Restrições de exclusividade
Limpeza de dados em Python

Adel Nehme
VP of AI Curriculum, DataCamp
Por que acontecem?

Por que acontecem?

Por que acontecem?
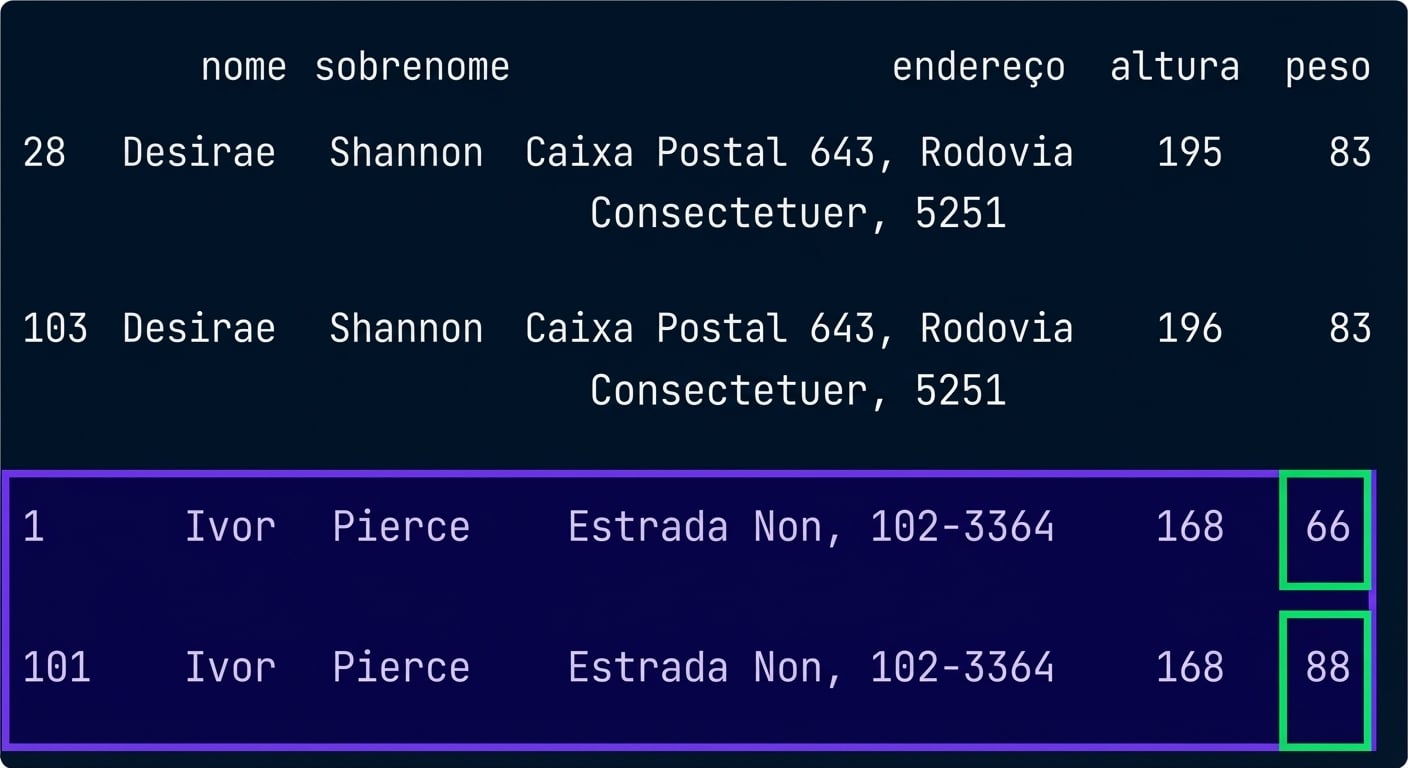
Como encontrar linhas duplicadas?
# Exibir valores duplicados
height_weight[duplicates].sort_values(by = 'first_name')
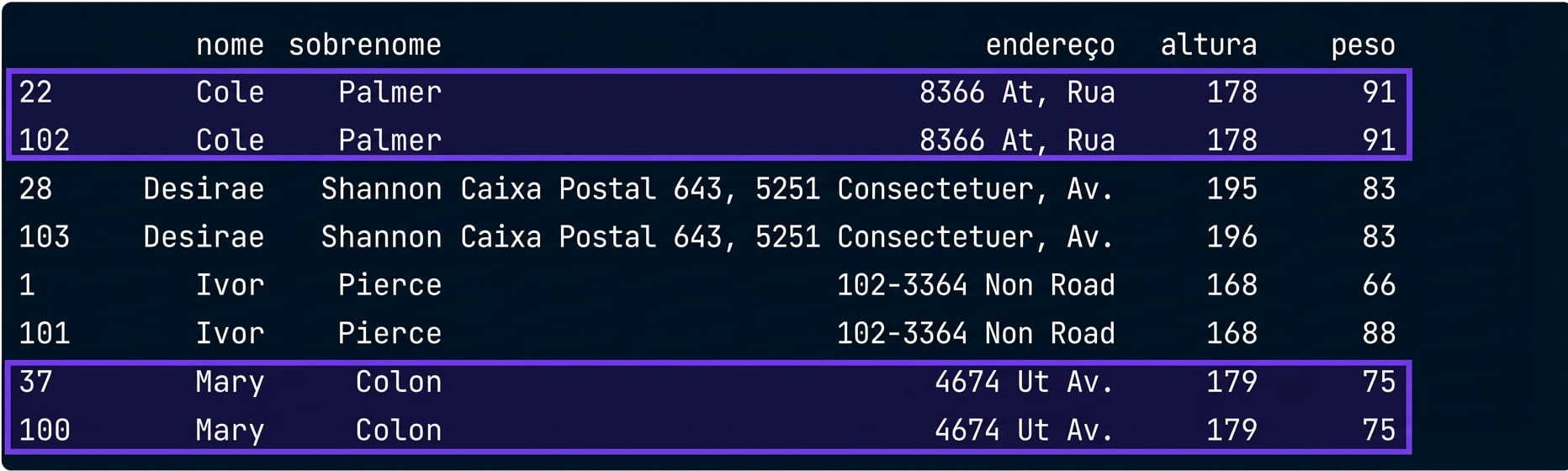
Como encontrar linhas duplicadas?
# Exibir valores duplicados
height_weight[duplicates].sort_values(by = 'first_name')
