Erro de generalização
Aprendizado de máquina com modelos baseados em árvores em Python

Elie Kawerk
Data Scientist
Supervisionado — Por baixo dos panos
- Aprendizado supervisionado: $y = f(x)$, $f$ é desconhecida.
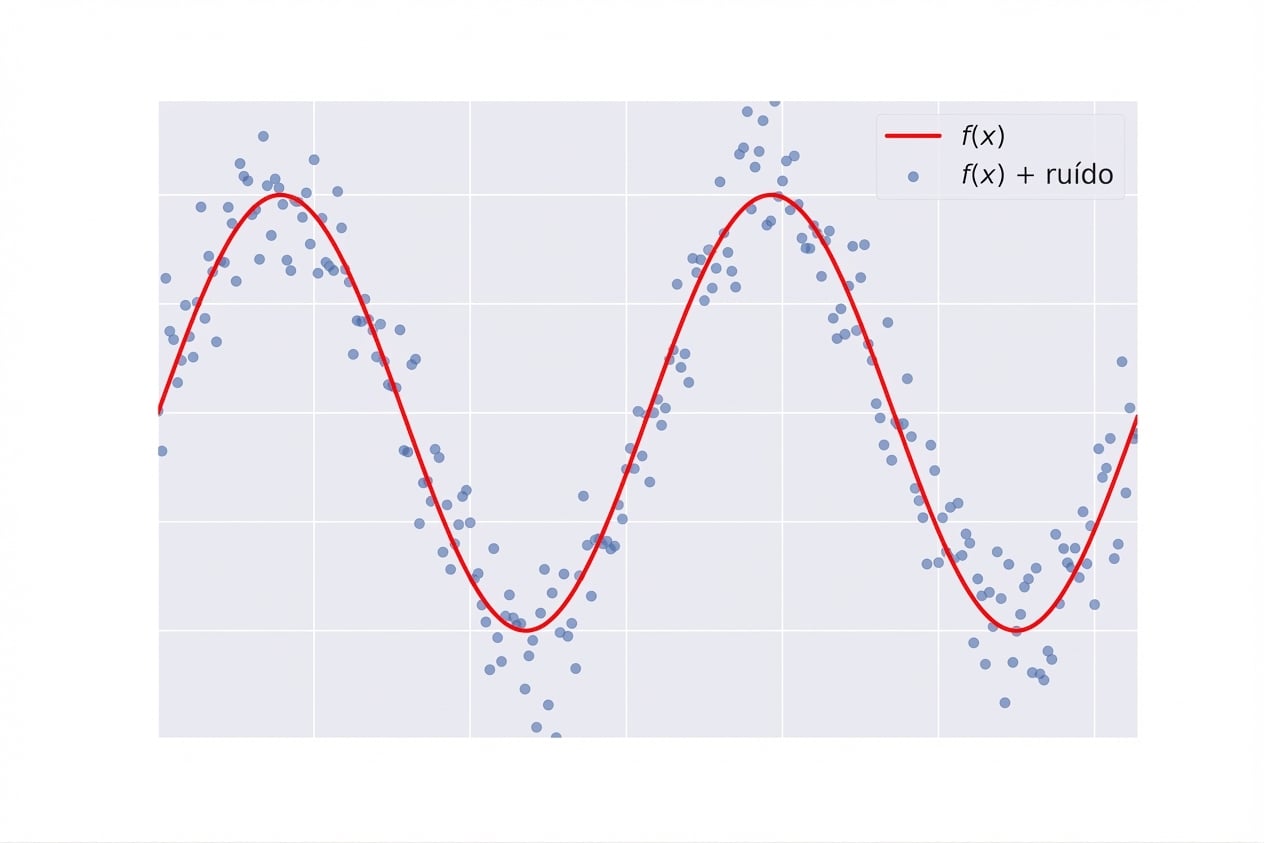
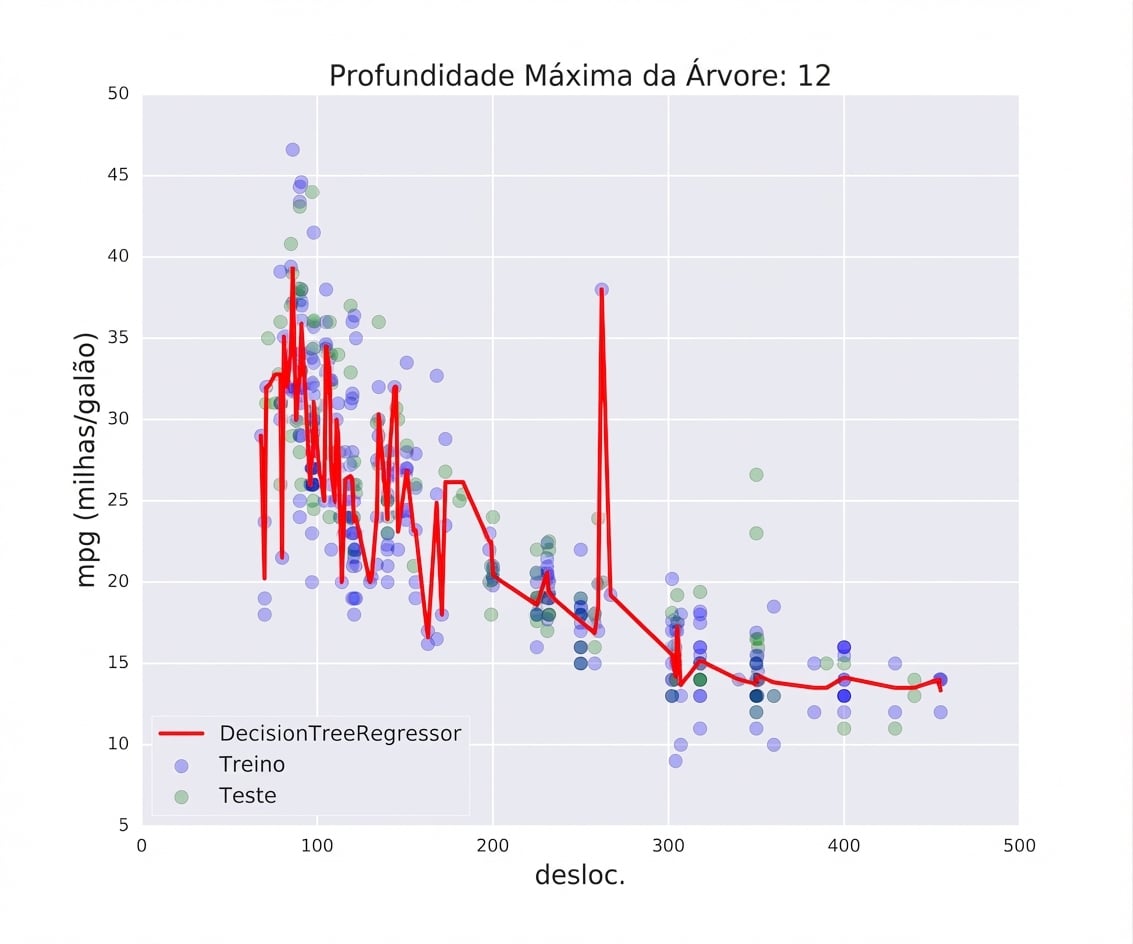
