Introduction to deep Q learning
Deep Reinforcement Learning in Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
What is Deep Q Learning?
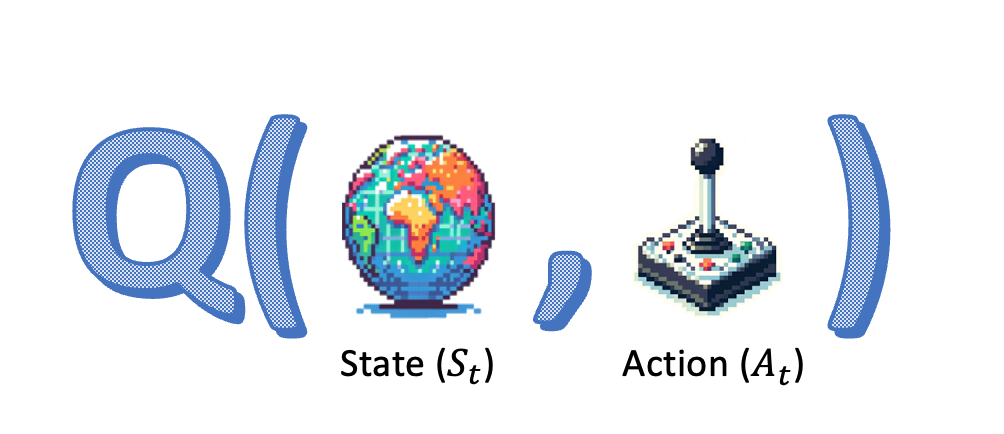
Q-Learning refresher

