Aprendizado por conjunto
Aprendizado de máquina com modelos baseados em árvores em Python

Elie Kawerk
Data Scientist
Vantagens dos CARTs
Fácil de entender.
Fácil de interpretar.
Simples de usar.
Flexível: descreve dependências não lineares.
Pré-processamento: dispensa padronizar/normalizar features etc.
Limitações dos CARTs
Classificação: produz apenas fronteiras ortogonais.
Sensível a pequenas variações no treino.
Alta variância: CARTs sem restrição podem overfit no treino.
Solução: ensemble learning.
Aprendizado por conjunto
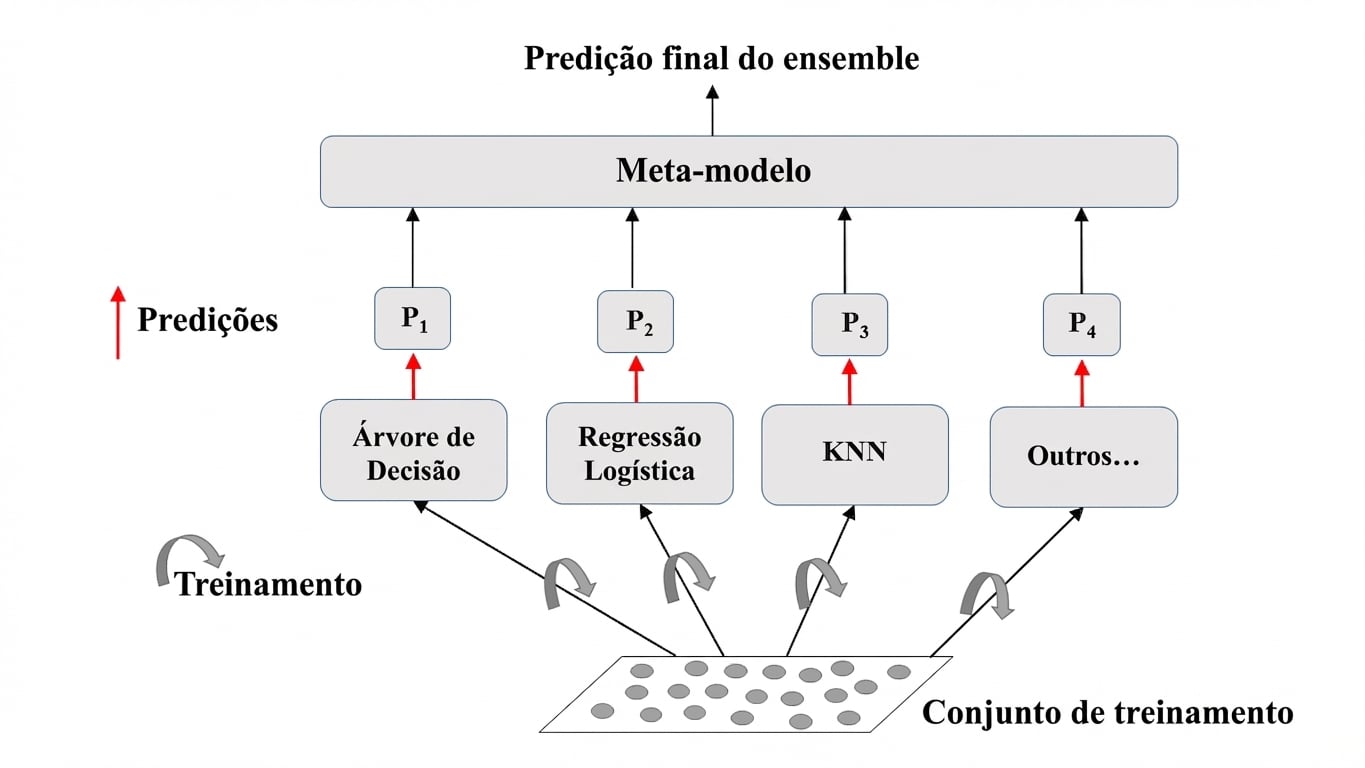
Treine modelos diferentes no mesmo dataset.
Cada modelo faz suas previsões.
Meta-modelo: agrega as previsões individuais.
Predição final: mais robusta e menos sujeita a erros.
Melhores resultados: modelos com habilidades complementares.
