Erros padrão e o Teorema Central do Limite
Amostragem em Python

James Chapman
Curriculum Manager, DataCamp
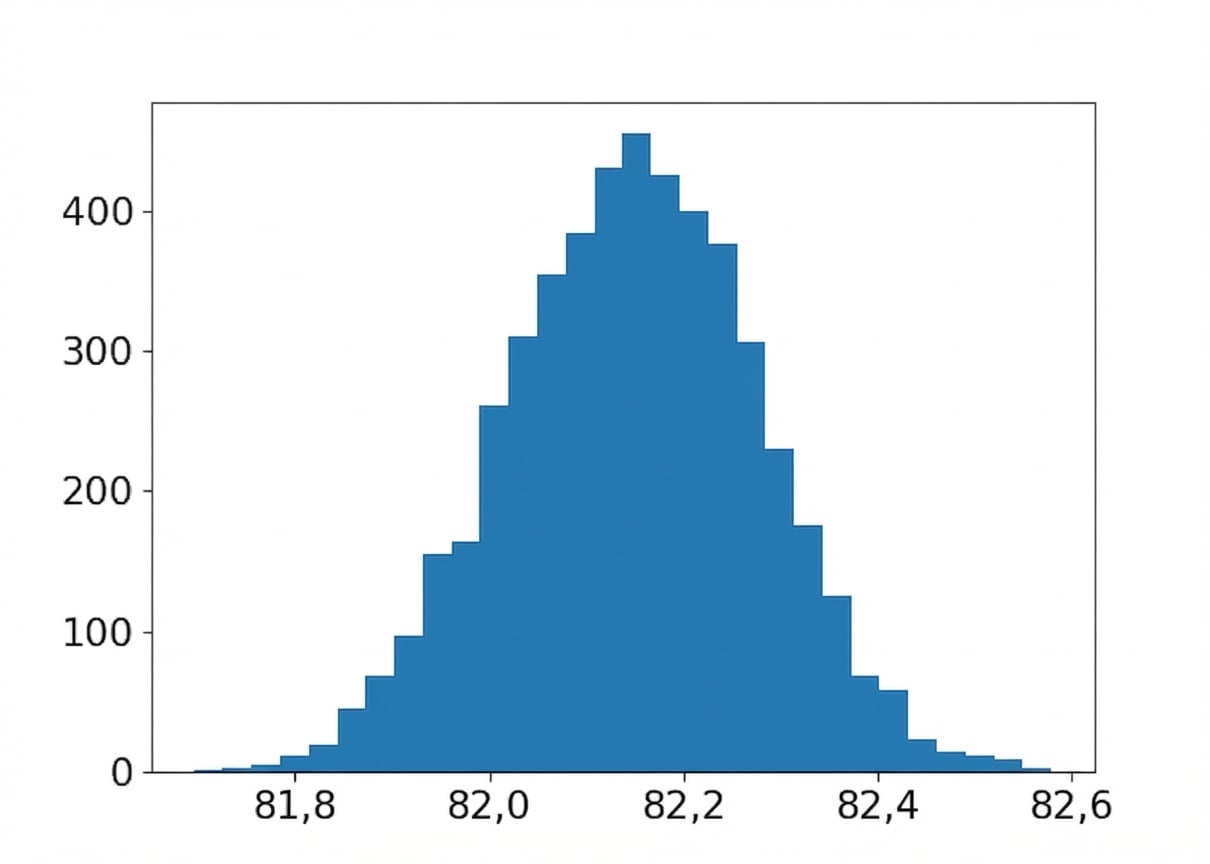
Distribuição amostral dos pontos médios da xícara
