Random Forests
Aprendizado de máquina com modelos baseados em árvores em Python

Elie Kawerk
Data Scientist
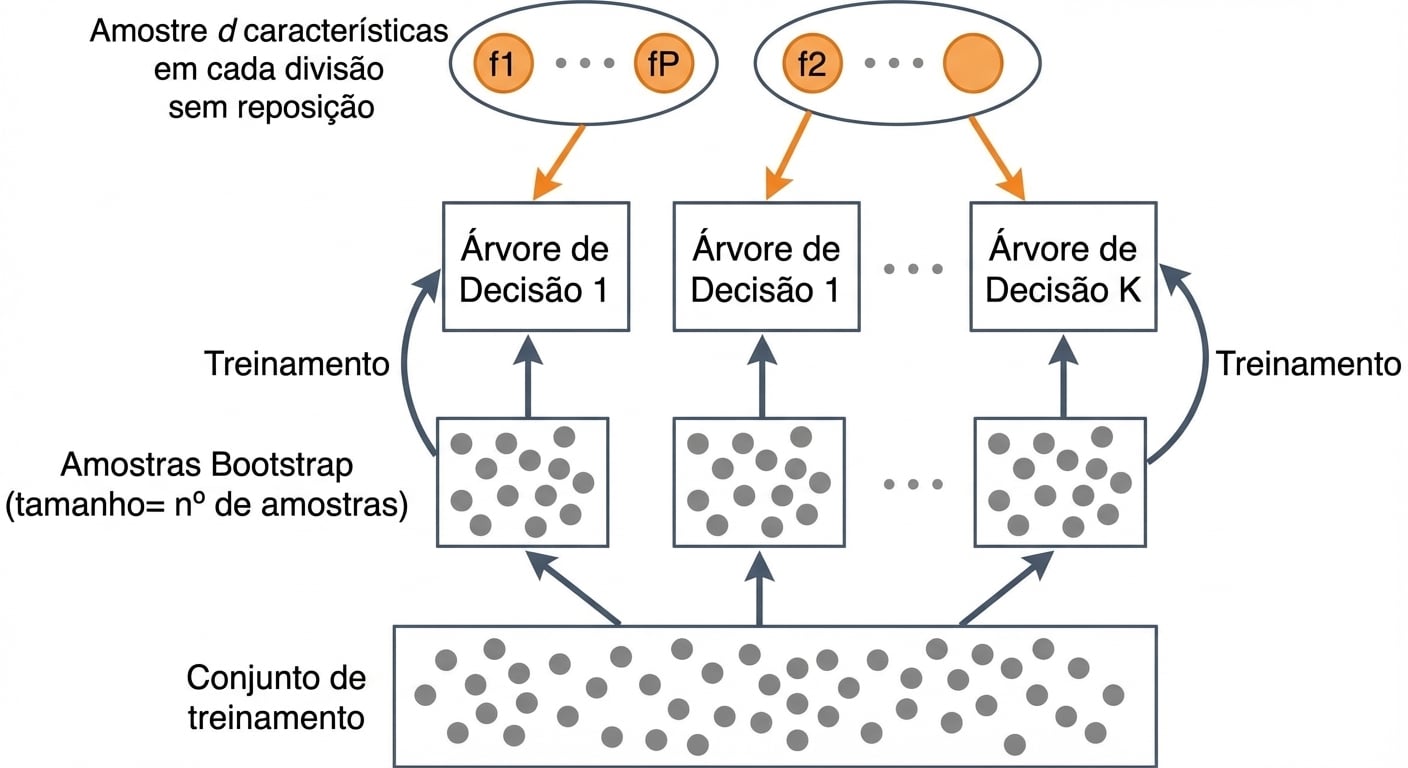
Random Forests: Treino
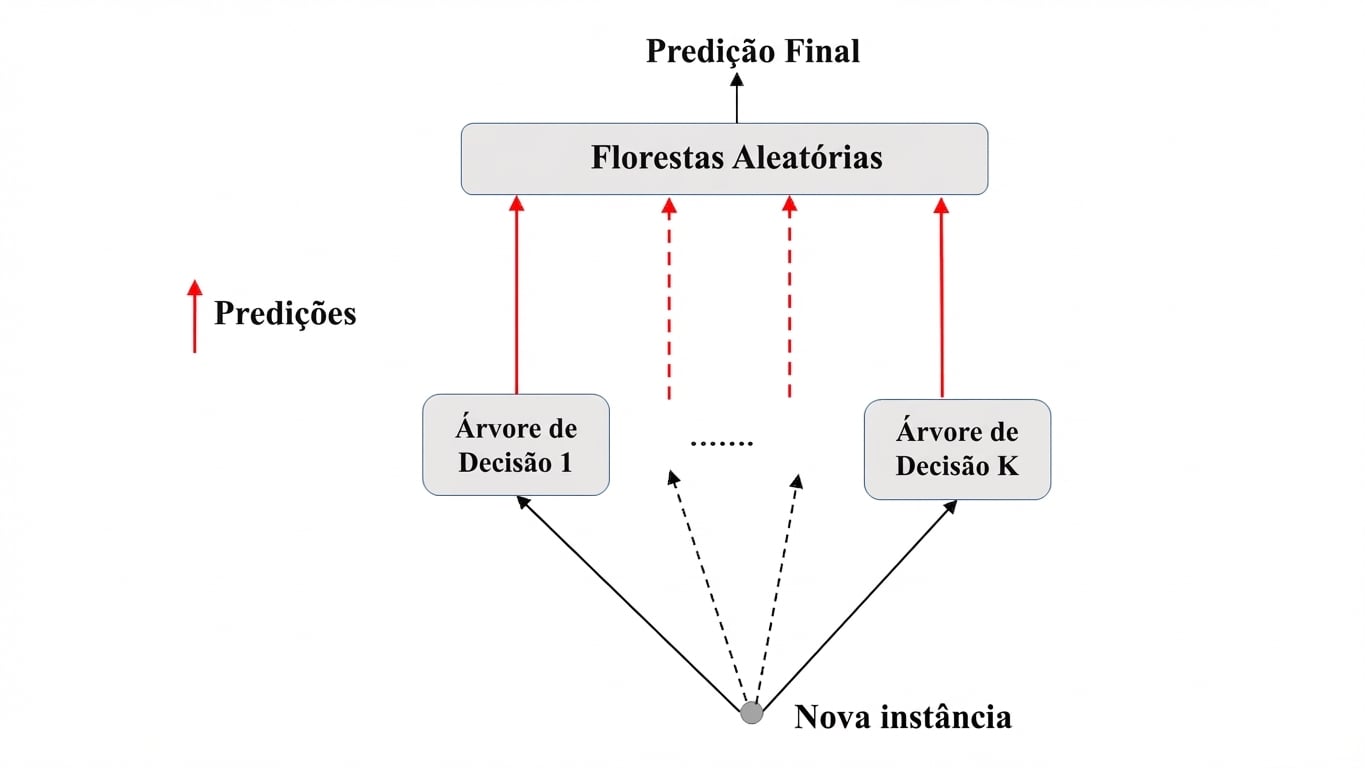
