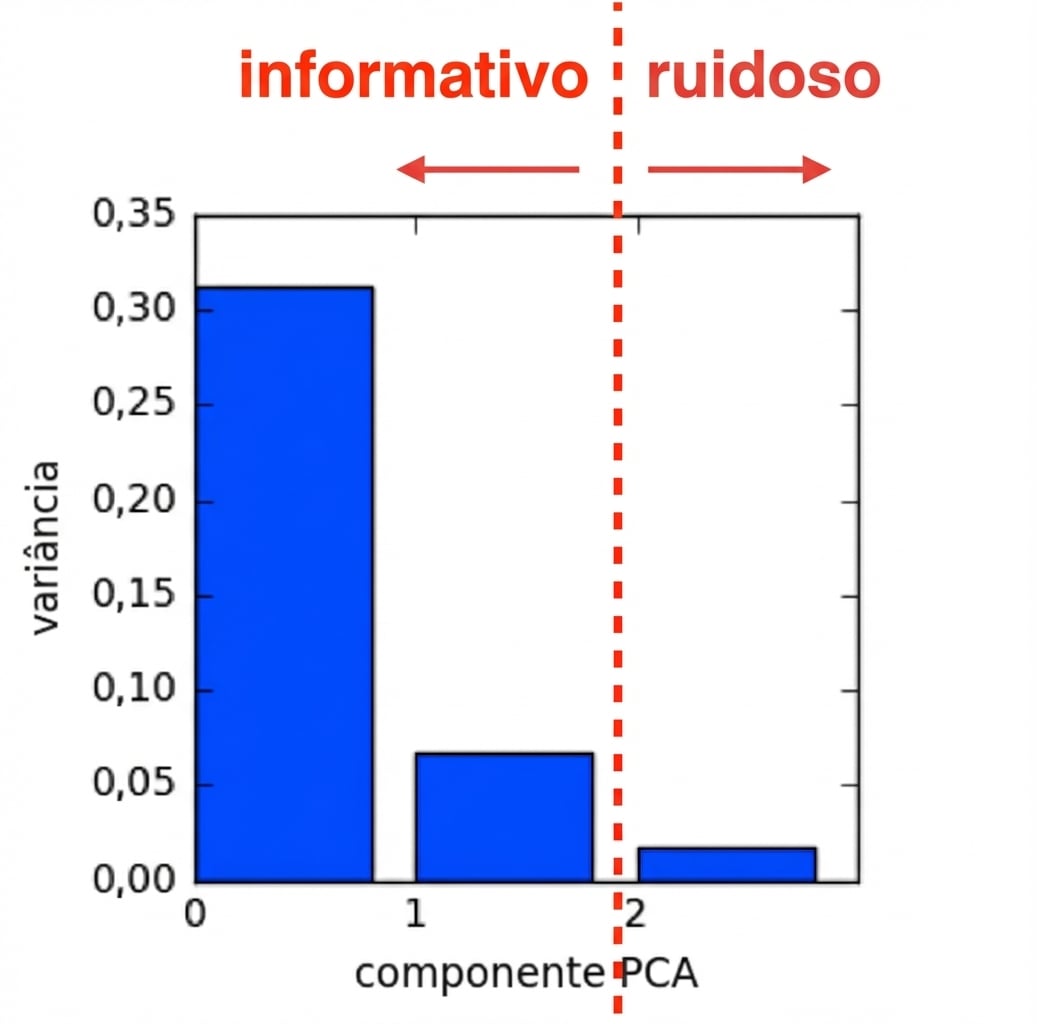
Redução de dimensão com PCA
Unsupervised Learning em Python

Benjamin Wilson
Director of Research at lateral.io
Redução de dimensão com PCA
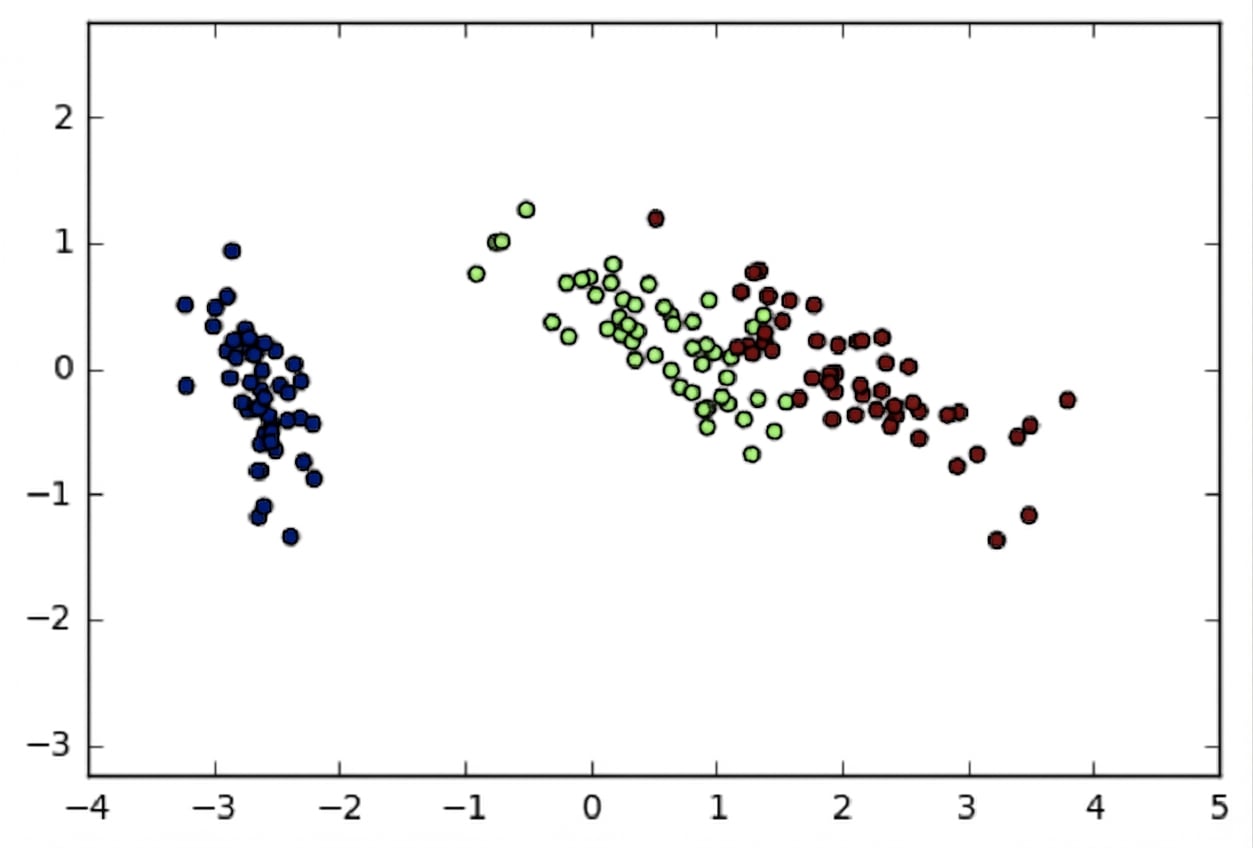
Conjunto Iris em 2 dimensões
import matplotlib.pyplot as plt
xs = transformed[:,0]
ys = transformed[:,1]
plt.scatter(xs, ys, c=species)
plt.show()
