Vinculando DataFrames
Limpeza de dados em Python

Adel Nehme
VP of AI Curriculum, DataCamp
Vinculação de registros
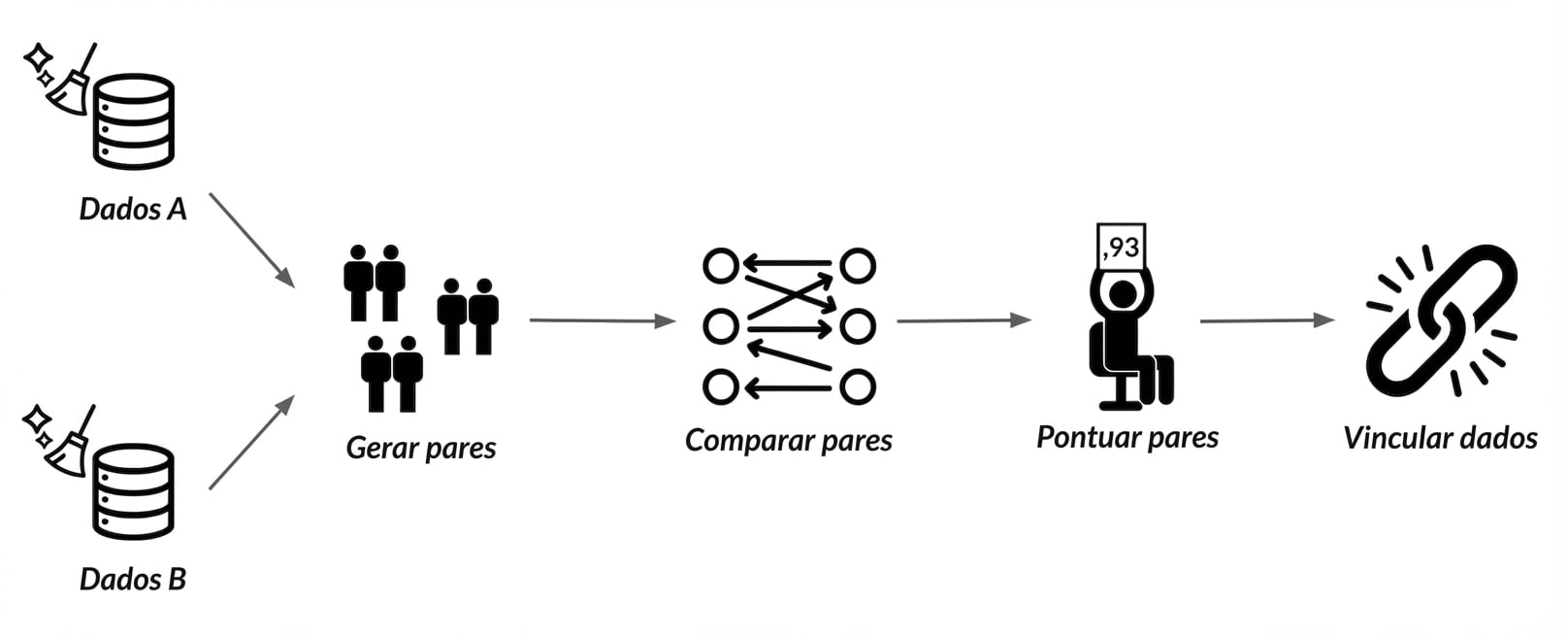
