Transformando features para melhores clusters
Unsupervised Learning em Python

Benjamin Wilson
Director of Research at lateral.io
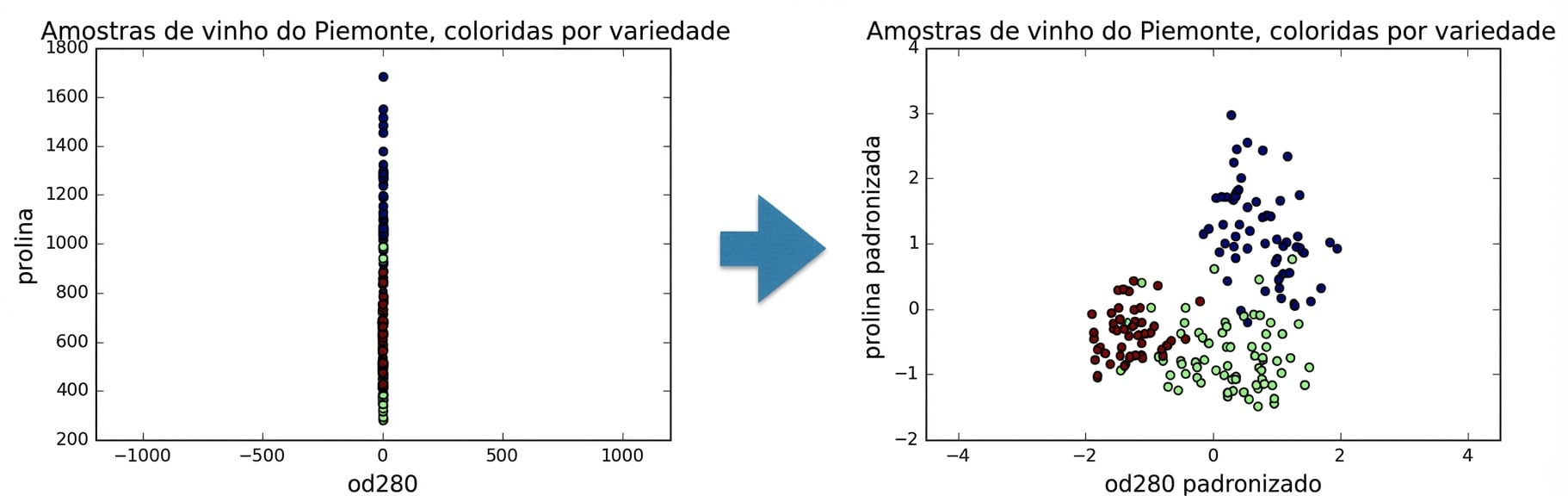
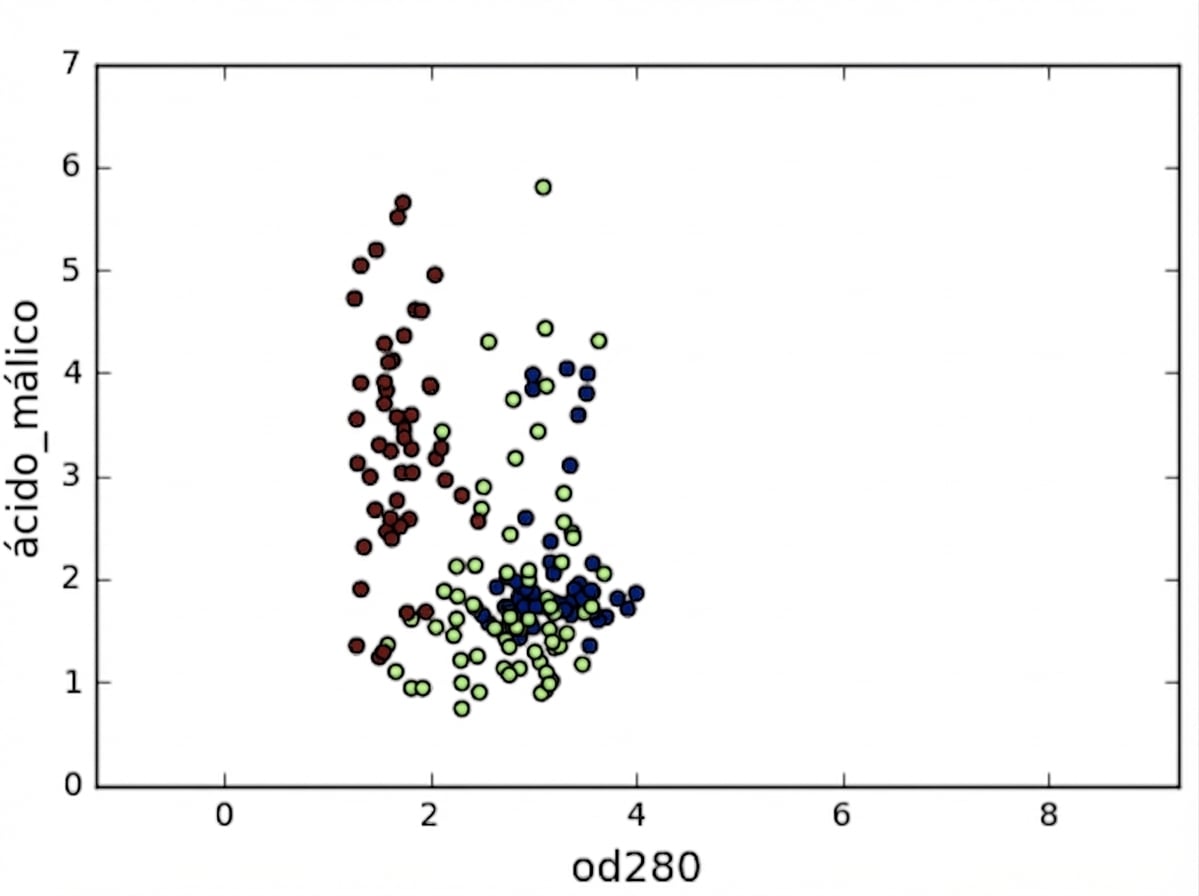
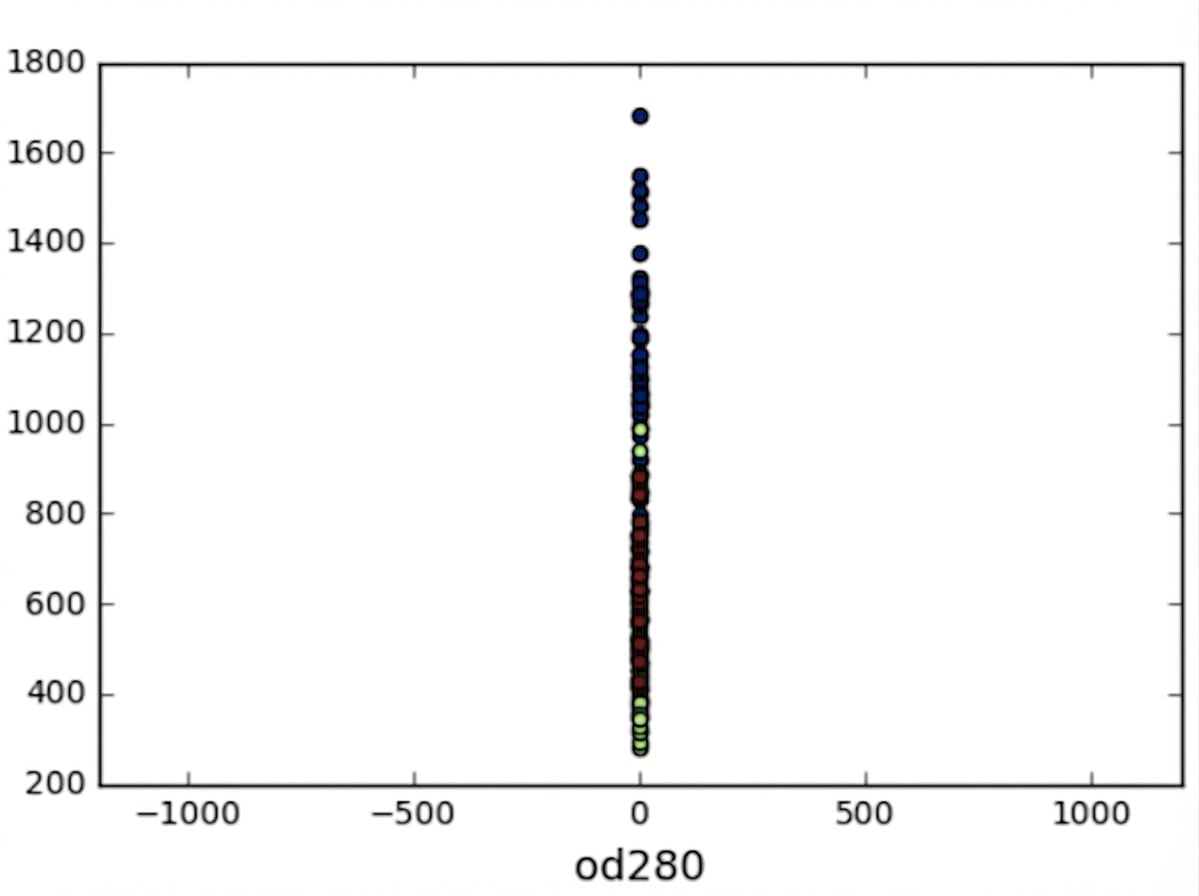
Variâncias das features
Variâncias das features
StandardScaler
No k-means: variância da feature = influência da feature
StandardScalertransforma cada feature para média 0 e variância 1Dizemos que as features ficam “padronizadas”