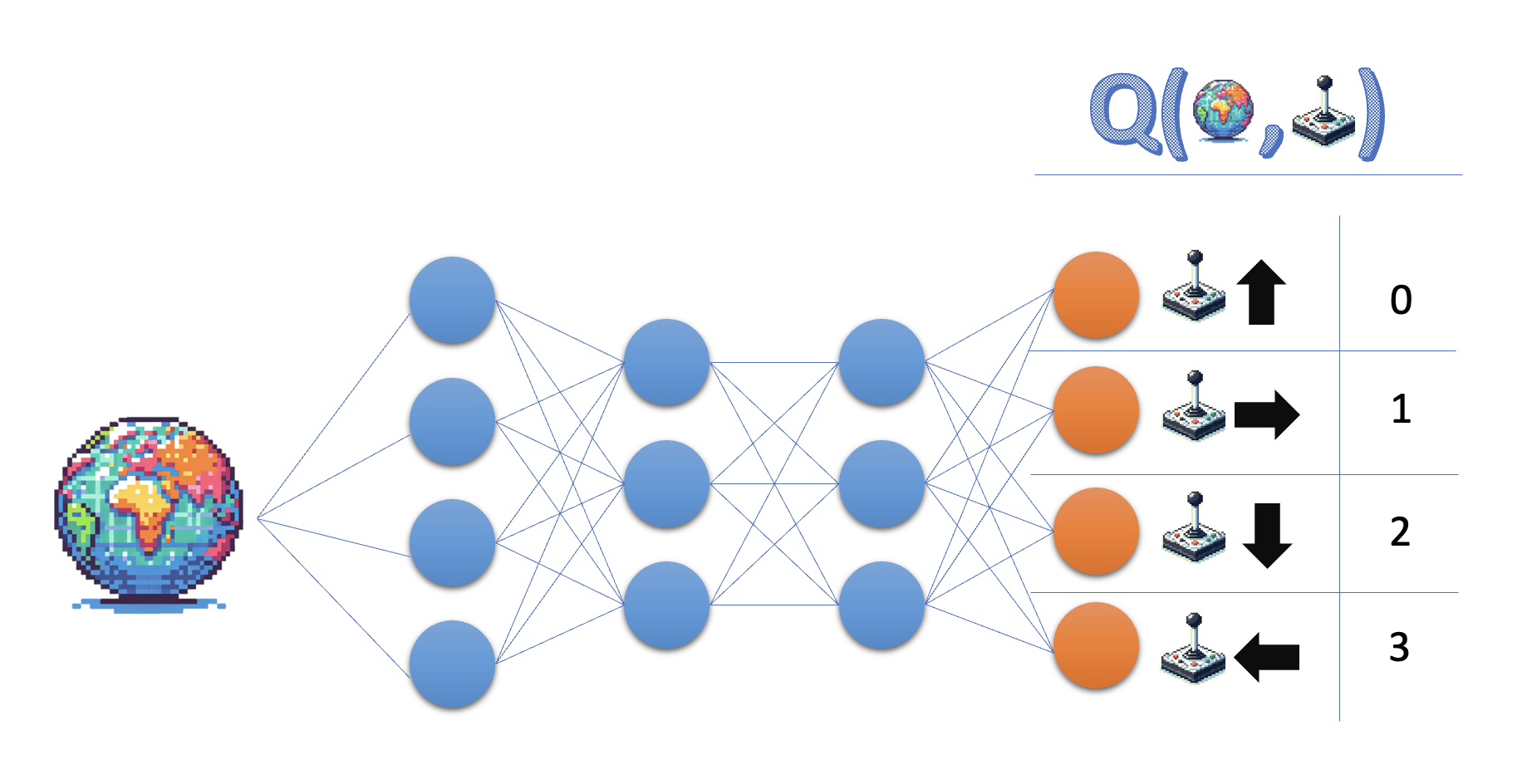
- Policy: select action with highest value
Policy learning:
- Learn the policy directly
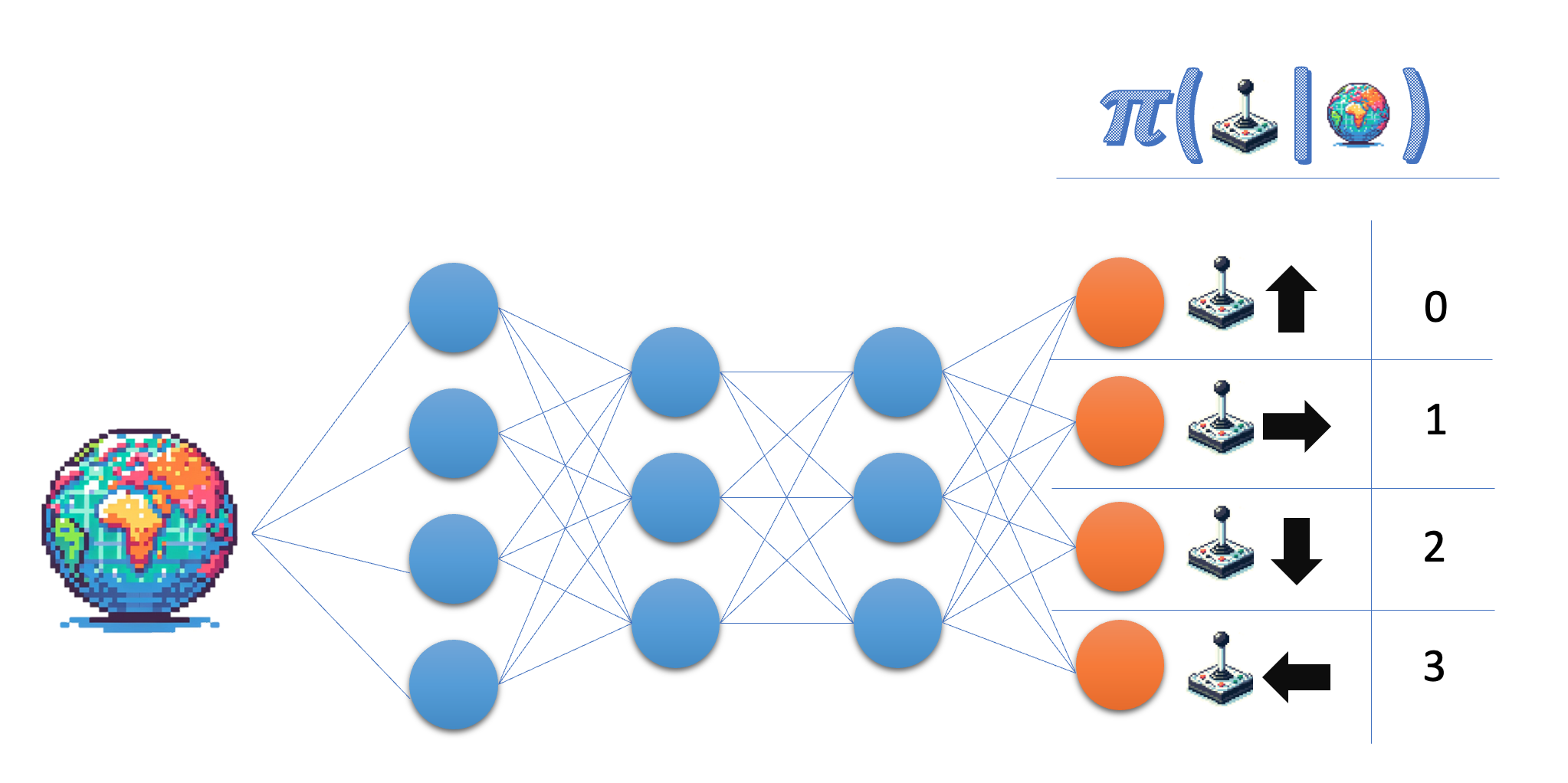
The policy network (discrete actions)
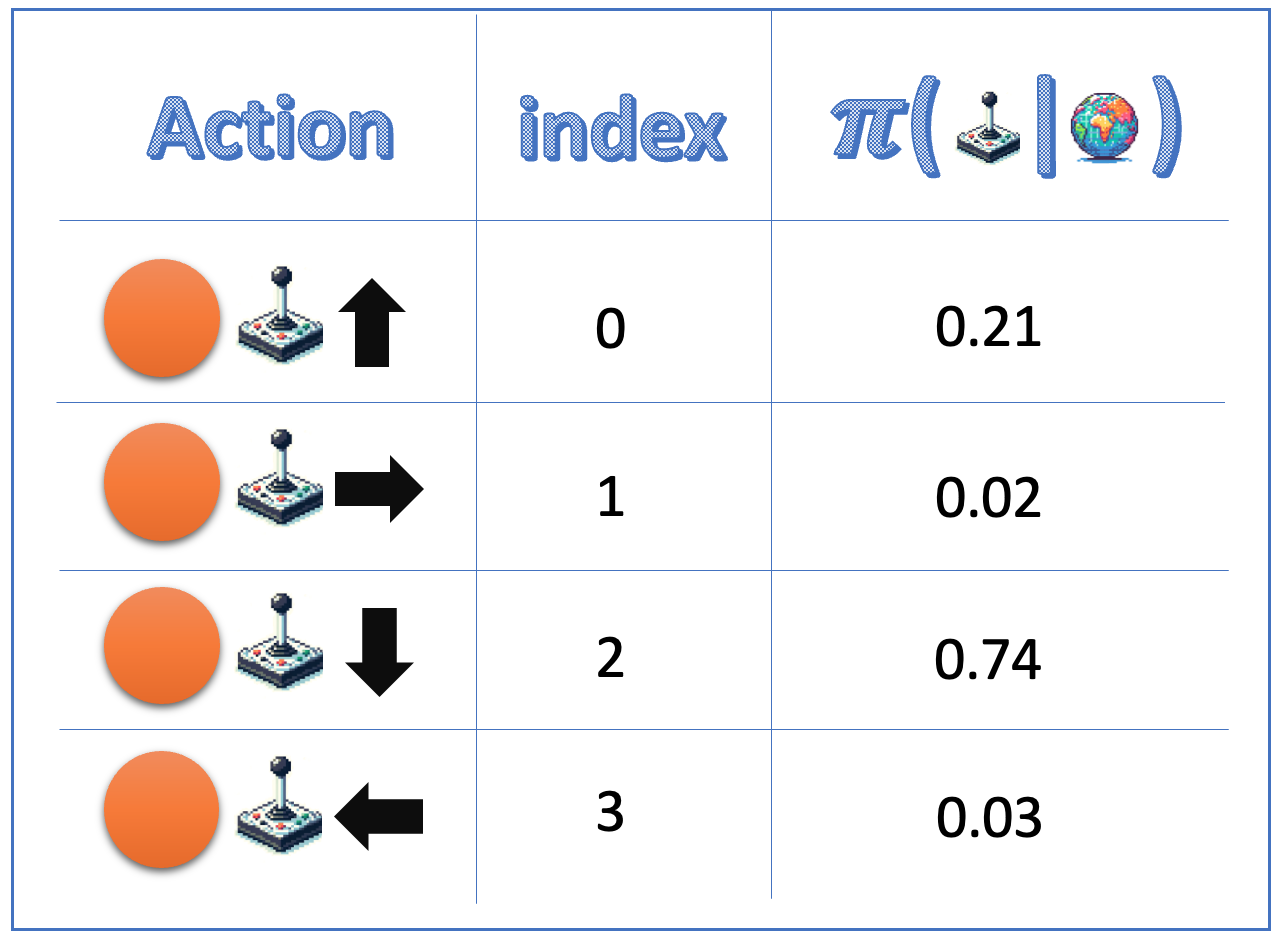