Vinculação de registros
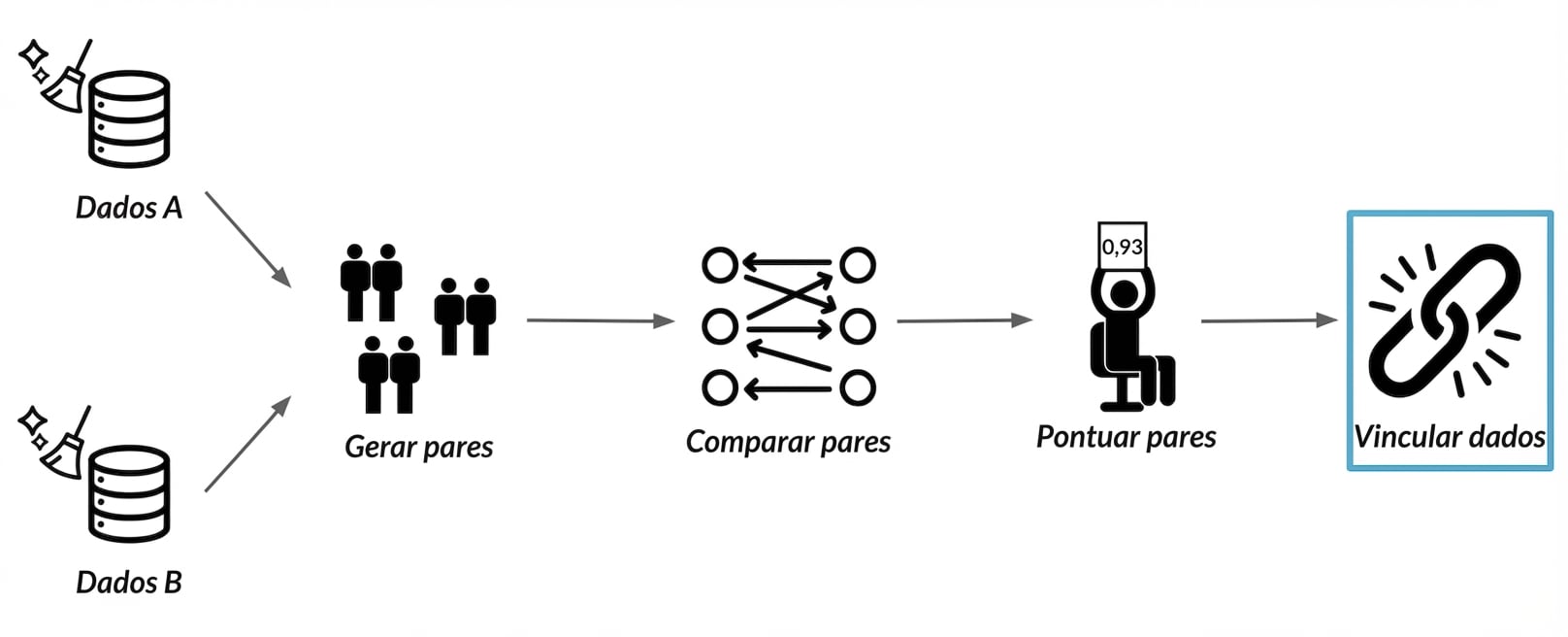
O que estamos fazendo agora
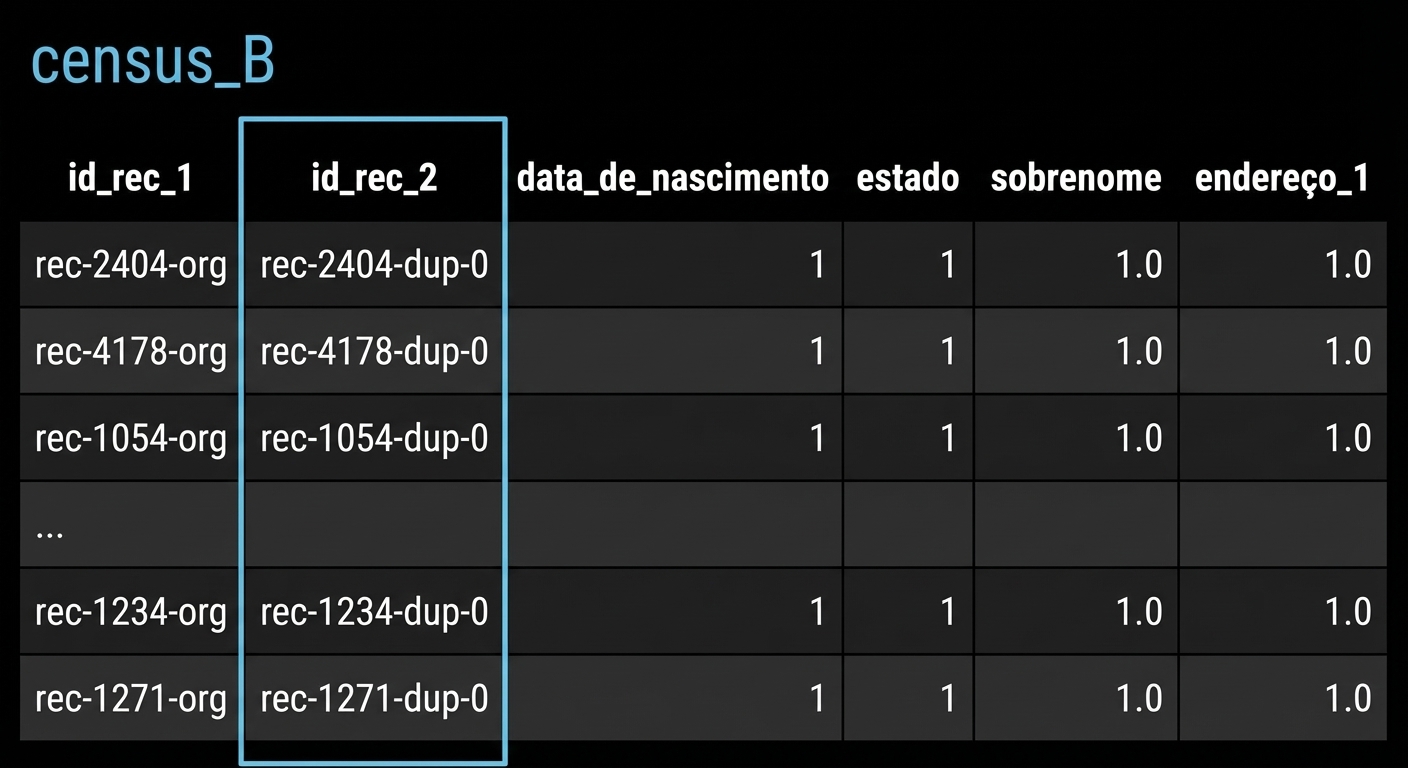
