Diagnosticando problemas de viés e variância
Aprendizado de máquina com modelos baseados em árvores em Python

Elie Kawerk
Data Scientist
Estimando o erro de generalização
Como estimar o erro de generalização de um modelo?
Não dá para fazer direto porque:
$f$ é desconhecida,
geralmente você só tem um conjunto de dados,
o ruído é imprevisível.
Estimando o erro de generalização
Solução:
- divida os dados em treino e teste,
- ajuste $\hat{f}$ no treino,
- avalie o erro de $\hat{f}$ no teste não visto.
- erro de generalização de $\hat{f} \approx$ erro no conjunto de teste.
Avaliação melhor com validação cruzada
O conjunto de teste não deve ser usado até termos confiança no desempenho de $\hat{f}$.
Avaliar $\hat{f}$ no treino: estimativa enviesada; $\hat{f}$ já viu todos os pontos de treino.
Solução $\rightarrow$ Validação cruzada (CV):
K-Fold CV,
Hold-Out CV.
K-Fold CV
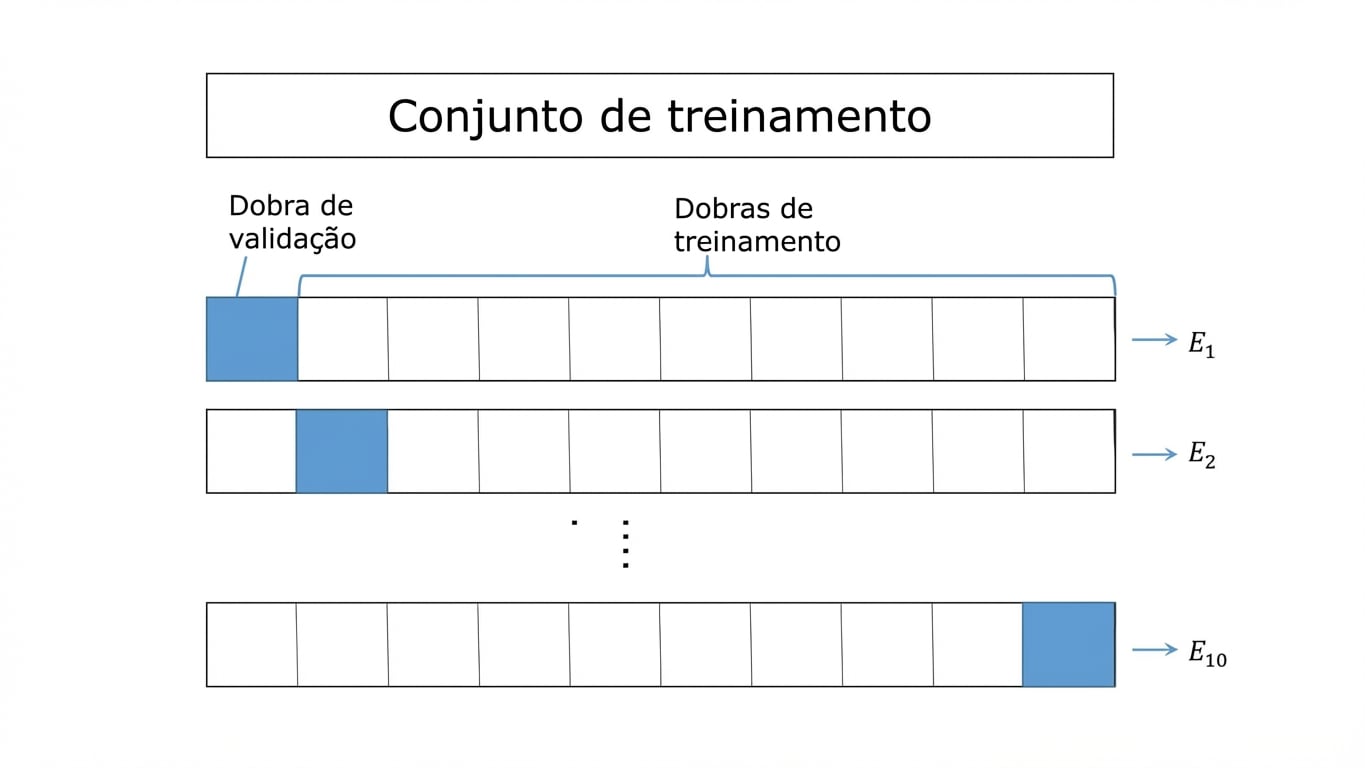
K-Fold CV
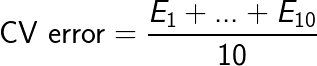
Diagnosticar problemas de variância
Se $\hat{f}$ tem alta variância:
Erro de CV de $\hat{f}$ > erro no treino de $\hat{f}$.
- Dizemos que $\hat{f}$ faz overfitting. Para corrigir:
- reduza a complexidade do modelo,
- ex.: diminua a profundidade máx., aumente mín. amostras por folha, ...
- colete mais dados, ..
Diagnosticar problemas de viés
Se $\hat{f}$ tem alto viés:
Erro de CV de $\hat{f} \approx$ erro no treino de $\hat{f} >>$ erro desejado.
Dizemos que $\hat{f}$ faz underfitting. Para corrigir:
- aumente a complexidade do modelo
- ex.: aumente a profundidade máx., diminua mín. amostras por folha, ...
- adicione recursos (features) mais relevantes
K-Fold CV no sklearn com o conjunto Auto
from sklearn.tree import DecisionTreeRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error as MSE from sklearn.model_selection import cross_val_score# Set seed for reproducibility SEED = 123 # Split data into 70% train and 30% test X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state=SEED)# Instantiate decision tree regressor and assign it to 'dt' dt = DecisionTreeRegressor(max_depth=4, min_samples_leaf=0.14, random_state=SEED)
K-Fold CV no sklearn com o conjunto Auto
# Evaluate the list of MSE ontained by 10-fold CV # Set n_jobs to -1 in order to exploit all CPU cores in computation MSE_CV = - cross_val_score(dt, X_train, y_train, cv= 10, scoring='neg_mean_squared_error', n_jobs = -1)# Fit 'dt' to the training set dt.fit(X_train, y_train) # Predict the labels of training set y_predict_train = dt.predict(X_train) # Predict the labels of test set y_predict_test = dt.predict(X_test)
# CV MSE
print('CV MSE: {:.2f}'.format(MSE_CV.mean()))
CV MSE: 20.51
# Training set MSE
print('Train MSE: {:.2f}'.format(MSE(y_train, y_predict_train)))
Train MSE: 15.30
# Test set MSE
print('Test MSE: {:.2f}'.format(MSE(y_test, y_predict_test)))
Test MSE: 20.92
Vamos praticar!
Aprendizado de máquina com modelos baseados em árvores em Python

