Unsupervised Learning em Python
Benjamin Wilson
Director of Research at lateral.io
species setosa versicolor virginica labels 0 0 2 36 1 50 0 0 2 0 48 14
pandas
species
print(species)
['setosa', 'setosa', 'versicolor', 'virginica', ... ]
import pandas as pd df = pd.DataFrame({'labels': labels, 'species': species}) print(df)
labels species 0 1 setosa 1 1 setosa 2 2 versicolor 3 2 virginica 4 1 setosa ...
ct = pd.crosstab(df['labels'], df['species']) print(ct)
Como avaliar um agrupamento se não houver informações de espécies?
Usando só as amostras e seus rótulos de cluster
Um bom agrupamento tem clusters compactos
Amostras de cada cluster bem juntas
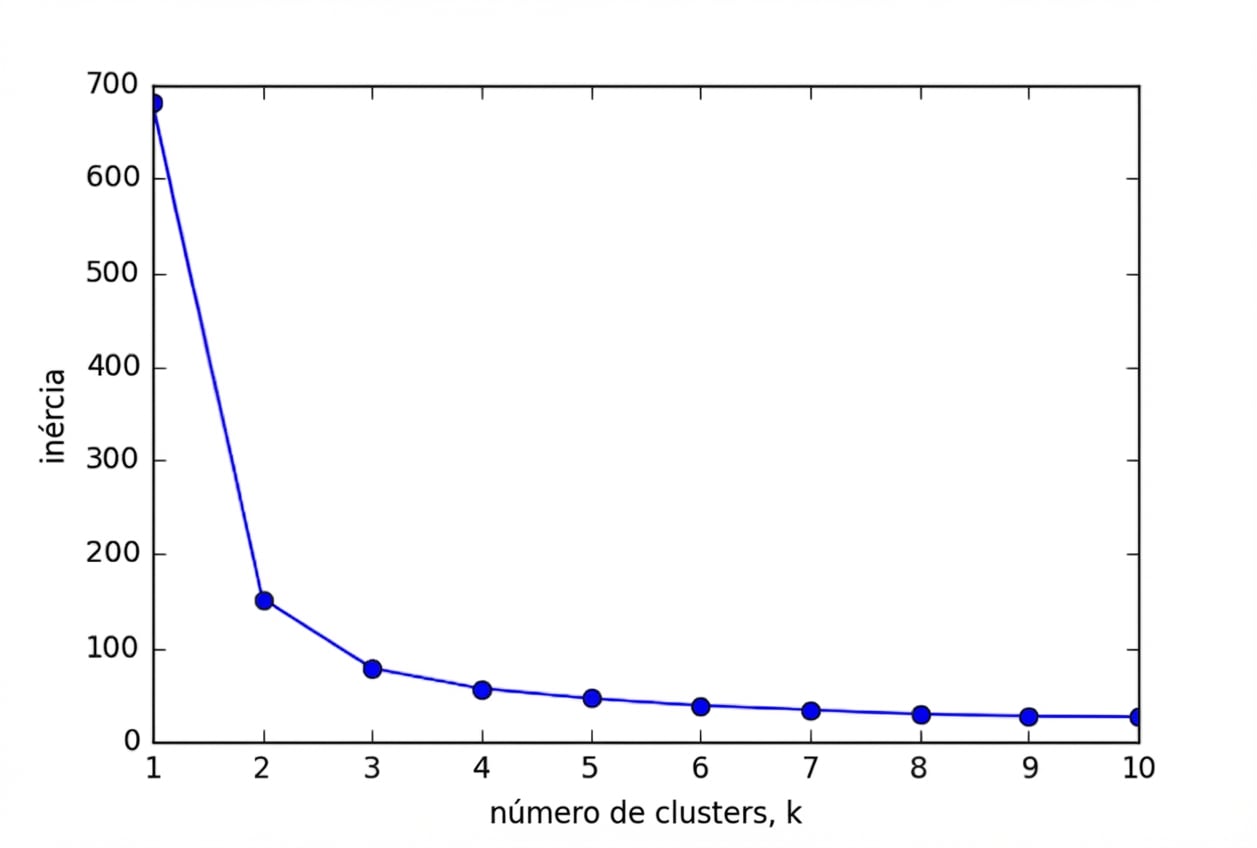
fit()
inertia_
from sklearn.cluster import KMeans model = KMeans(n_clusters=3) model.fit(samples) print(model.inertia_)
78.9408414261