action_dist = ( torch.distributions.Categorical(action_probs))action = action_dist.sample()
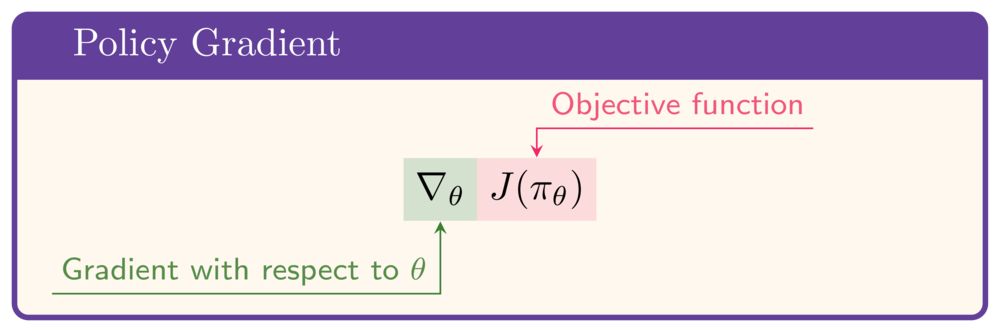
The objective function
Policy must maximize expected returns
- Assuming the agent follows $\pi_\theta$
- By optimizing policy parameter $\theta$
Objective function:

