Continuing the infer pipeline
Hypothesis Testing in R

Richie Cotton
Data Evangelist at DataCamp
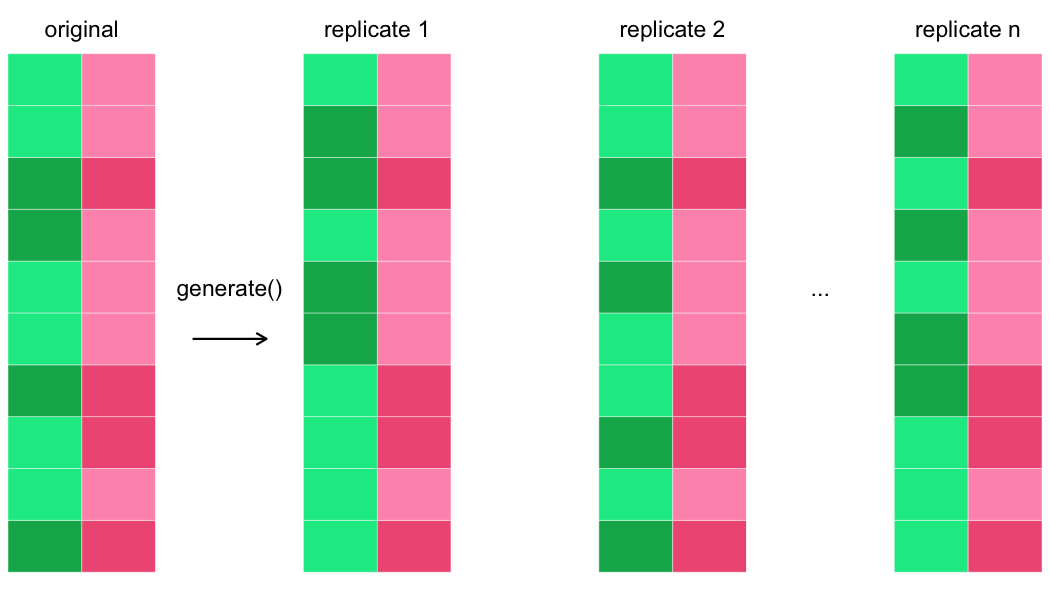
Generating many replicates
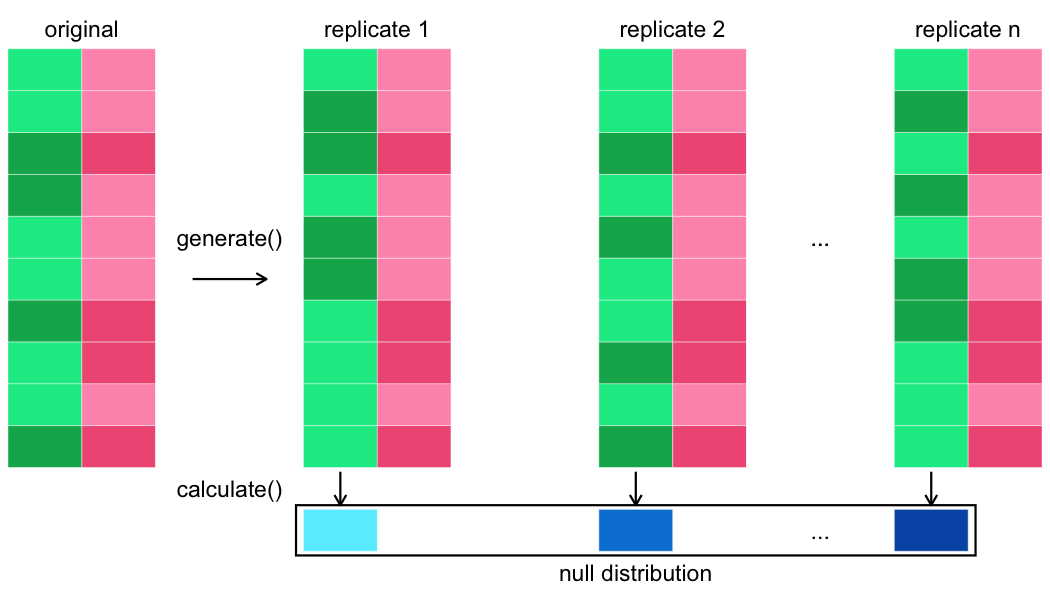
Calculating the test statistic
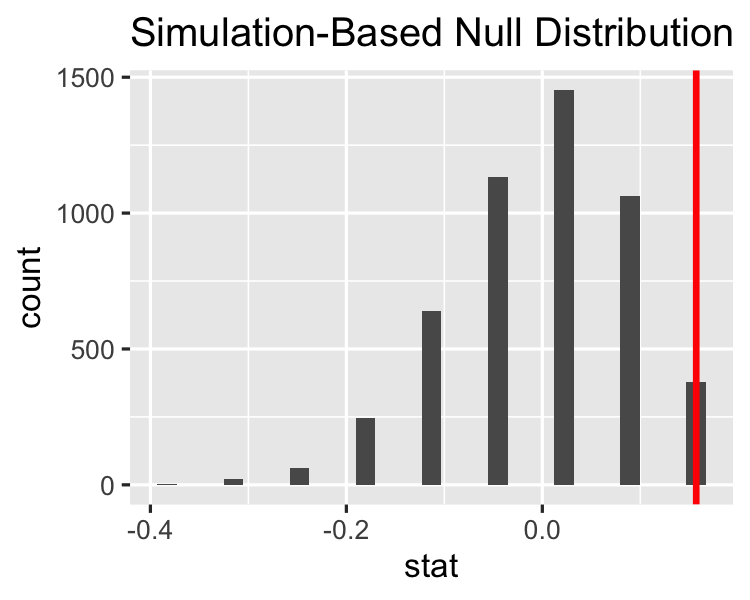
