Proximal policy optimization
Deep Reinforcement Learning in Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
A2C
- A2C policy updates:
- Based on volatile estimates
- Can be large and unstable
- May harm performance

PPO
- PPO sets limits on the size of each policy update
- Improves stability

The probability ratio
- PPO main innovation: a new objective function
- At its core:

- How much more likely is action $a_t$ with $\theta$ than with $\theta_{old}$?
Clipping the probability ratio
- Clip function:
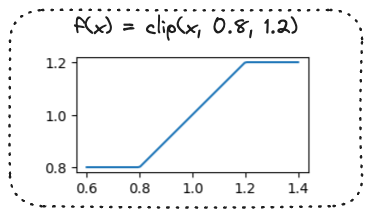
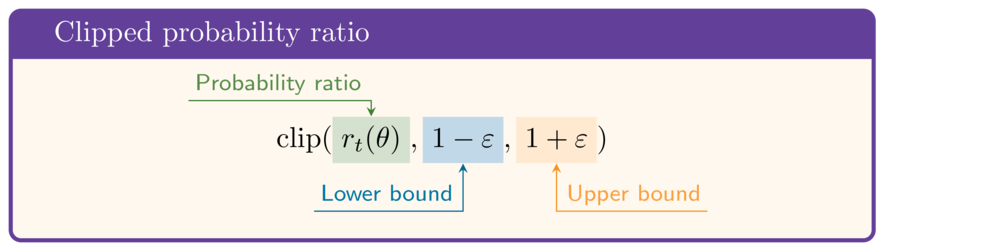
The PPO objective function

surr1 = ratio * td_error.detach()surr2 = clipped_ratio * td_error.detach()objective = torch.min(surr1, surr2)
- Surrogate with clipped ratio:
$$\mathrm{clip}(r_t(\theta),1-\varepsilon,1+\varepsilon)\hat{A}$$
- PPO clipped surrogate objective function:

- More stable than A2C