- To maximize $J$: need gradient with respect to $\theta$:
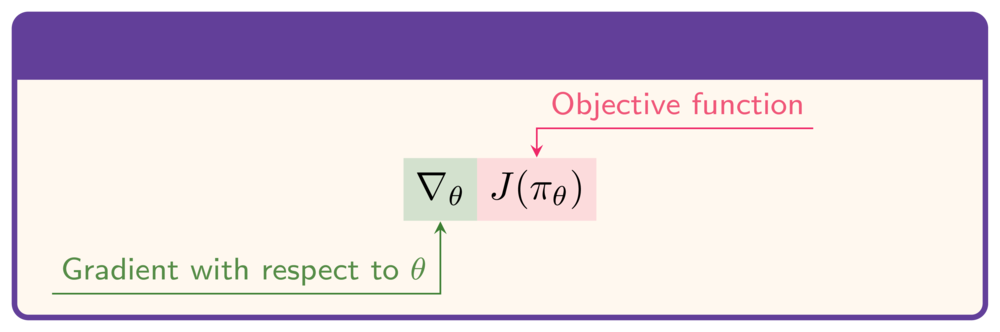
The objective function
Policy must maximize expected returns
- Assuming the agent follows $\pi_\theta$
- By optimizing policy parameter $\theta$
Objective function:
- To maximize $J$: need gradient with respect to $\theta$:
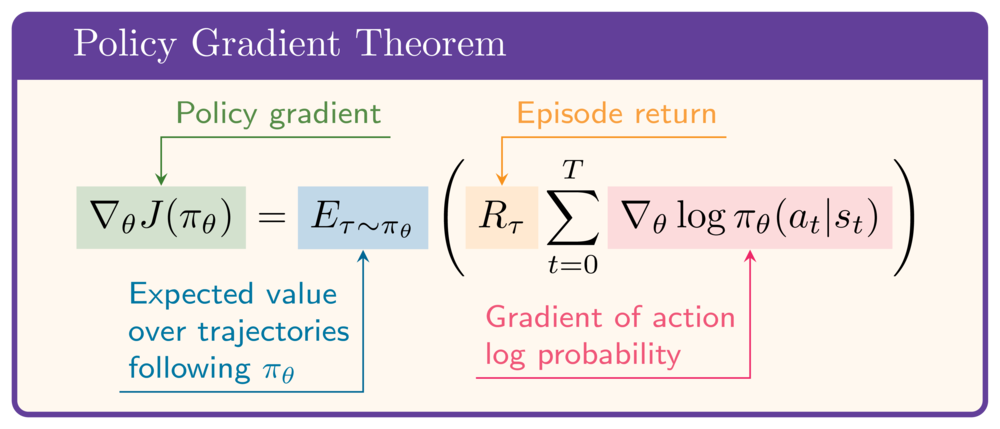
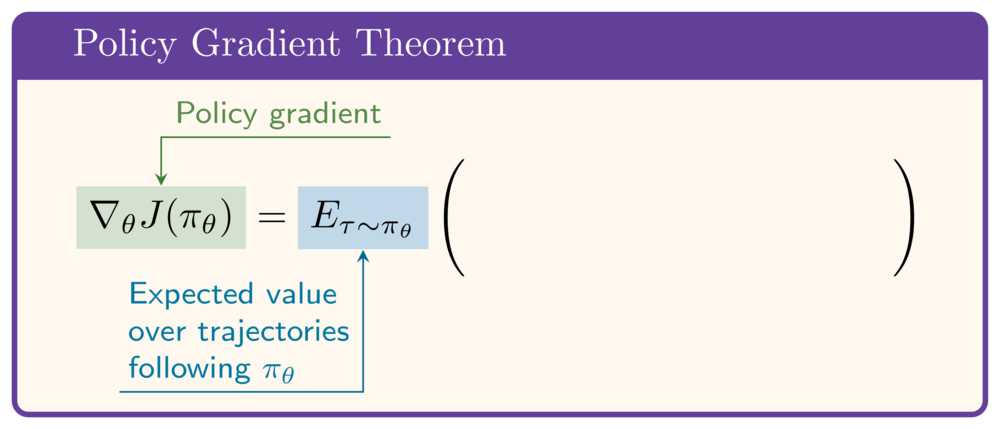
The policy gradient theorem
The policy gradient theorem
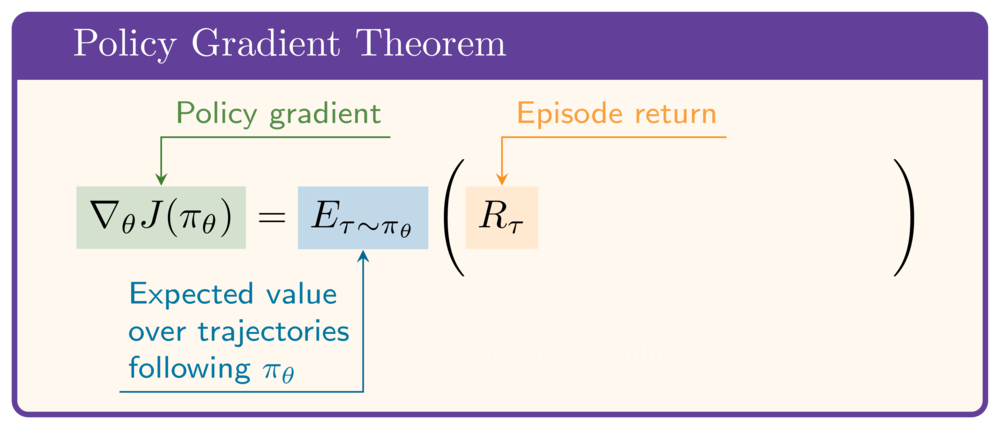
The policy gradient theorem