Nossas correspondências potenciais
potential_matches
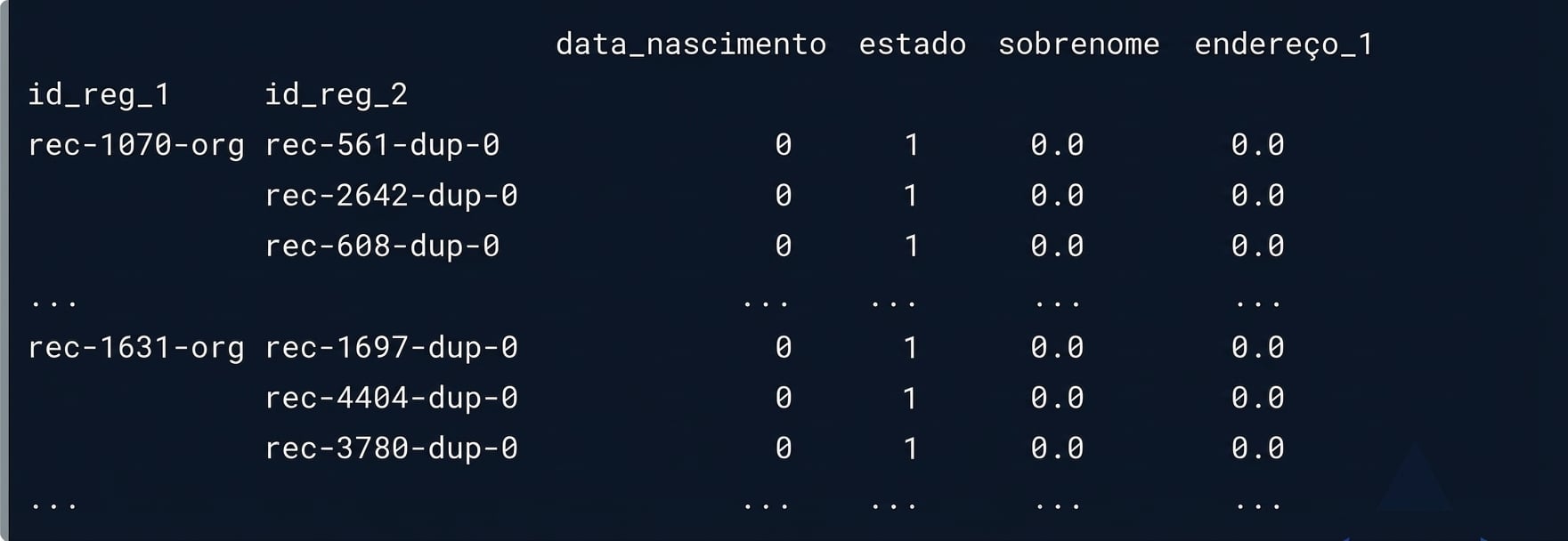
Nossas correspondências potenciais
potential_matches
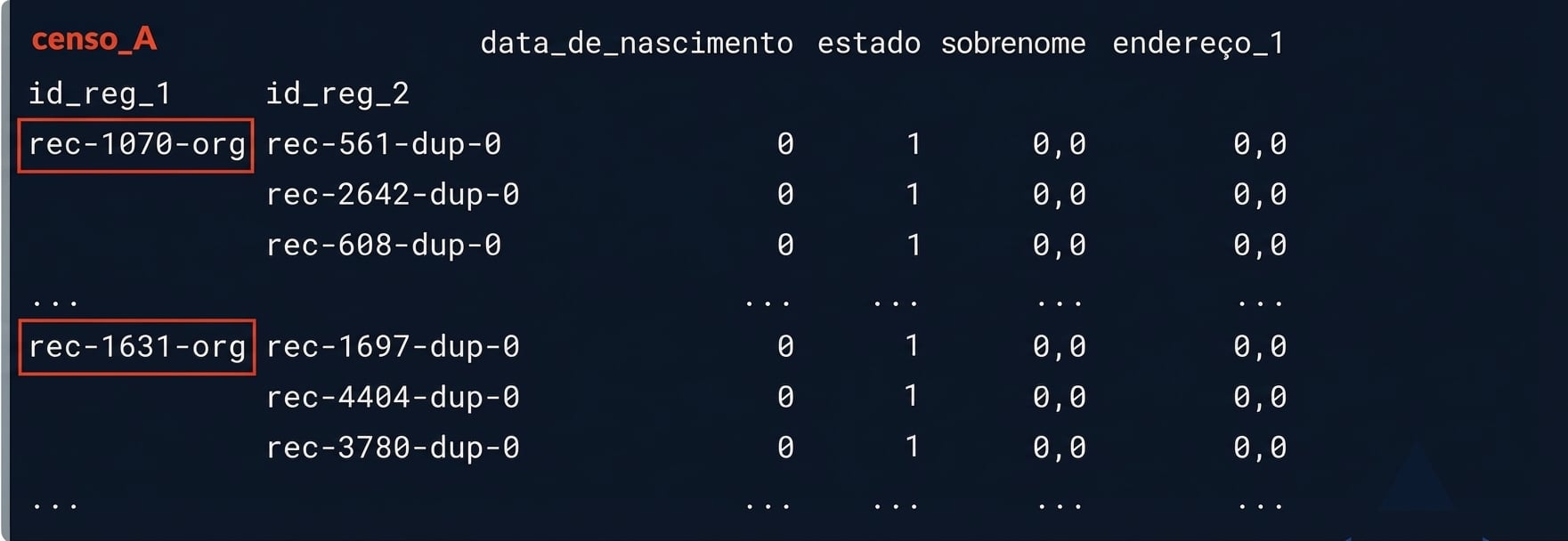