Q-Learning refresher


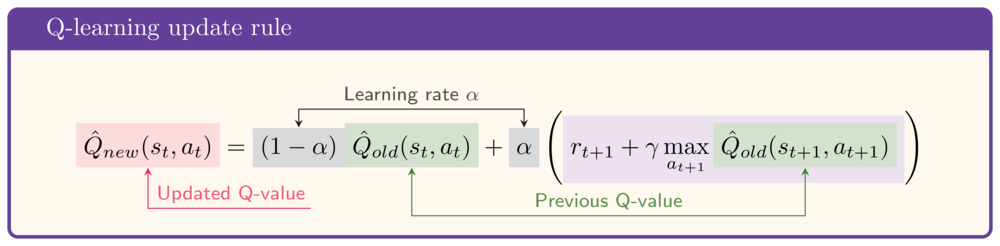
- Bellman equation: recursive formula for $Q$
- Right side of Bellman Equation: "TD-target"
- Use TD-target from Bellman Equation to update $\hat{Q}$ after each step
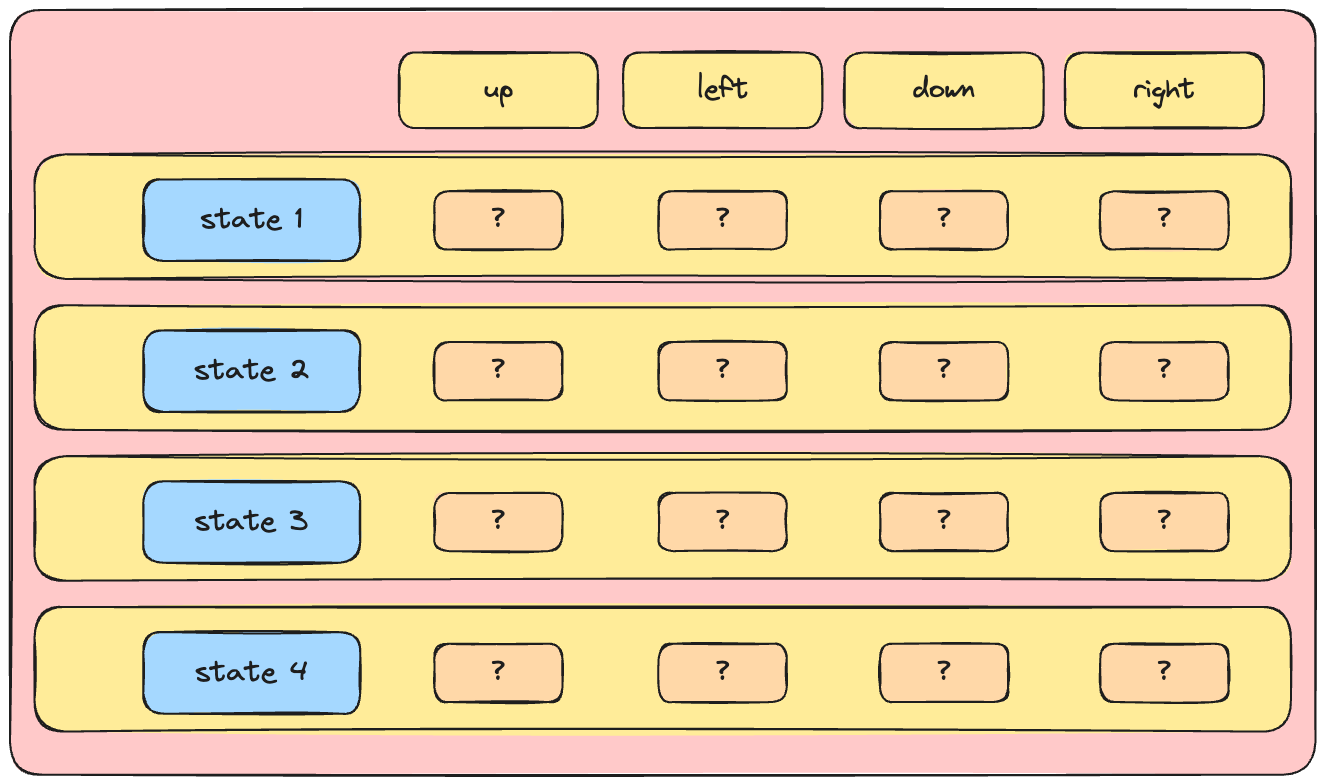
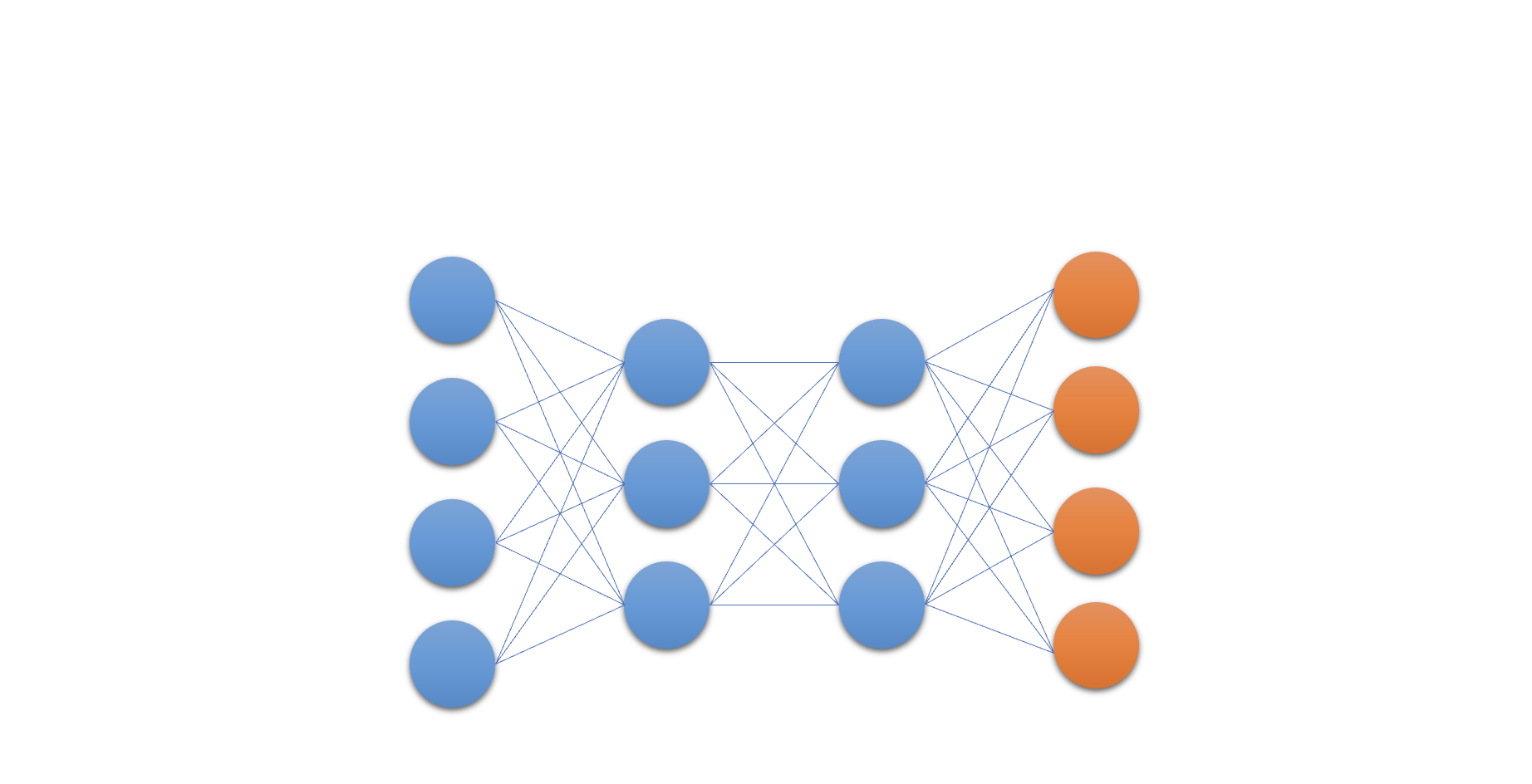
The Q-Network
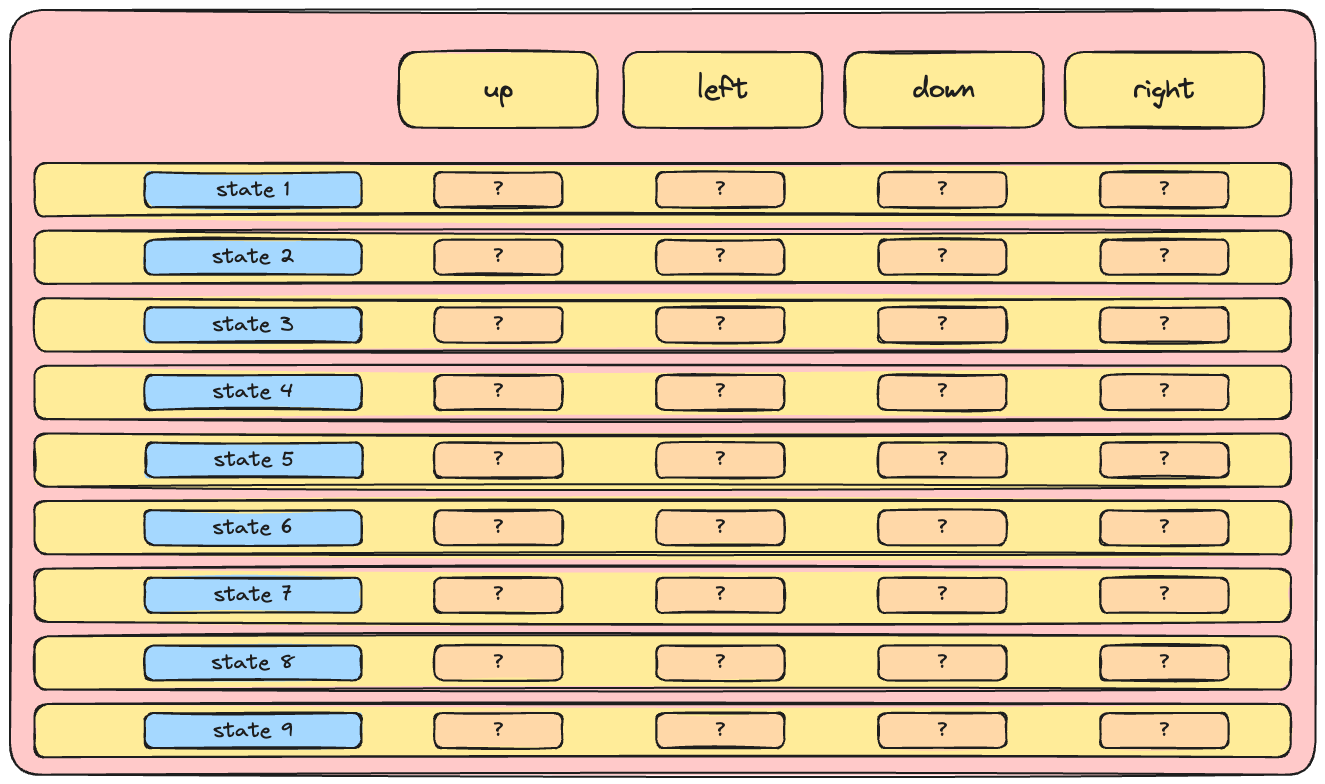
The Q-Network
The Q-Network
The Q-Network
