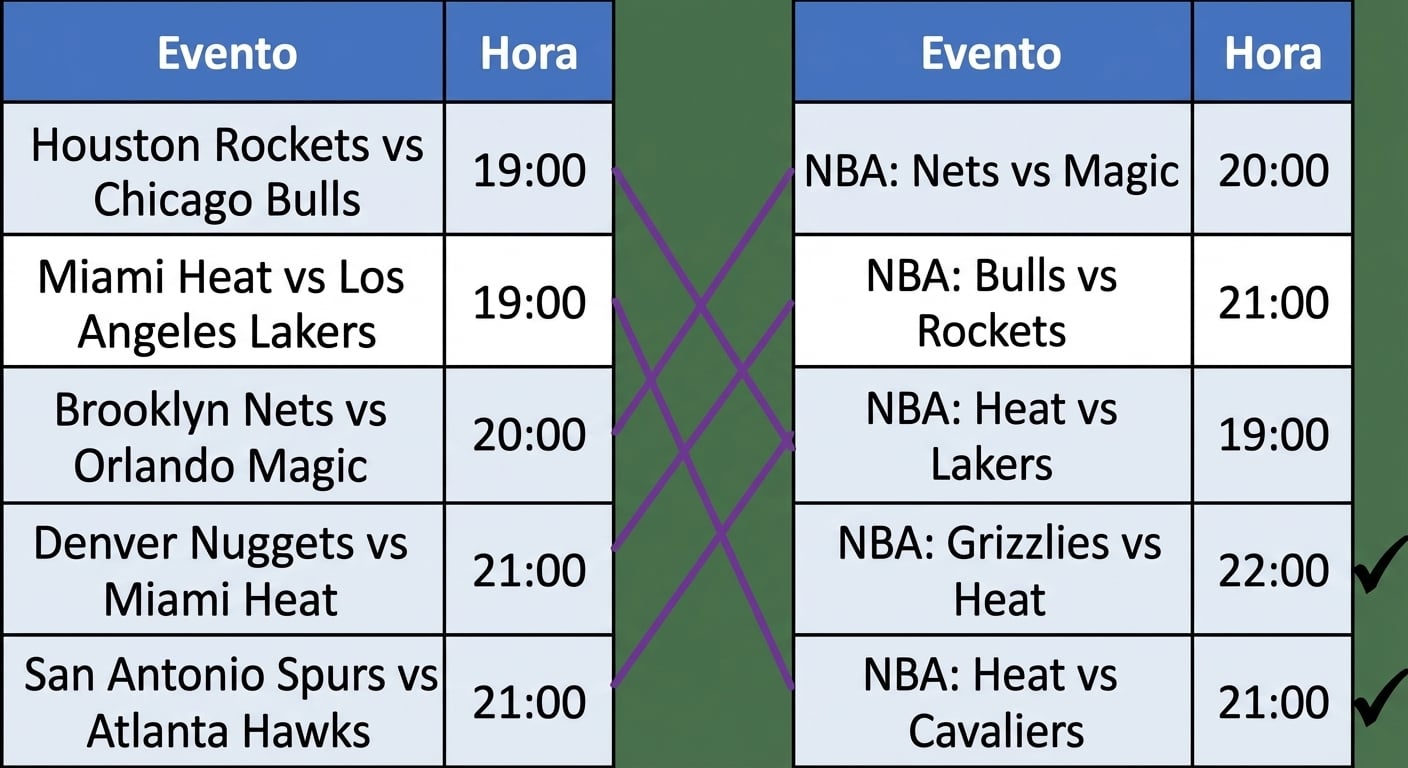
Comparando strings
Limpeza de dados em Python

Adel Nehme
VP of AI Curriculum, DataCamp
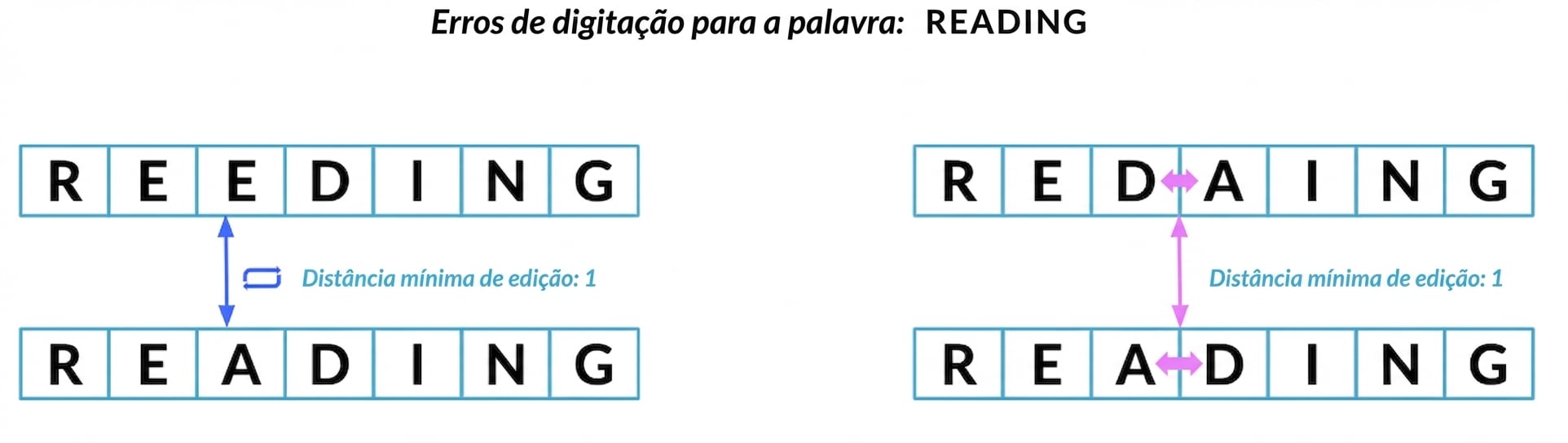
Distância mínima de edição
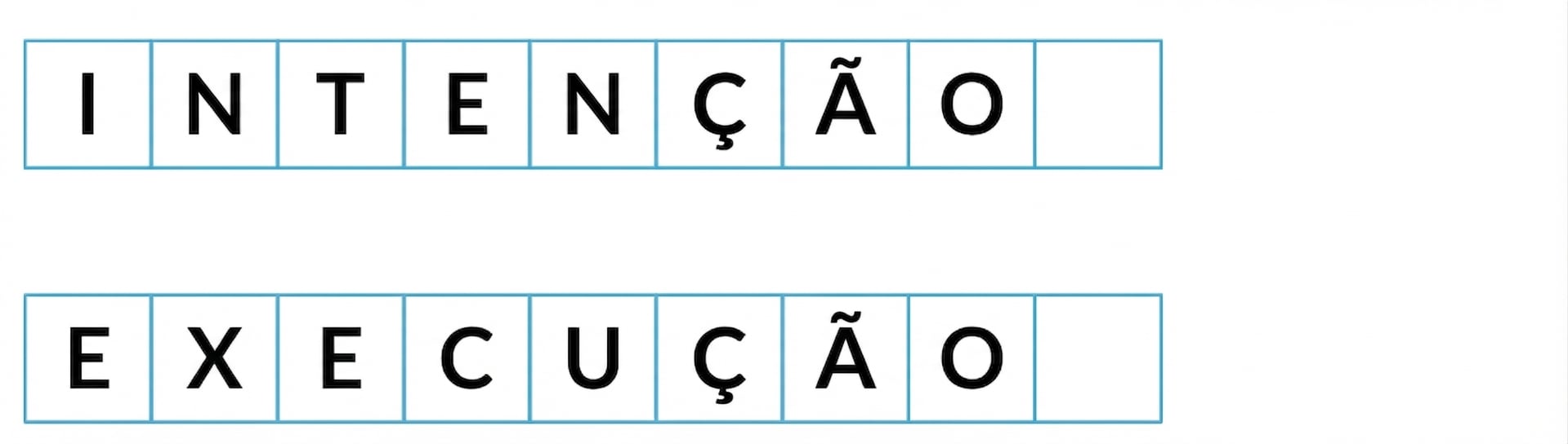