Nossas correspondências potenciais
potential_matches
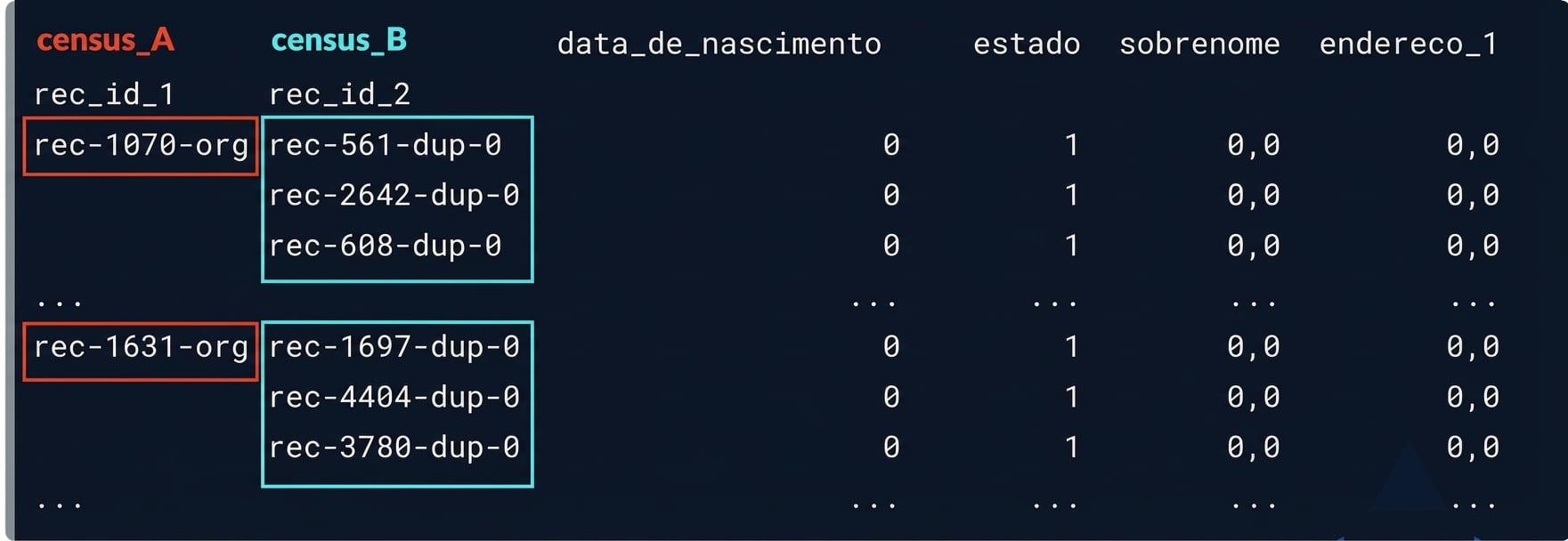
Nossas correspondências potenciais