- At the heart of Deep Q Learning: a neural network
The Q-Network
- At the heart of Deep Q Learning: a neural network
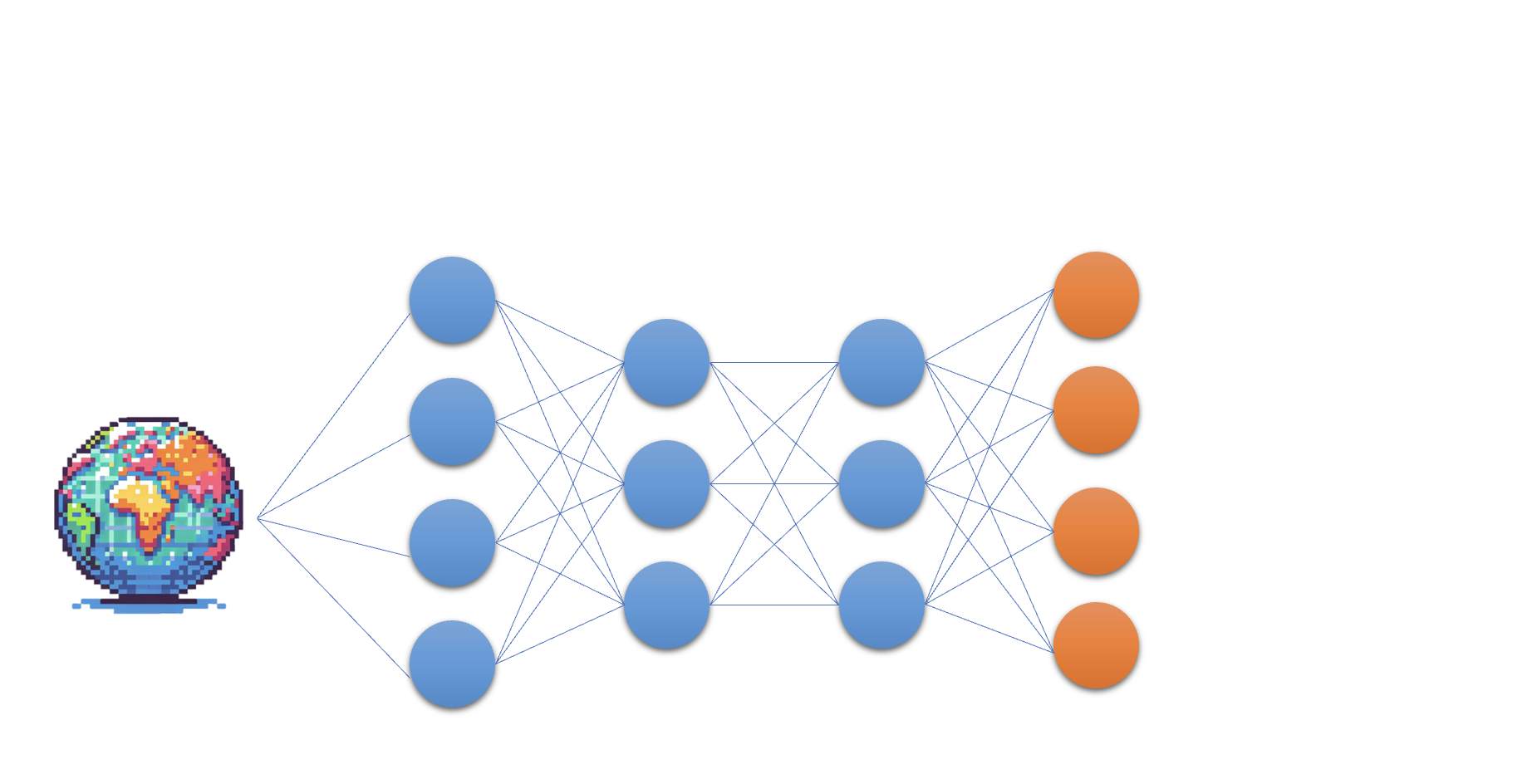
The Q-Network
- At the heart of Deep Q Learning: a neural network mapping state to Q-values