Random Forests: Previsão
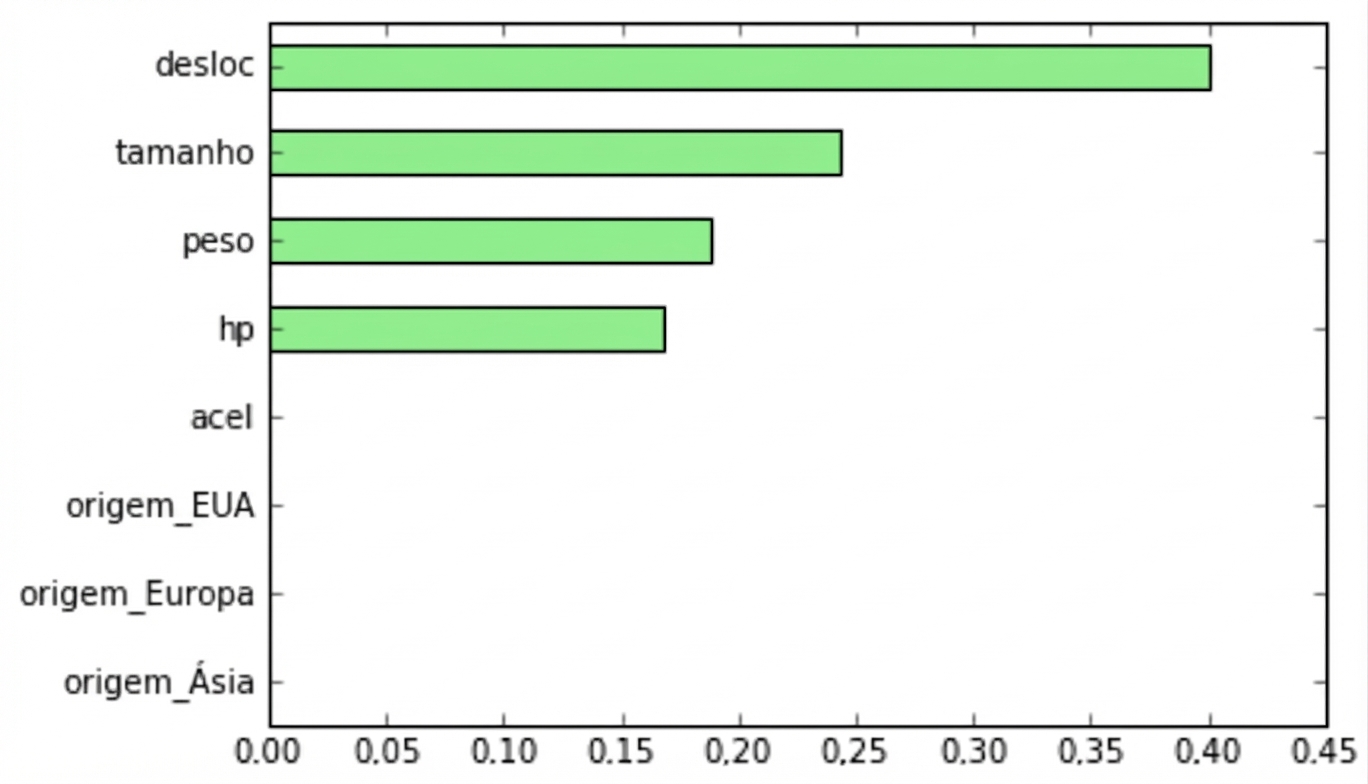
Importância das Features no sklearn
Aprendizado de máquina com modelos baseados em árvores em Python
Elie Kawerk
Data Scientist