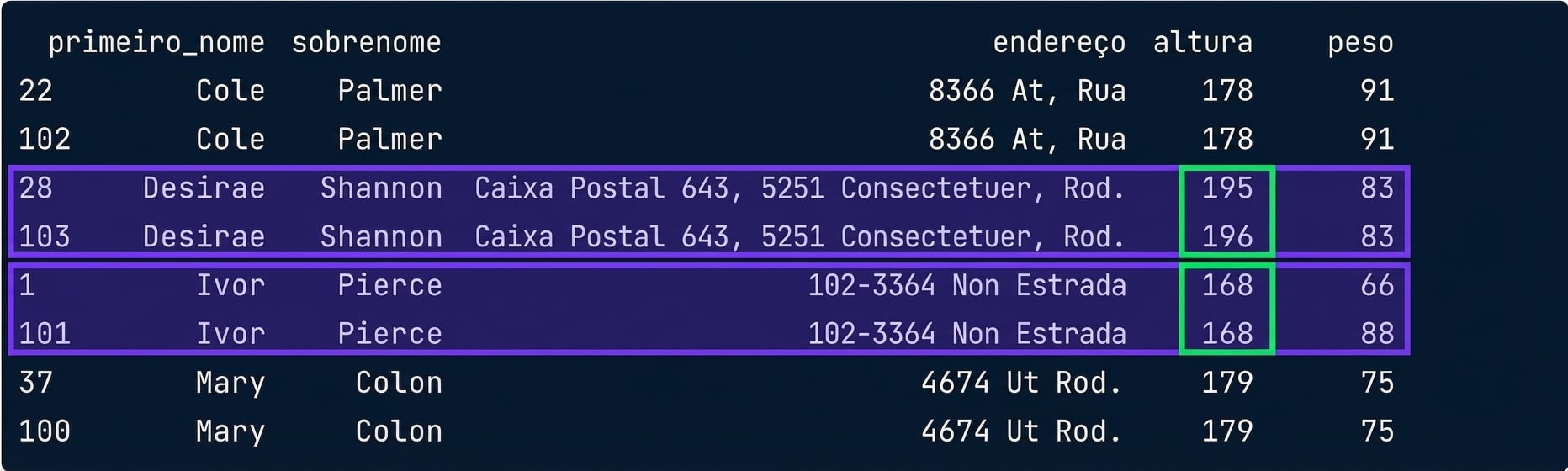
Como tratar valores duplicados?
# Exibir valores duplicados
height_weight[duplicates].sort_values(by = 'first_name')
Como tratar valores duplicados?
# Exibir valores duplicados
column_names = ['first_name','last_name','address']
duplicates = height_weight.duplicated(subset = column_names, keep = False)
height_weight[duplicates].sort_values(by = 'first_name')