Árvore de decisão para classificação
Aprendizado de máquina com modelos baseados em árvores em Python

Elie Kawerk
Data Scientist
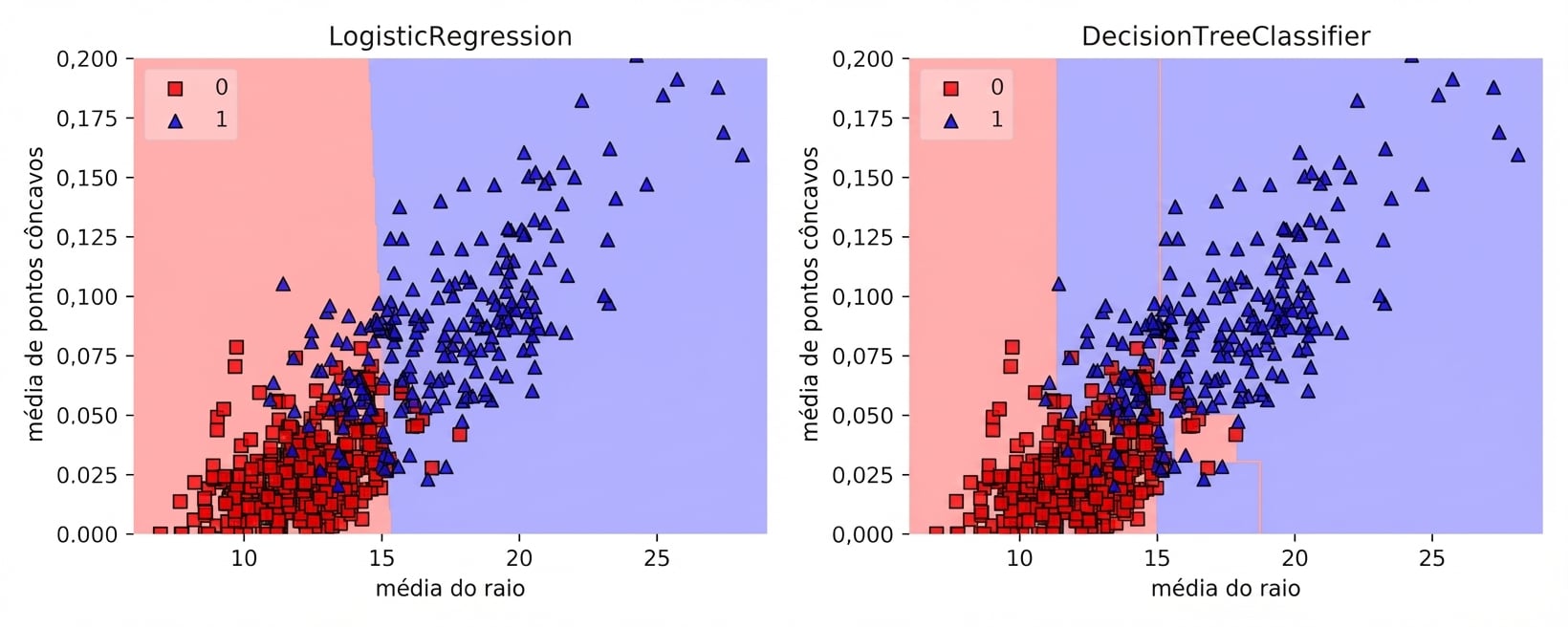
Breast Cancer em 2D