Visualizing the null distribution
visualize(null_distn)
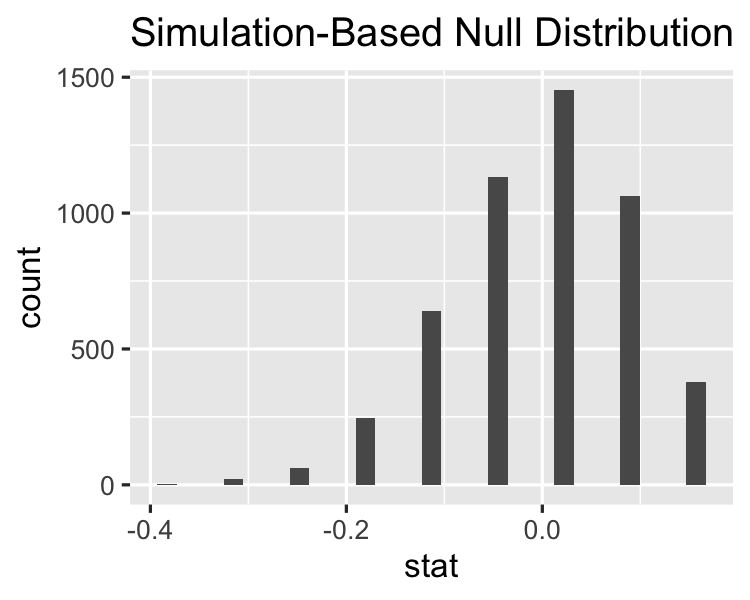
Calculating the test statistic on the original dataset
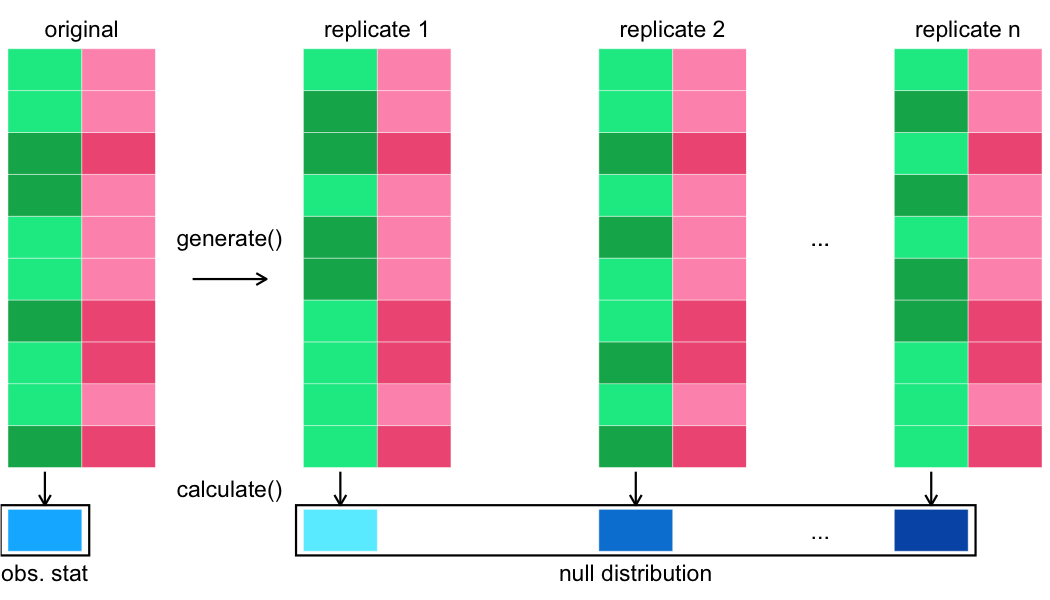
Visualizing the null distribution vs the observed stat