Entendendo a otimização do modelo
Introdução a Deep Learning em Python

Dan Becker
Data Scientist and contributor to Keras and TensorFlow libraries
O problema do neurônio morto
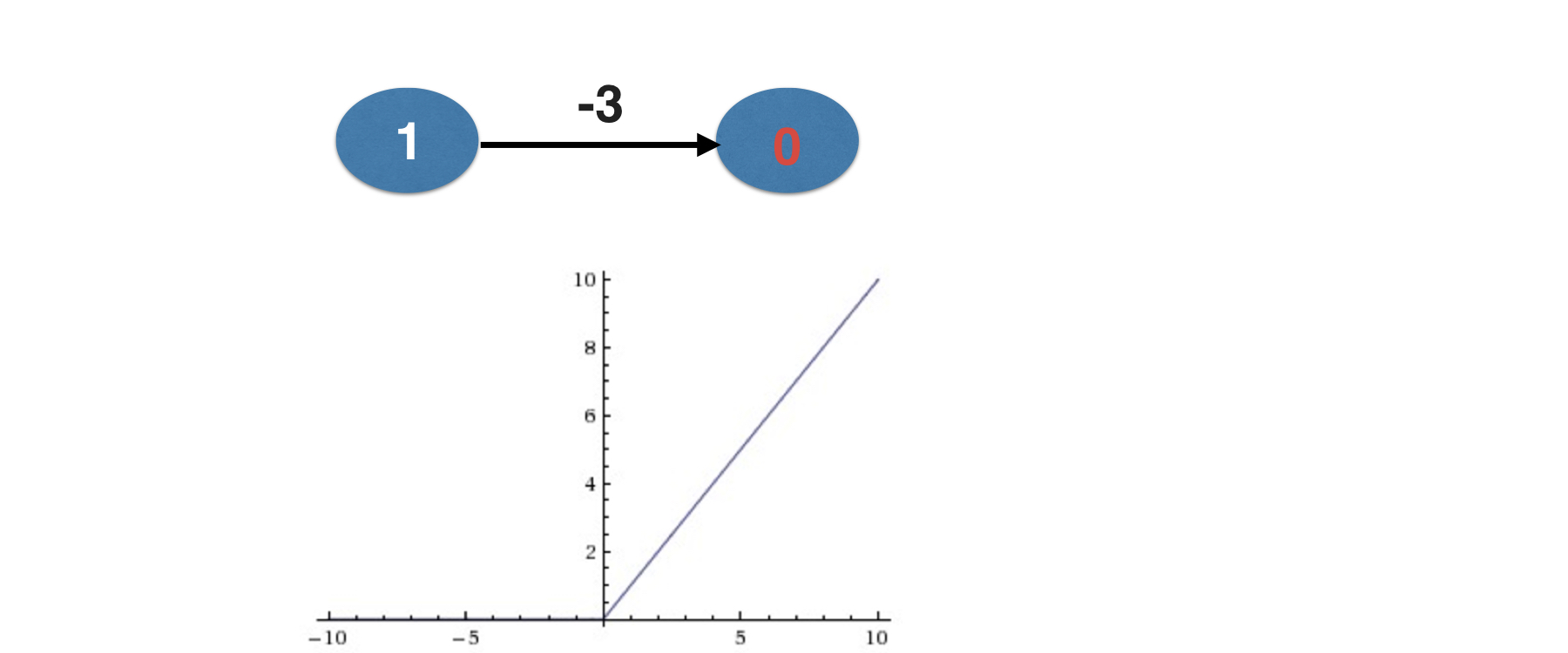
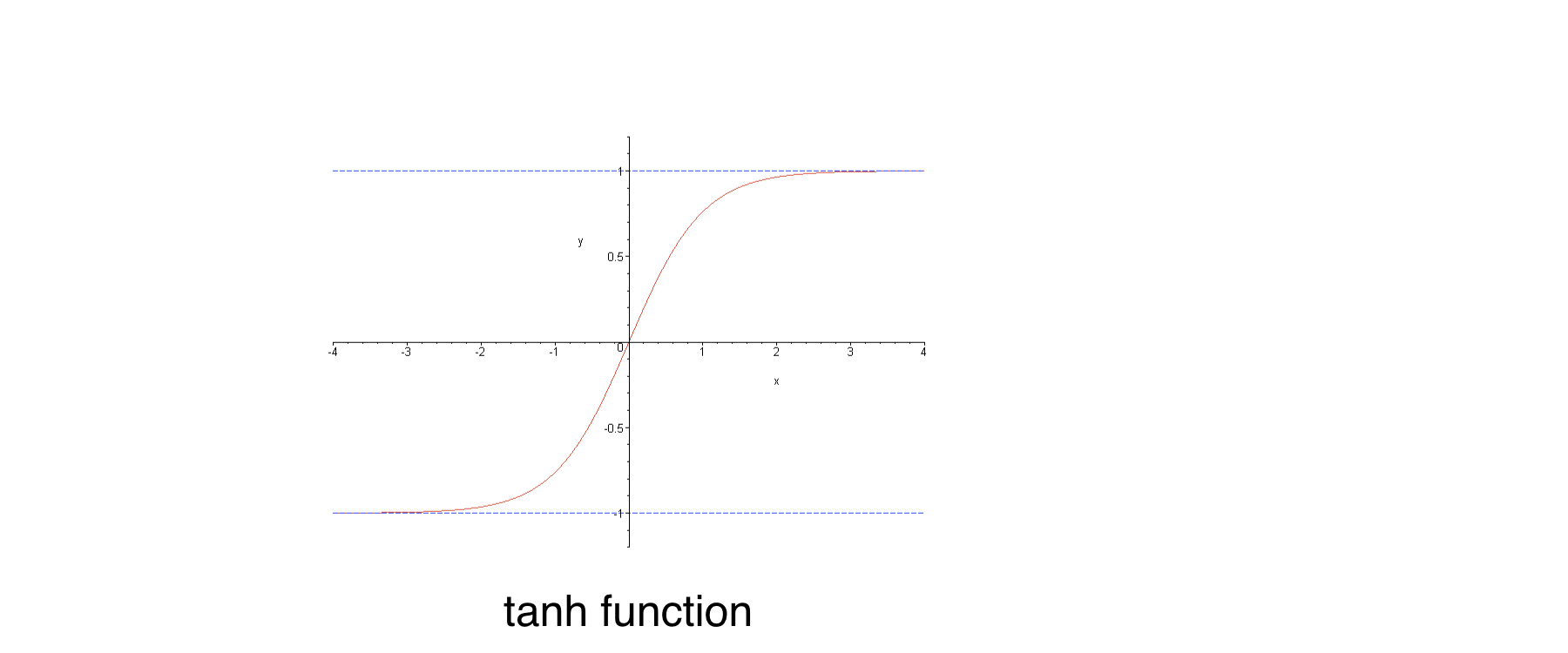
Gradientes desaparecendo
Introdução a Deep Learning em Python
Dan Becker
Data Scientist and contributor to Keras and TensorFlow libraries

