Hypothesis tests and z-scores
Teste de hipóteses em Python

James Chapman
Curriculum Manager, DataCamp
A/B testing

1 Image credit: "Electronic Arts" by majaX1 CC BY-NC-SA 2.0
Retail webpage A/B test
Control:

Treatment:
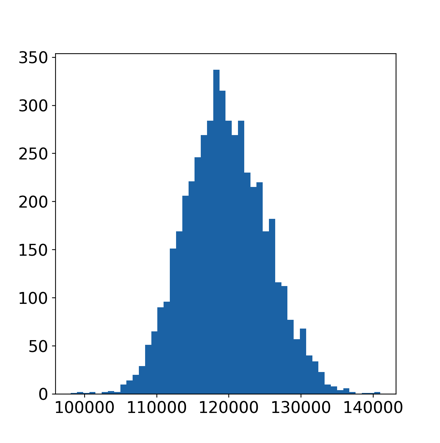
Visualizing the bootstrap distribution
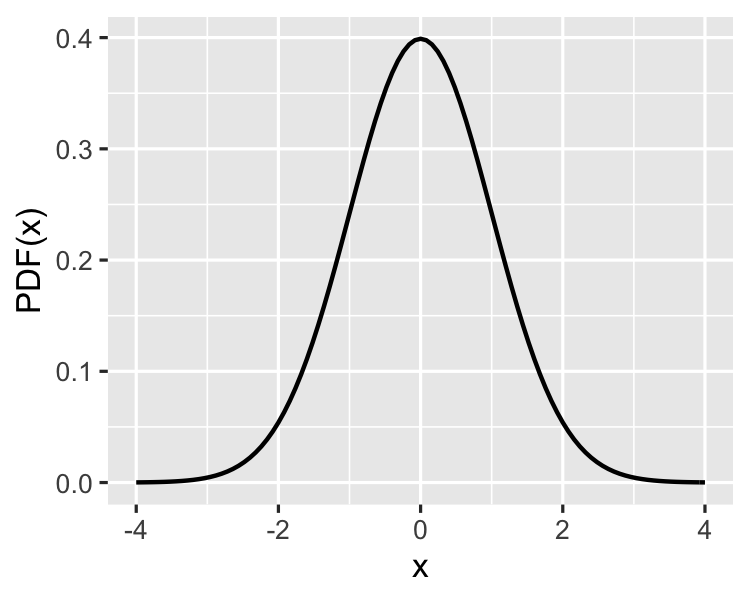
Standard normal (z) distribution
Standard normal distribution: normal distribution with mean = 0 + standard deviation = 1