Gerando pares
Limpeza de dados em Python

Adel Nehme
VP of AI Curriculum, DataCamp
Motivação
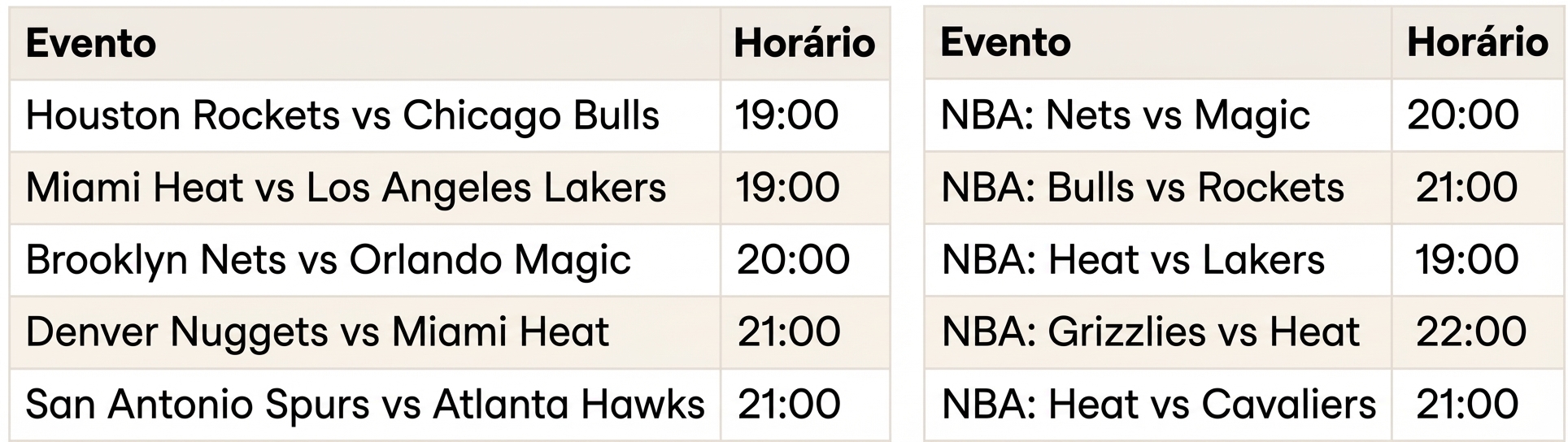