Overfitting
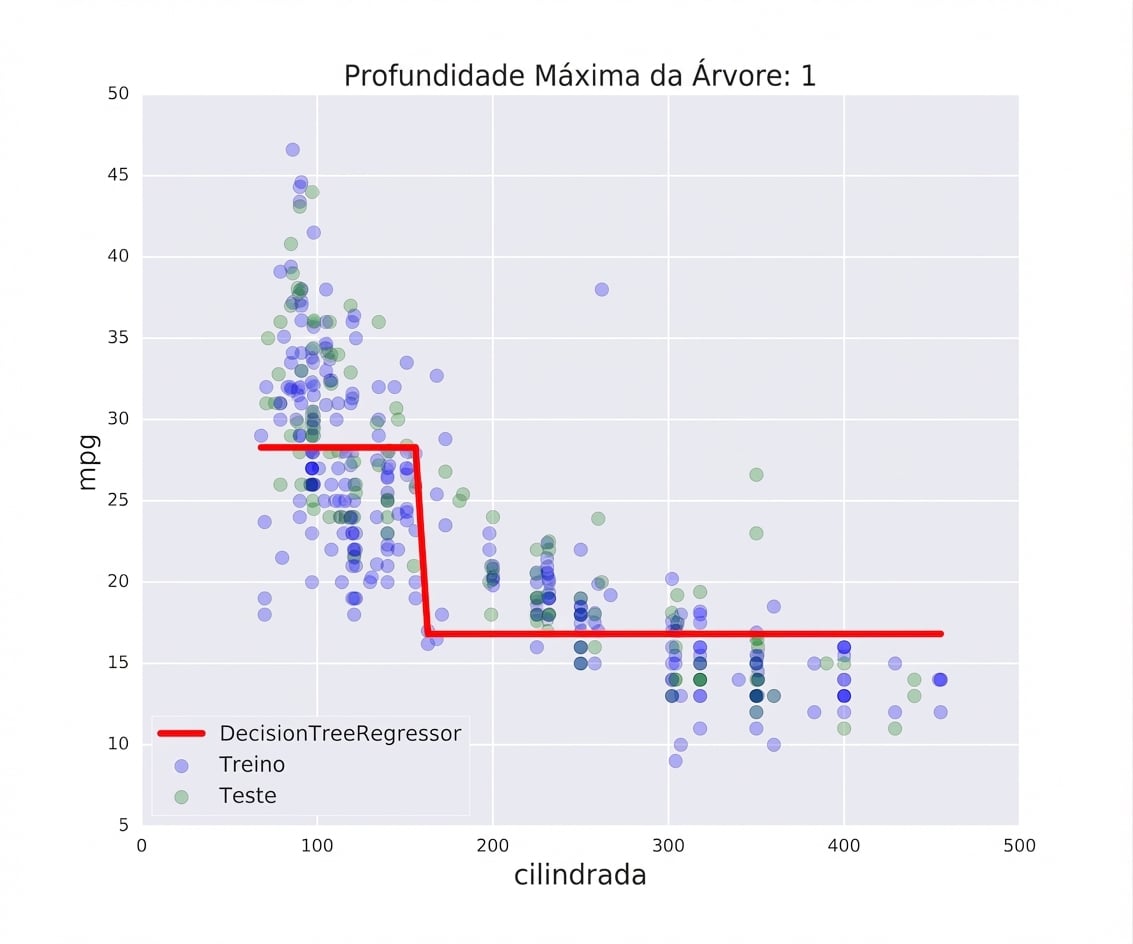
Underfitting
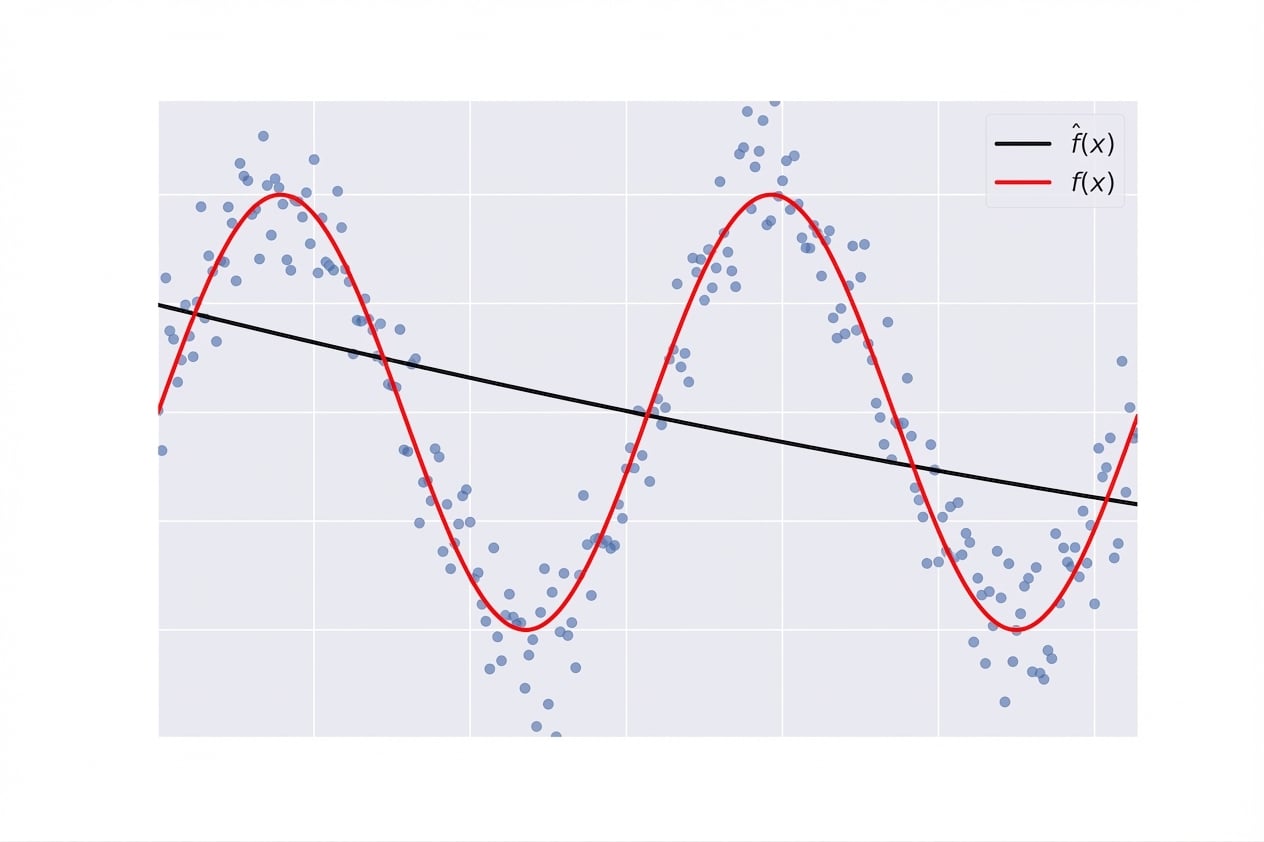
Viés