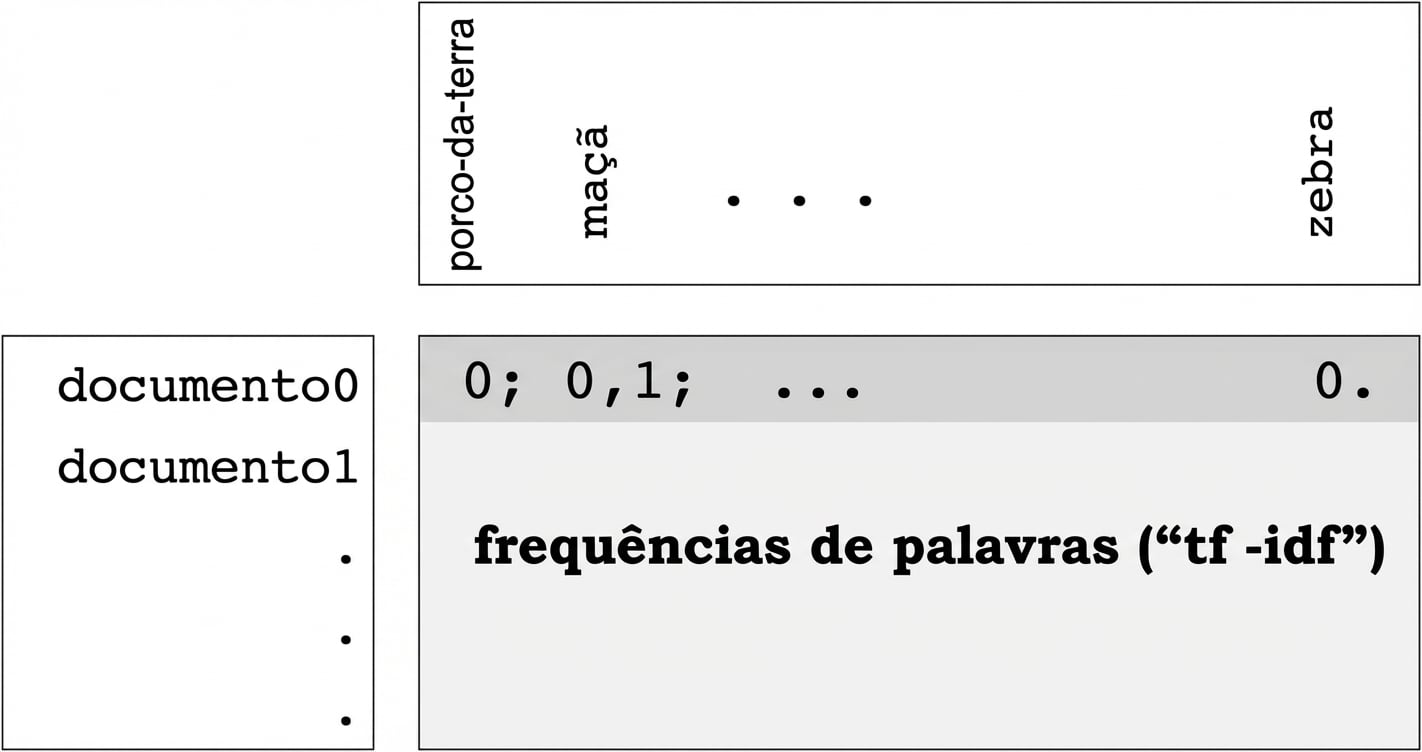
Matrizes de frequência de palavras
- Linhas = documentos, colunas = palavras
- Entradas medem a presença de cada palavra em cada documento
- ... medido com "tf-idf" (veremos já)
Arrays esparsos e csr_matrix
- "Esparsa": a maioria das entradas é zero
- Use
scipy.sparse.csr_matrixem vez de array do NumPy csr_matrixguarda só entradas não zero (economiza espaço!)

