Aprendizado de máquina com modelos baseados em árvores em Python
Elie Kawerk
Data Scientist
Bagging
algumas instâncias podem ser amostradas várias vezes para um modelo,
outras podem não ser amostradas.
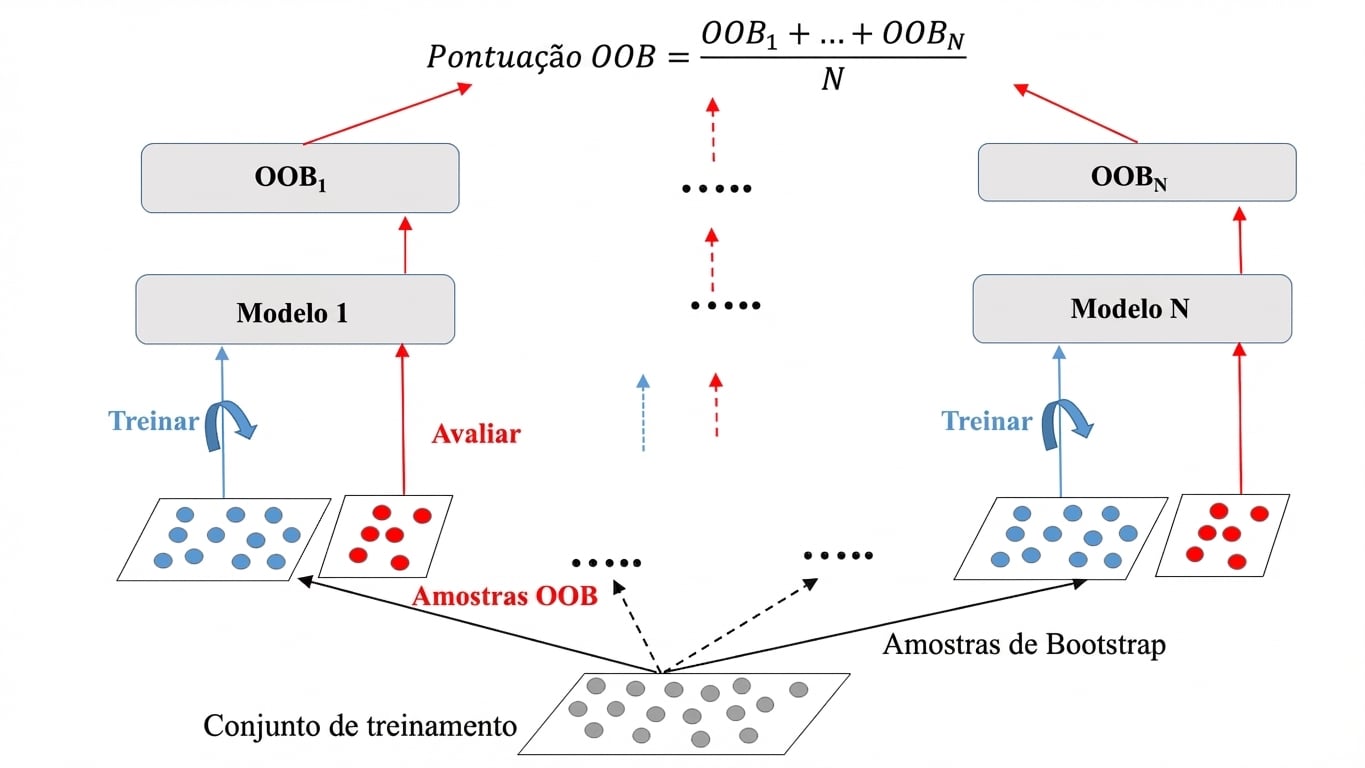
Instâncias Out-of-Bag (OOB)
Em média, para cada modelo, 63% das instâncias de treino são amostradas.
Os 37% restantes são as instâncias OOB.
Avaliação OOB
Avaliação OOB no sklearn (Breast Cancer Dataset)
# Import models and split utility function
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# Set seed for reproducibility
SEED = 1
# Split data into 70% train and 30% test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.3,
stratify= y,
random_state=SEED)
# Instantiate a classification-tree 'dt'
dt = DecisionTreeClassifier(max_depth=4,
min_samples_leaf=0.16,
random_state=SEED)
# Instantiate a BaggingClassifier 'bc'; set oob_score = True
bc = BaggingClassifier(base_estimator=dt, n_estimators=300,
oob_score=True, n_jobs=-1)
# Fit 'bc' to the training set
bc.fit(X_train, y_train)
# Predict the test set labels
y_pred = bc.predict(X_test)
# Evaluate test set accuracy
test_accuracy = accuracy_score(y_test, y_pred)
# Extract the OOB accuracy from 'bc'
oob_accuracy = bc.oob_score_
# Print test set accuracy
print('Test set accuracy: {:.3f}'.format(test_accuracy))