Menor número de passos para converter uma string em outra
Distância mínima de edição

Menor número de passos para converter uma string em outra
Distância mínima de edição

Distância mínima de edição
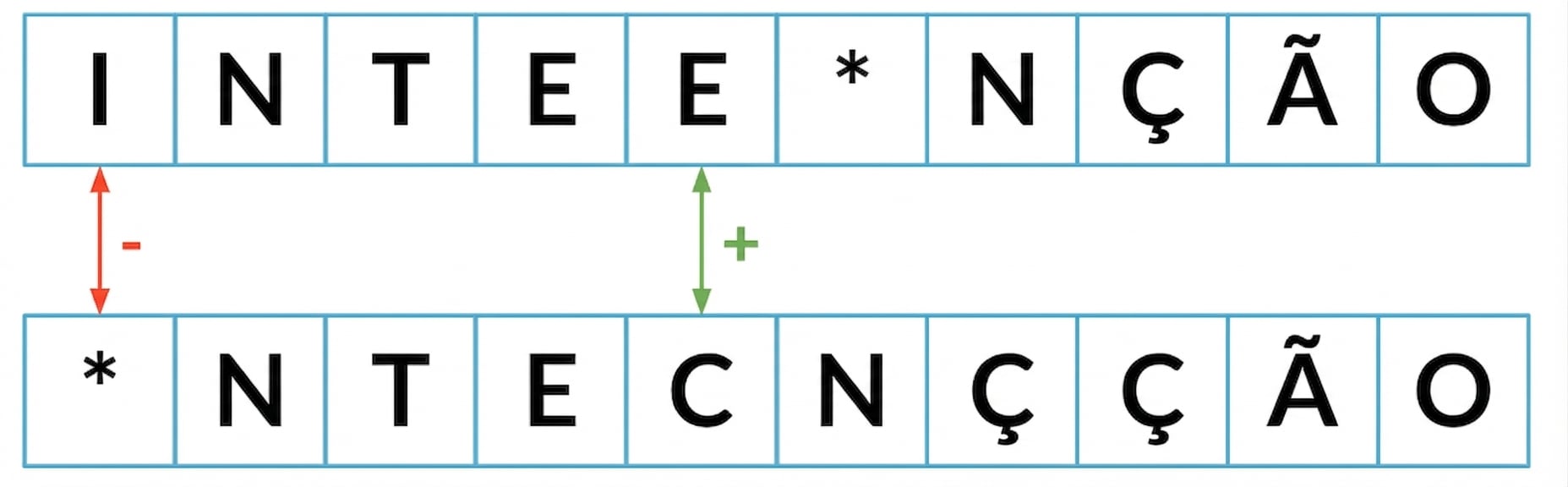
Distância mínima de edição até agora: 2
Distância mínima de edição
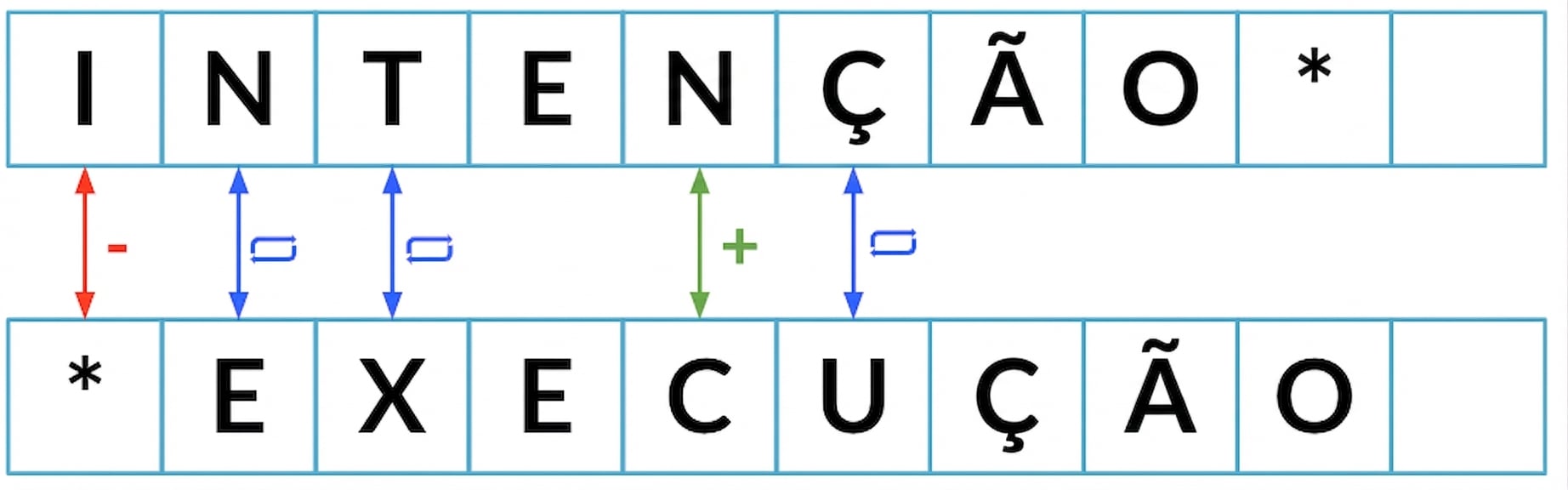
Distância mínima de edição: 5
Distância mínima de edição
Vinculação de registros