- Viés (bias): indica, em média, o quanto $\hat{f} \neq f$.
Variância
- Variância: mede o quanto $\hat{f}$ varia entre diferentes conjuntos de treino.
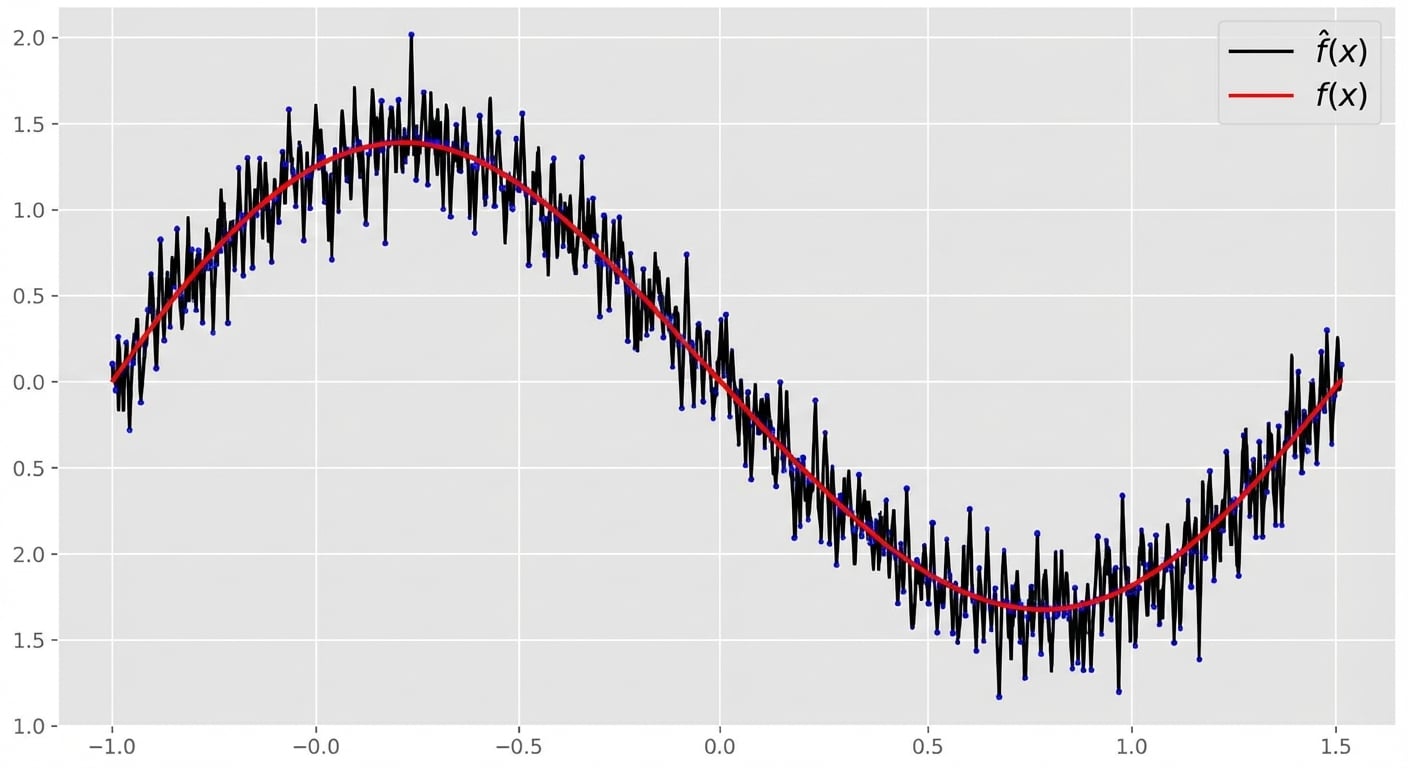
Trade-off viés–variância
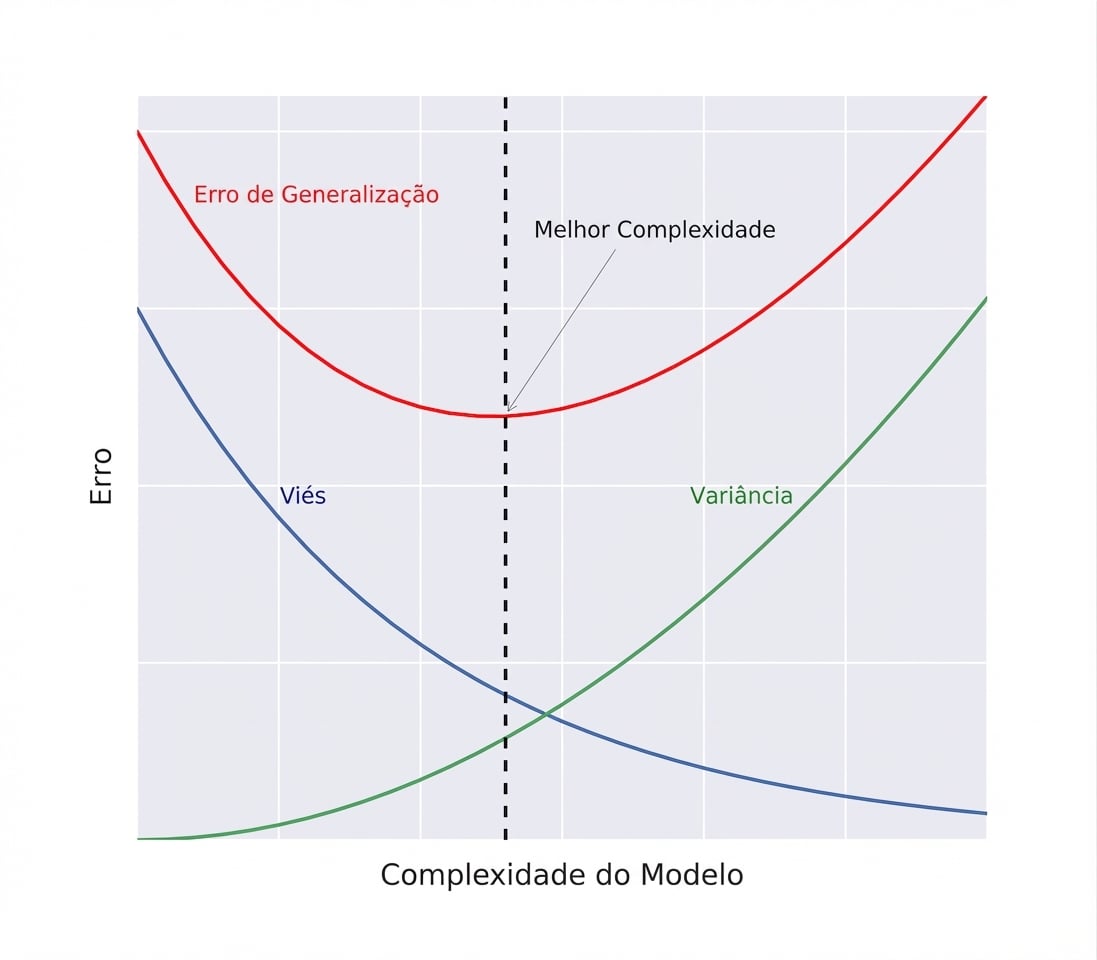
Trade-off viés–variância: explicação visual