Quando joins não funcionam
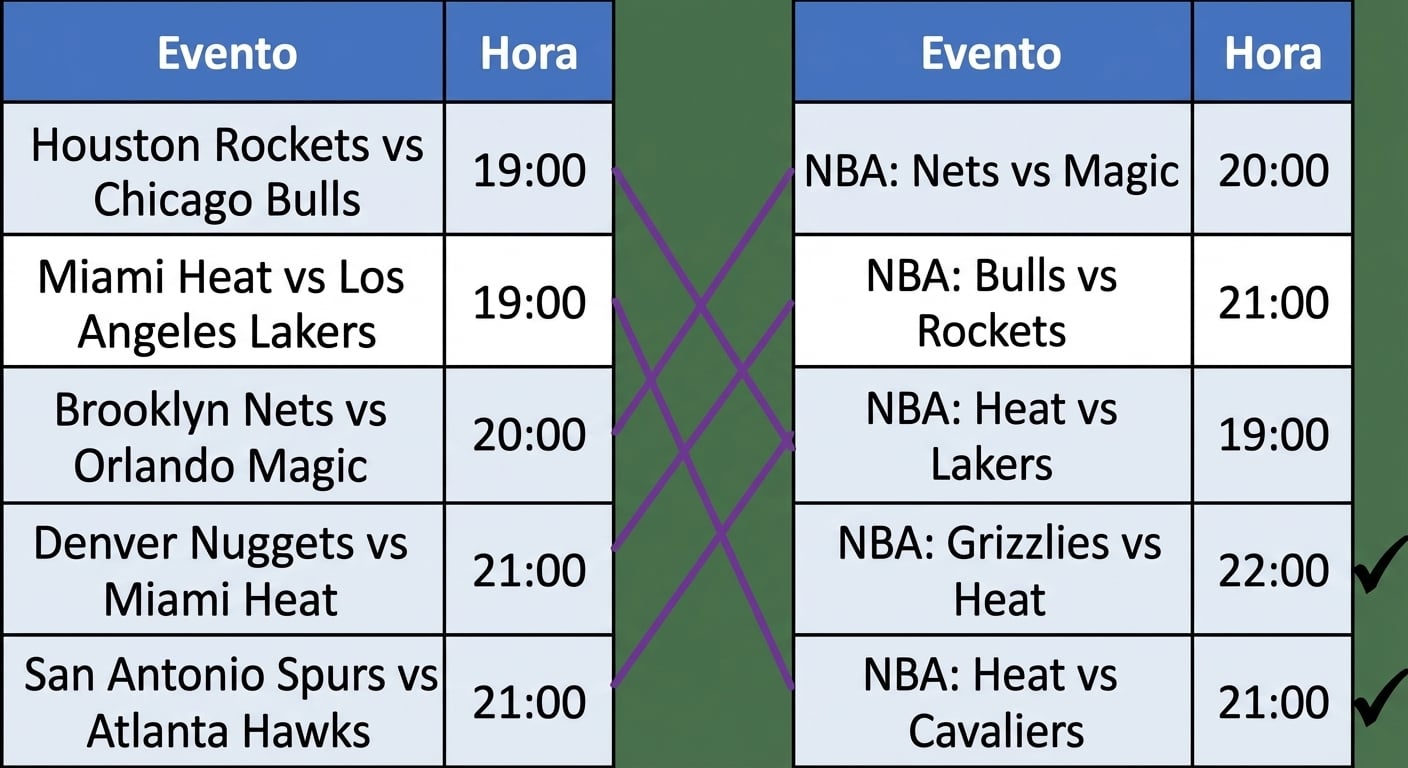
Ligação de registros
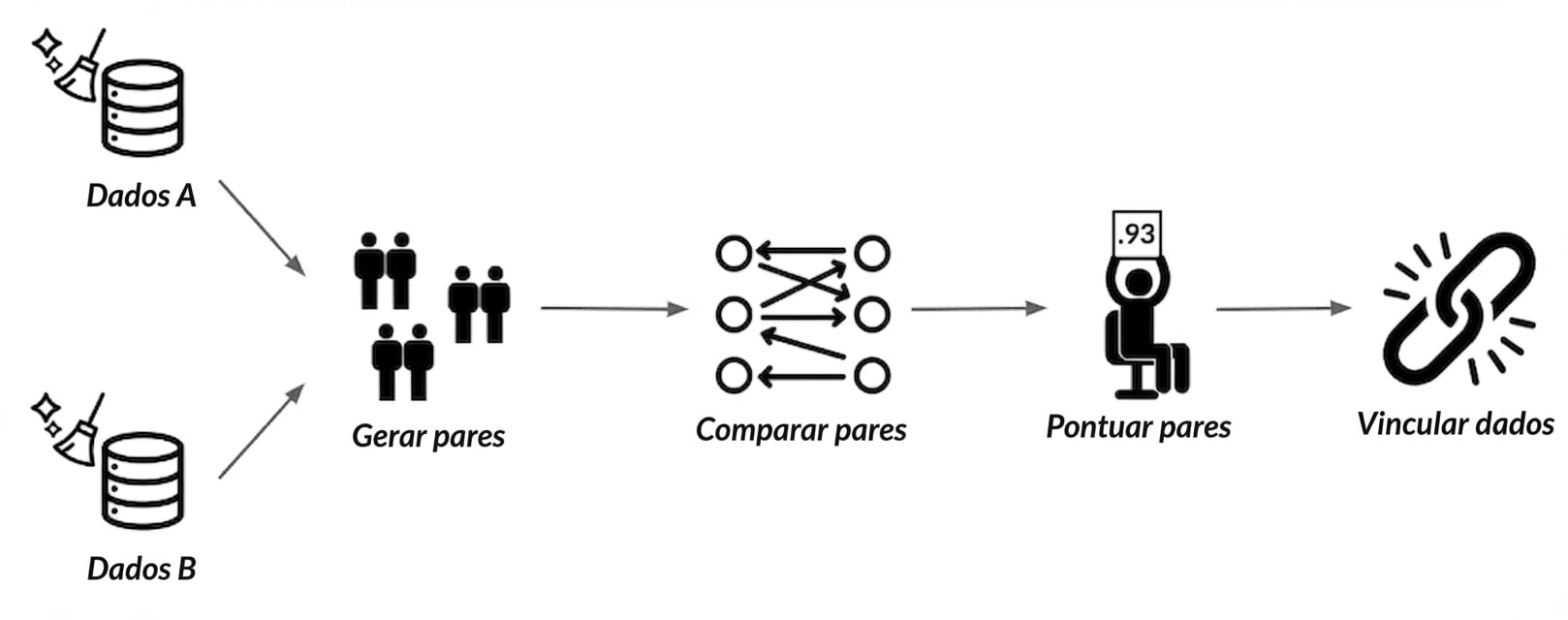
