Regex metacharacters
Regular Expressions in Python

Maria Eugenia Inzaugarat
Data Scientist
Looking for patterns
Two different operations to find a match:
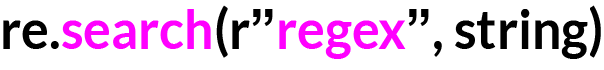
re.search(r"\d{4}", "4506 people attend the show")
<re.Match object; span=(0, 4), match='4506'>
re.search(r"\d+", "Yesterday, I saw 3 shows")
<re.Match object; span=(17, 18), match='3'>

re.match(r"\d{4}", "4506 people attend the show")
<re.Match object; span=(0, 4), match='4506'>
re.match(r"\d+","Yesterday, I saw 3 shows")
None
Special characters
- Match any character (except newline):
.

my_links = "Just check out this link: www.amazingpics.com. It has amazing photos!"re.findall(r"www com", my_links)
Special characters
- Match any character (except newline):
.

my_links = "Just check out this link: www.amazingpics.com. It has amazing photos!"re.findall(r"www.+com", my_links)
['www.amazingpics.com']