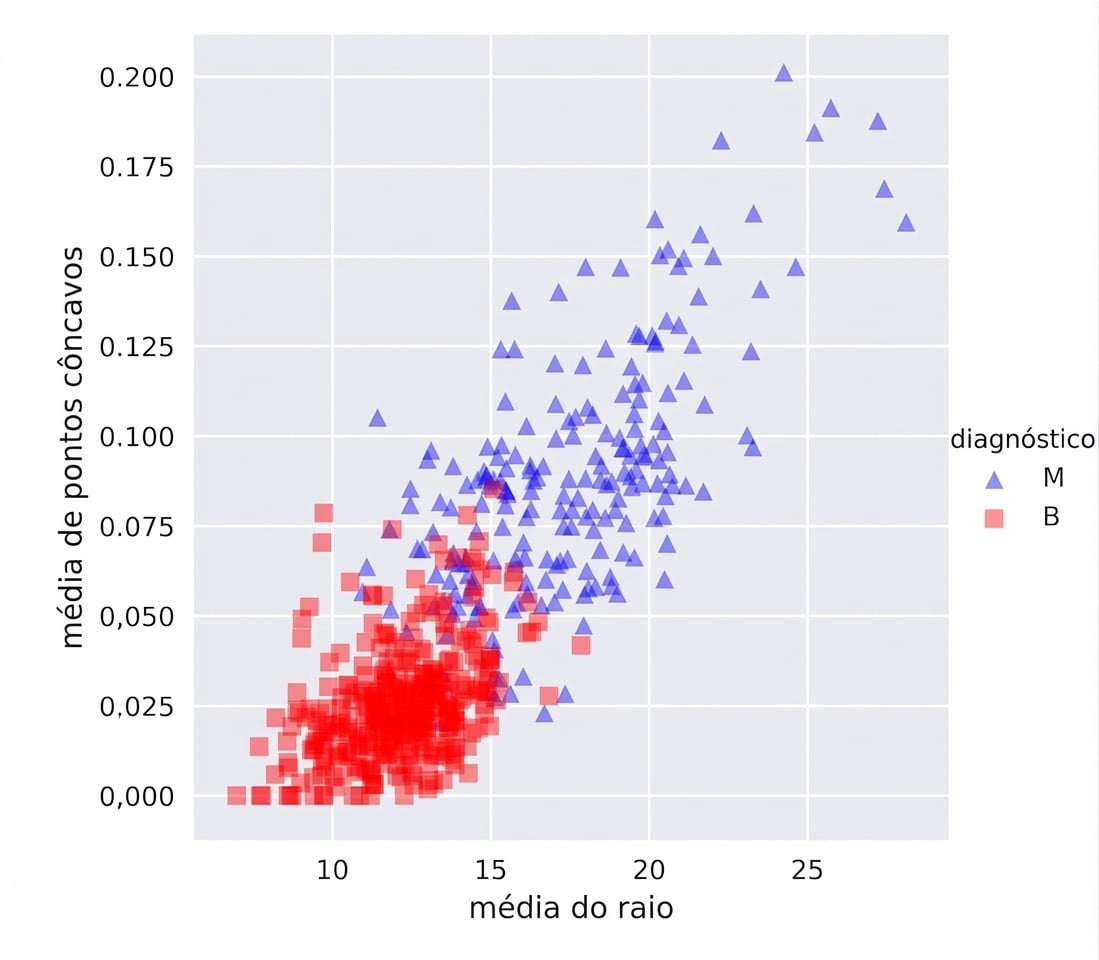
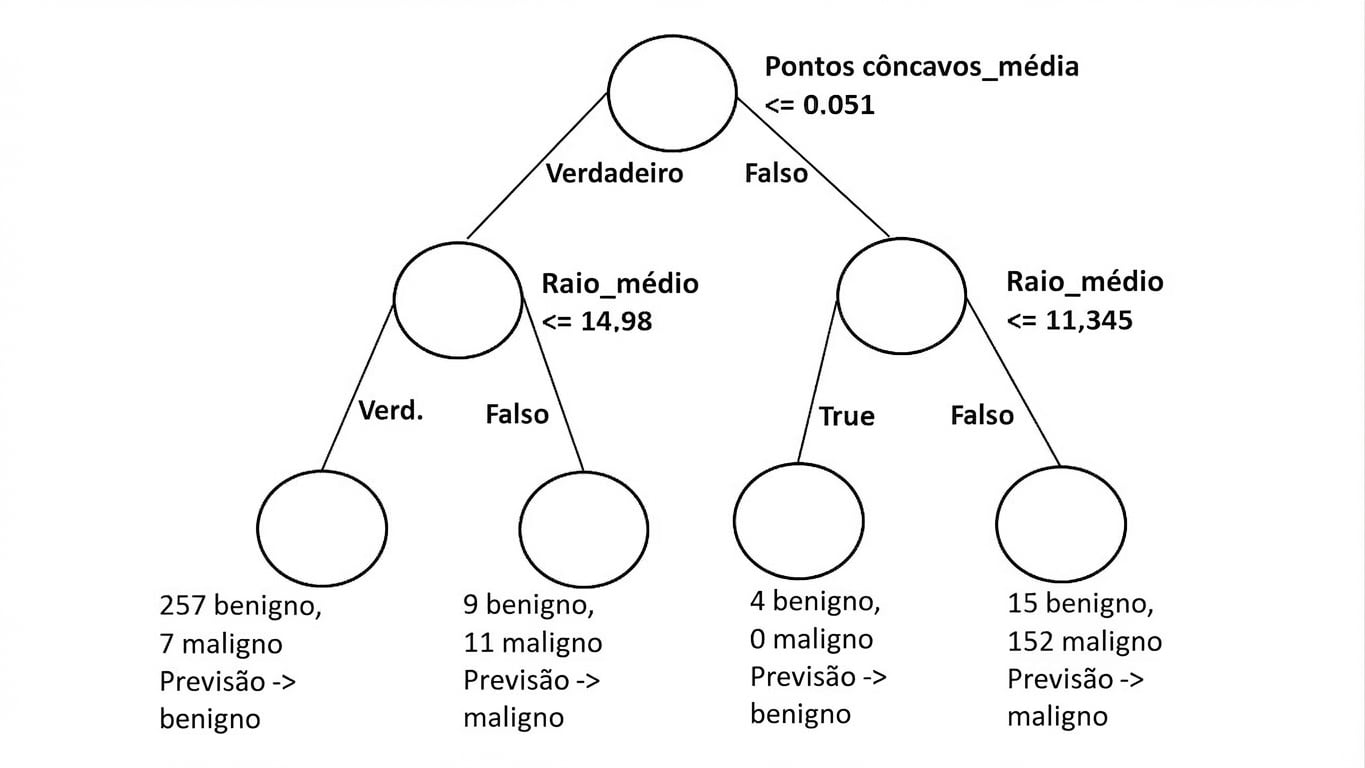
Diagrama de árvore de decisão
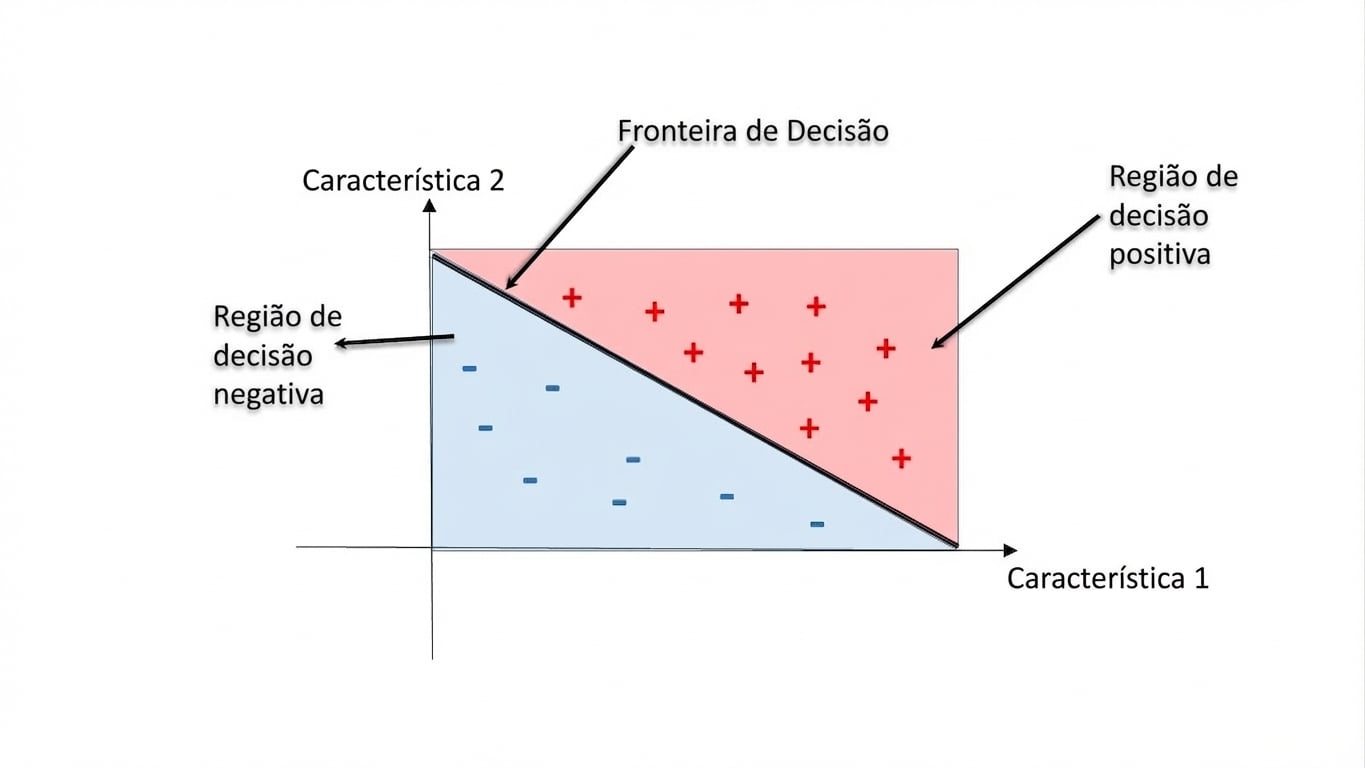
Regiões de decisão
Região de decisão: área no espaço de atributos onde todas as instâncias recebem o mesmo rótulo.
Fronteira de decisão: superfície que separa regiões de decisão.
Regiões: CART vs. modelo linear