potential_matches
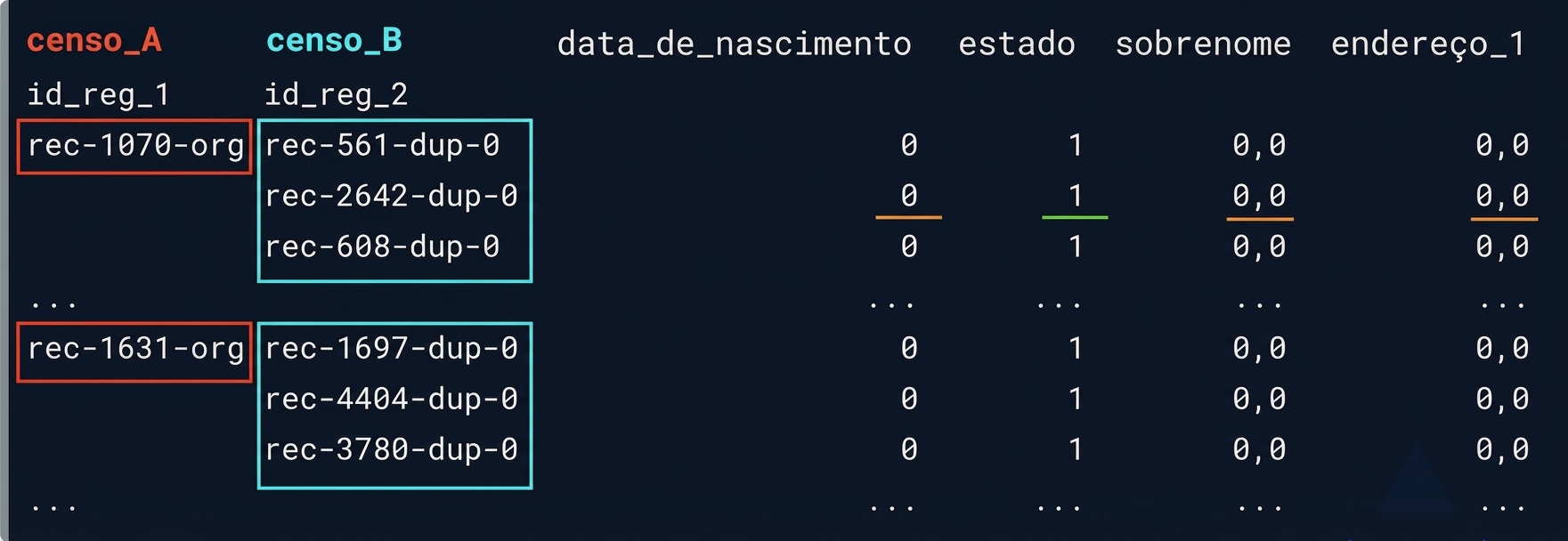
Correspondências prováveis
matches = potential_matches[potential_matches.sum(axis = 1) >= 3]
print(matches)