Ensemble: explicação visual
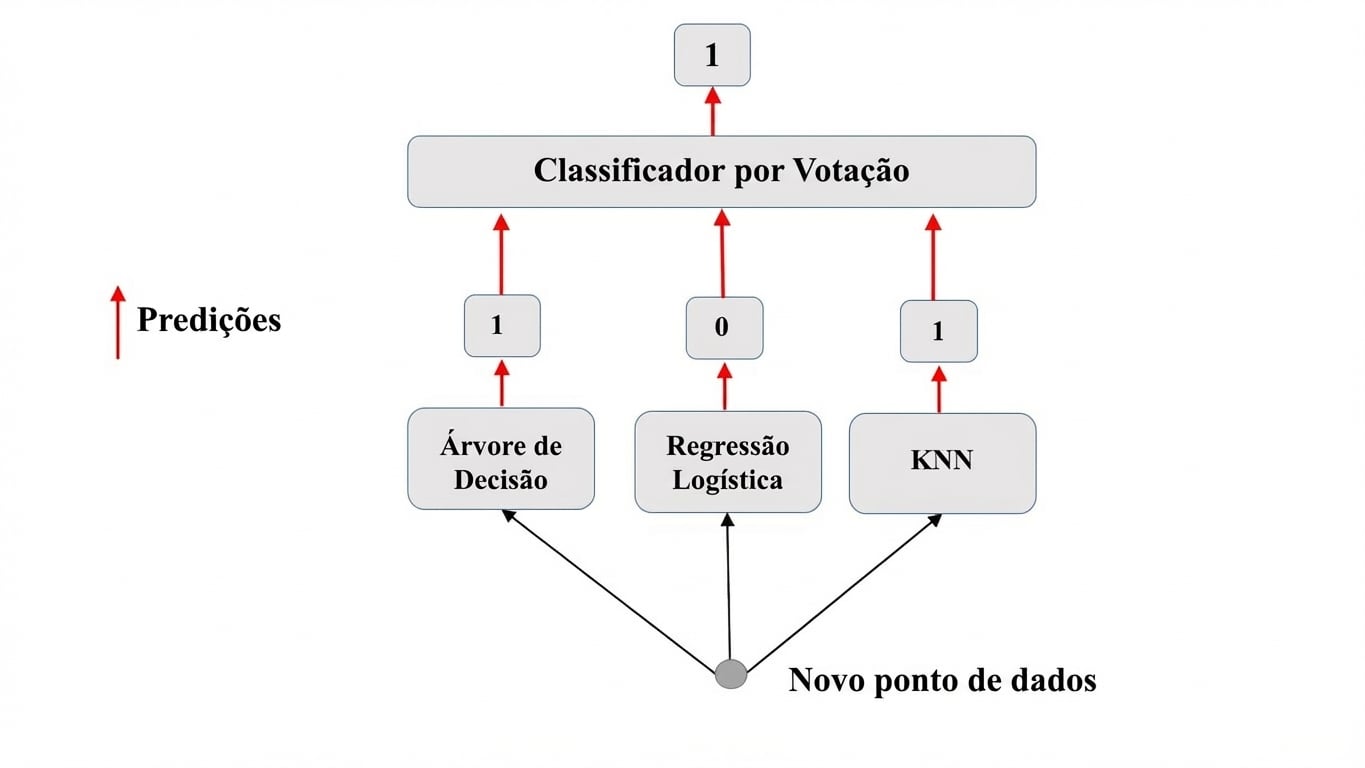
Ensemble na prática: VotingClassifier
Tarefa de classificação binária.
$N$ classificadores geram previsões: $P_1$, $P_2$, ..., $P_N$ com $P_i$ = 0 ou 1.
Predição do meta-modelo: voto duro.
Voto duro
VotingClassifier no sklearn (Breast-Cancer)
# Import functions to compute accuracy and split data
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# Import models, including VotingClassifier meta-model
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.ensemble import VotingClassifier
# Set seed for reproducibility
SEED = 1
VotingClassifier no sklearn (Breast-Cancer)
# Split data into 70% train and 30% test X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.3, random_state= SEED) # Instantiate individual classifiers lr = LogisticRegression(random_state=SEED) knn = KNN() dt = DecisionTreeClassifier(random_state=SEED)# Define a list called classifier that contains the tuples (classifier_name, classifier) classifiers = [('Logistic Regression', lr), ('K Nearest Neighbours', knn), ('Classification Tree', dt)]
# Iterate over the defined list of tuples containing the classifiers
for clf_name, clf in classifiers:
#fit clf to the training set
clf.fit(X_train, y_train)
# Predict the labels of the test set
y_pred = clf.predict(X_test)
# Evaluate the accuracy of clf on the test set
print('{:s} : {:.3f}'.format(clf_name, accuracy_score(y_test, y_pred)))
Logistic Regression: 0.947
K Nearest Neighbours: 0.930
Classification Tree: 0.930
VotingClassifier no sklearn (Breast-Cancer)
# Instantiate a VotingClassifier 'vc'
vc = VotingClassifier(estimators=classifiers)
# Fit 'vc' to the traing set and predict test set labels
vc.fit(X_train, y_train)
y_pred = vc.predict(X_test)
# Evaluate the test-set accuracy of 'vc'
print('Voting Classifier: {.3f}'.format(accuracy_score(y_test, y_pred)))
Voting Classifier: 0.953
Vamos praticar!
Aprendizado de máquina com modelos baseados em árvores em Python