O pacote recordlinkage
Gerando pares
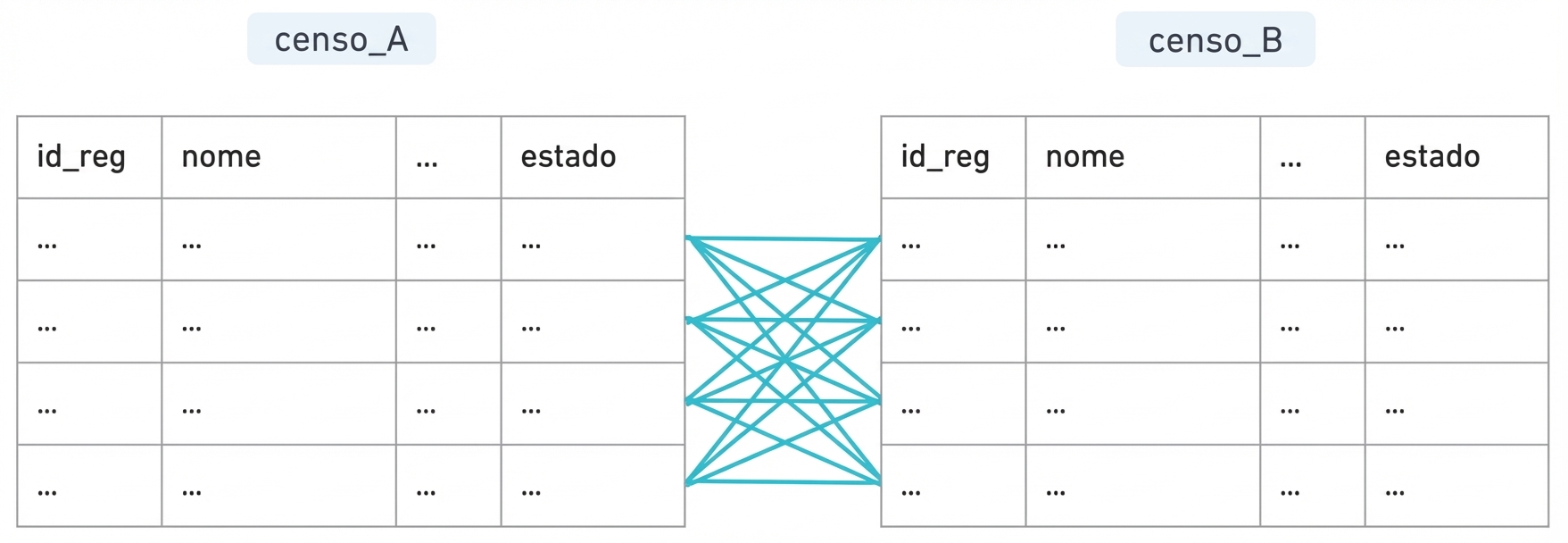
Gerando pares
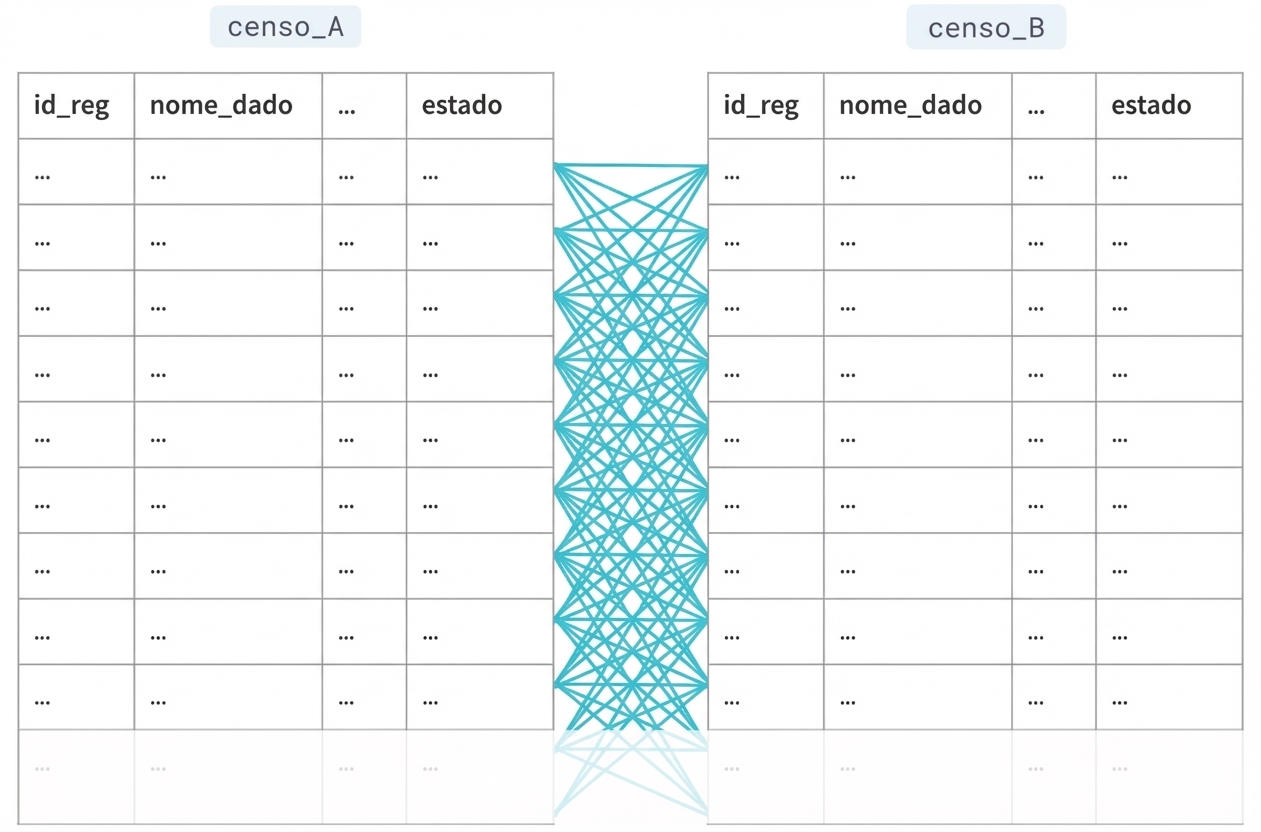
