The complete DQN algorithm
Deep Reinforcement Learning in Python

Timothée Carayol
Principal Machine Learning Engineer, Komment
The DQN algorithm


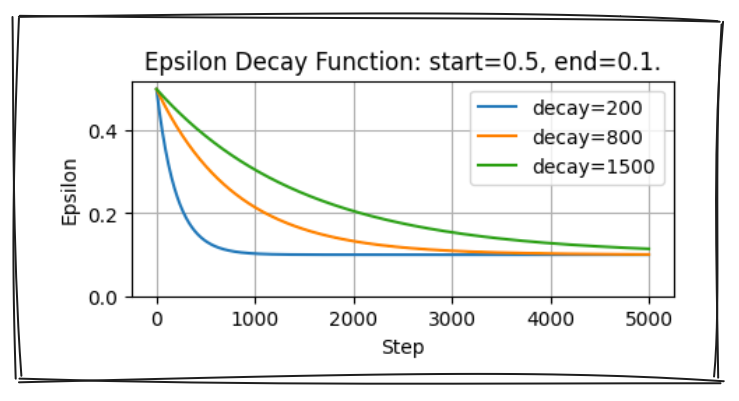
Epsilon-greediness in the DQN algorithm
- $\varepsilon = end + (start-end) \cdot e^{-\frac{step}{decay}}$
- Take random action with probability $\varepsilon$
- Take highest value action with probability $1 - \varepsilon$
Fixed Q-targets

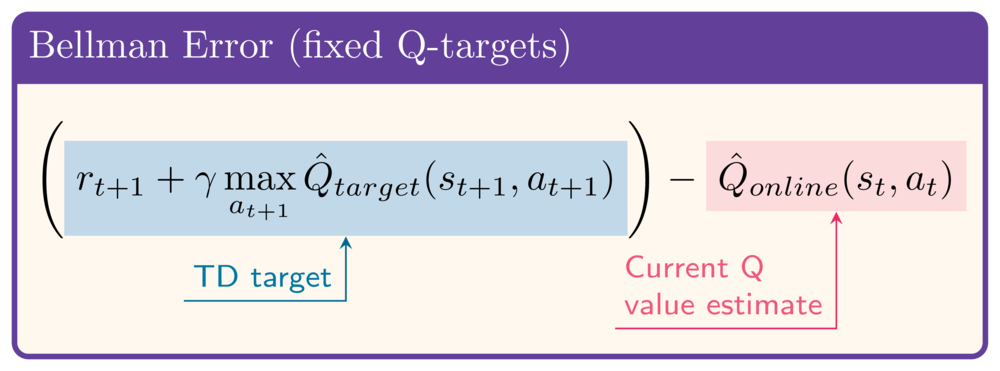
Implementing fixed Q-targets
- Initially Online Network = Target Network
- A network's state dict contains all weights:

- Each step, every weight of Target Network gets a bit closer to Online Network