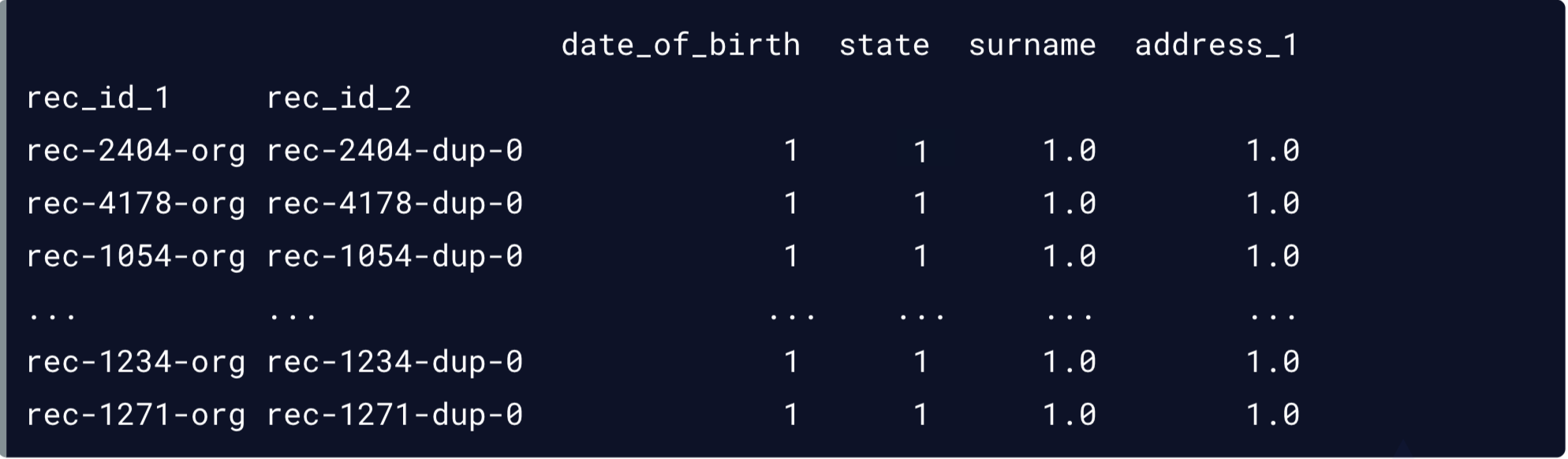
Correspondências prováveis
matches = potential_matches[potential_matches.sum(axis = 1) >= 3]
print(matches)