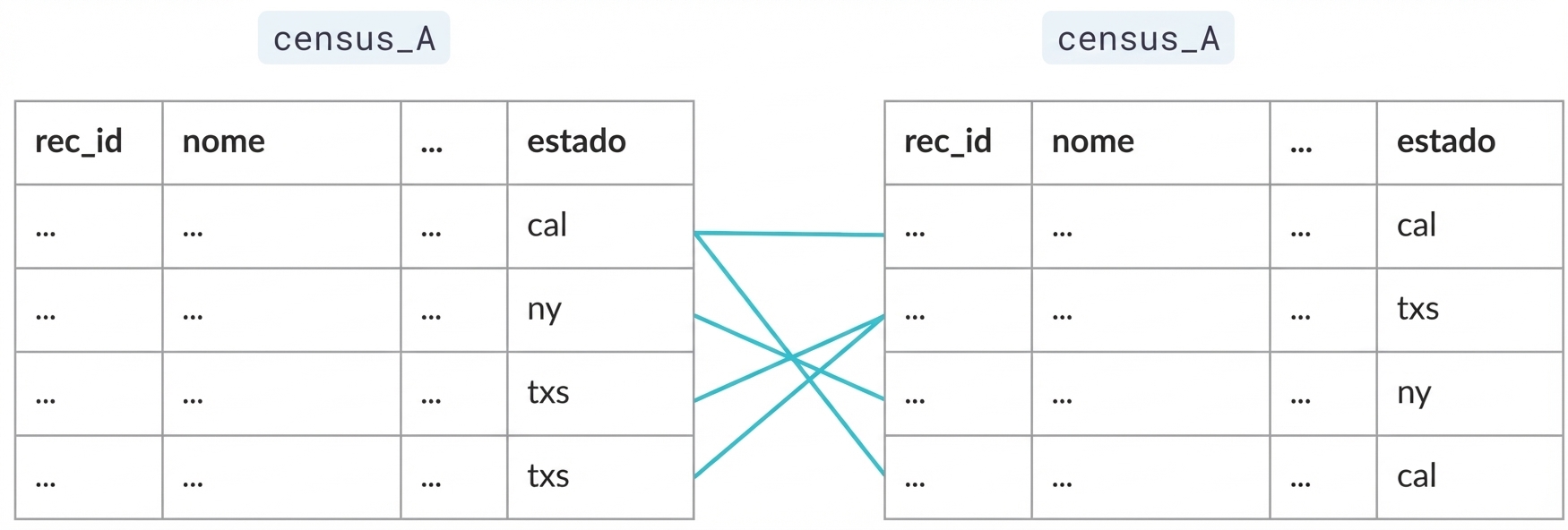
Blocking
Limpeza de dados em Python
Adel Nehme
VP of AI Curriculum, DataCamp
O pacote recordlinkage