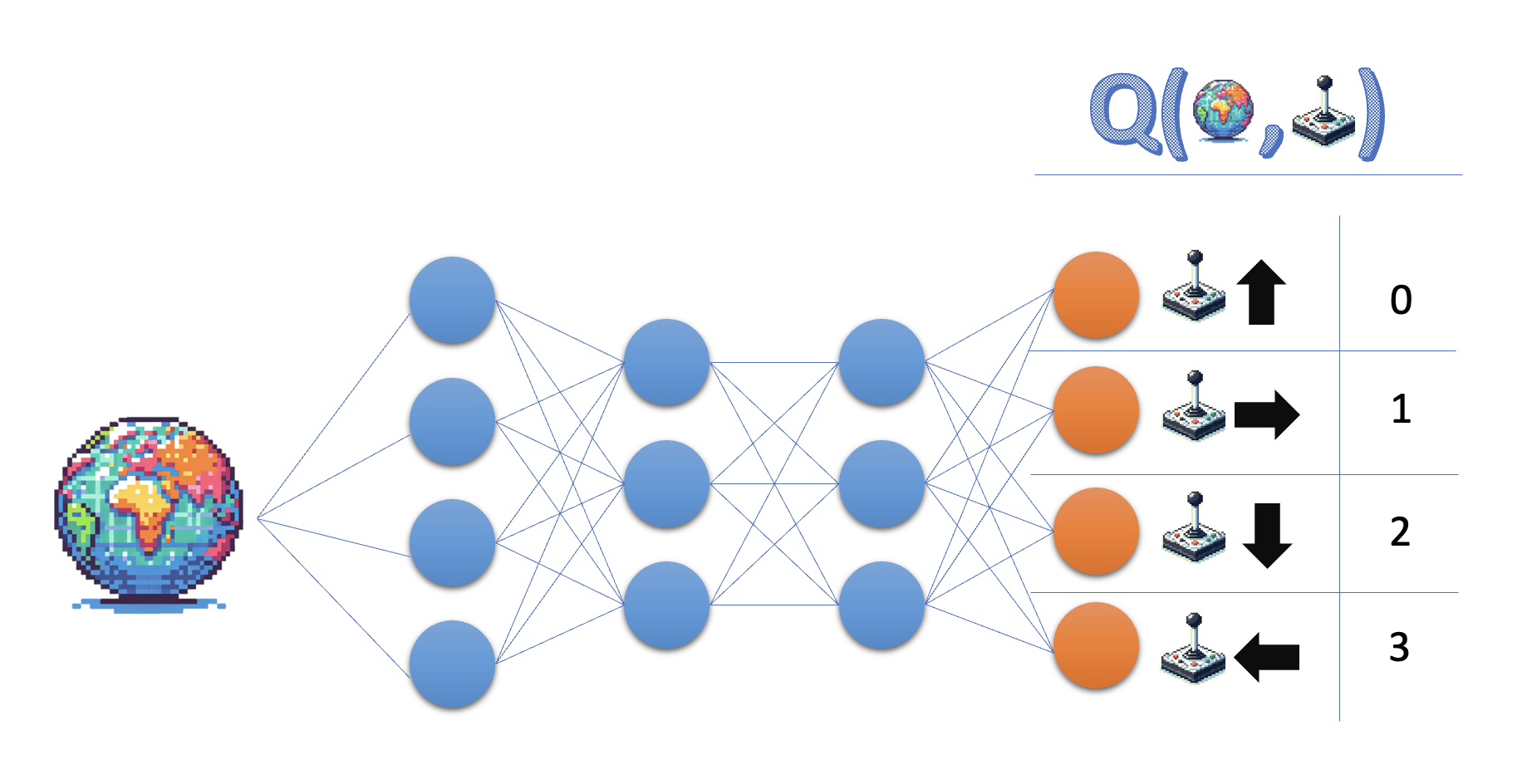
- A network approximating the action-value function is called 'Q-network'
- Q-networks are commonly used in Deep Q Learning algorithms, such as DQN.