Tamanho da amostra: 5
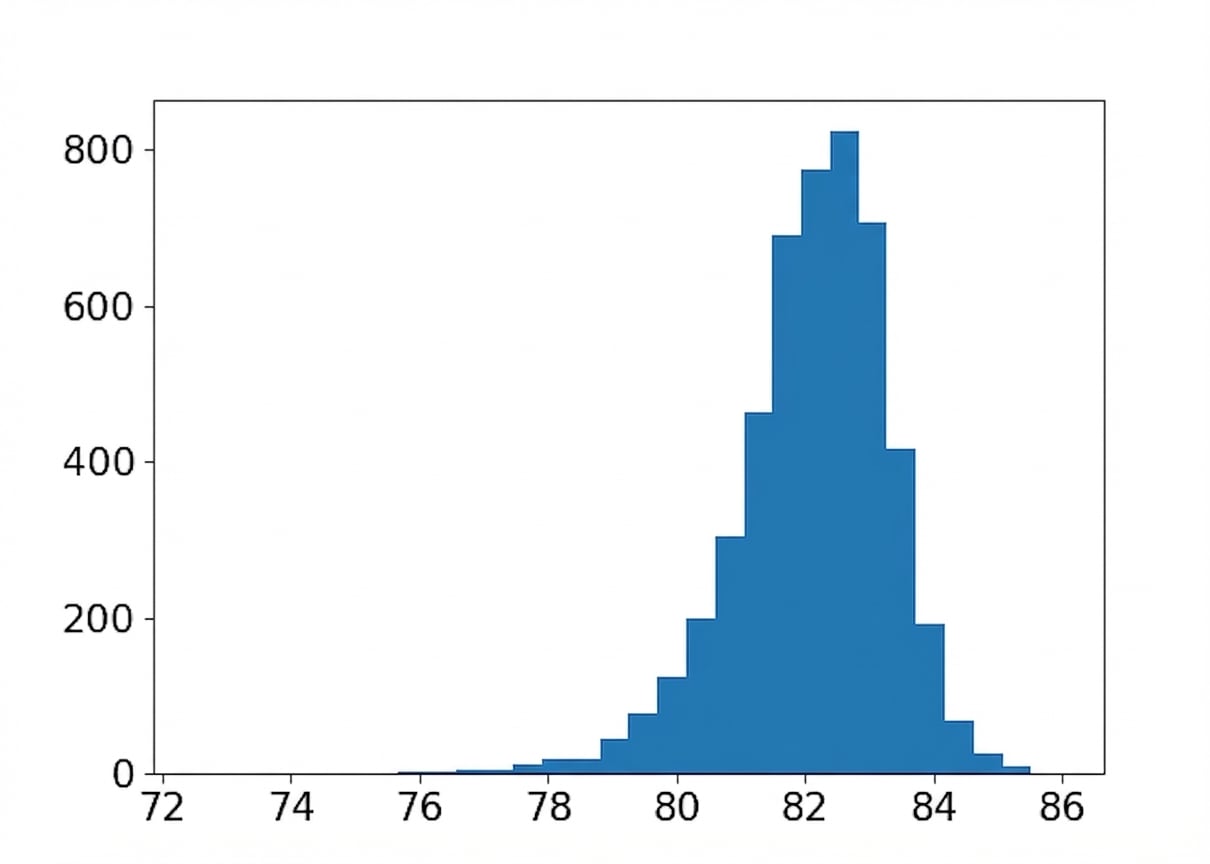
Tamanho da amostra: 20
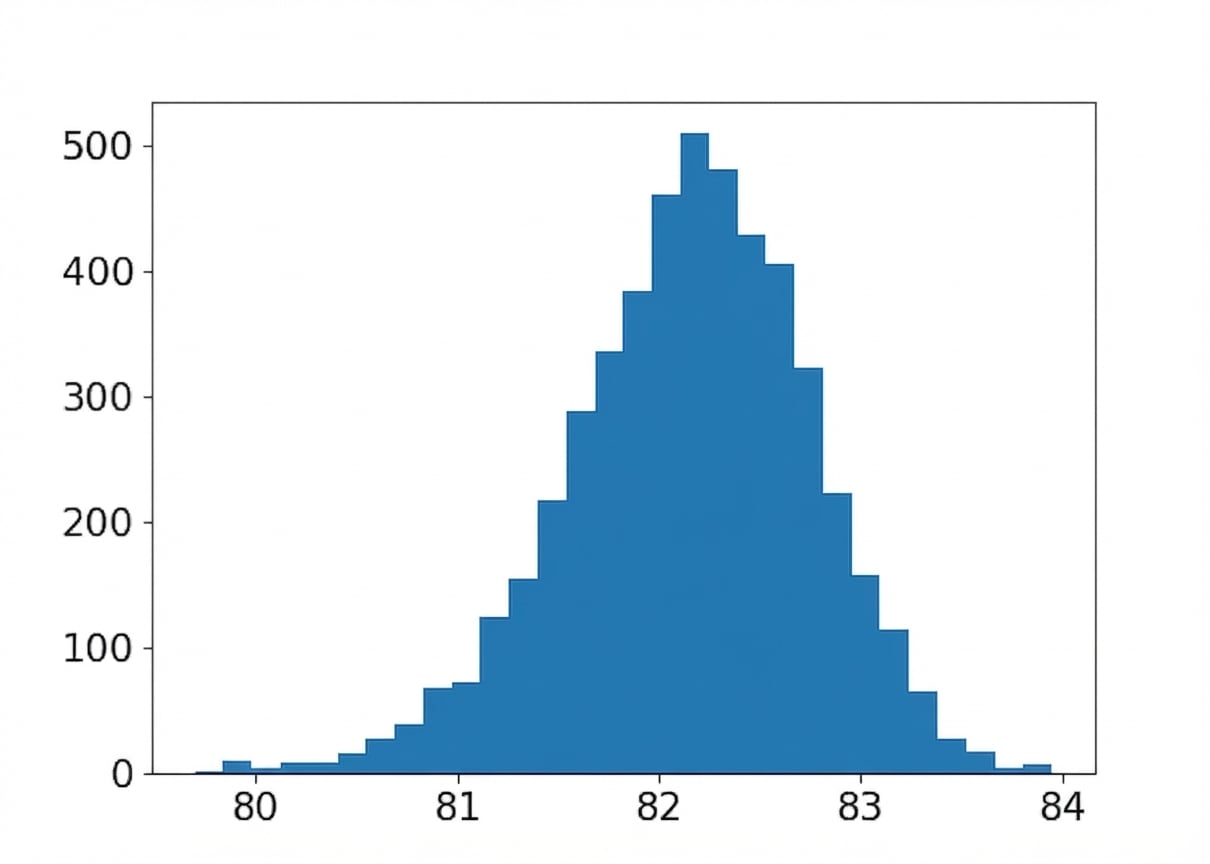
Tamanho da amostra: 80
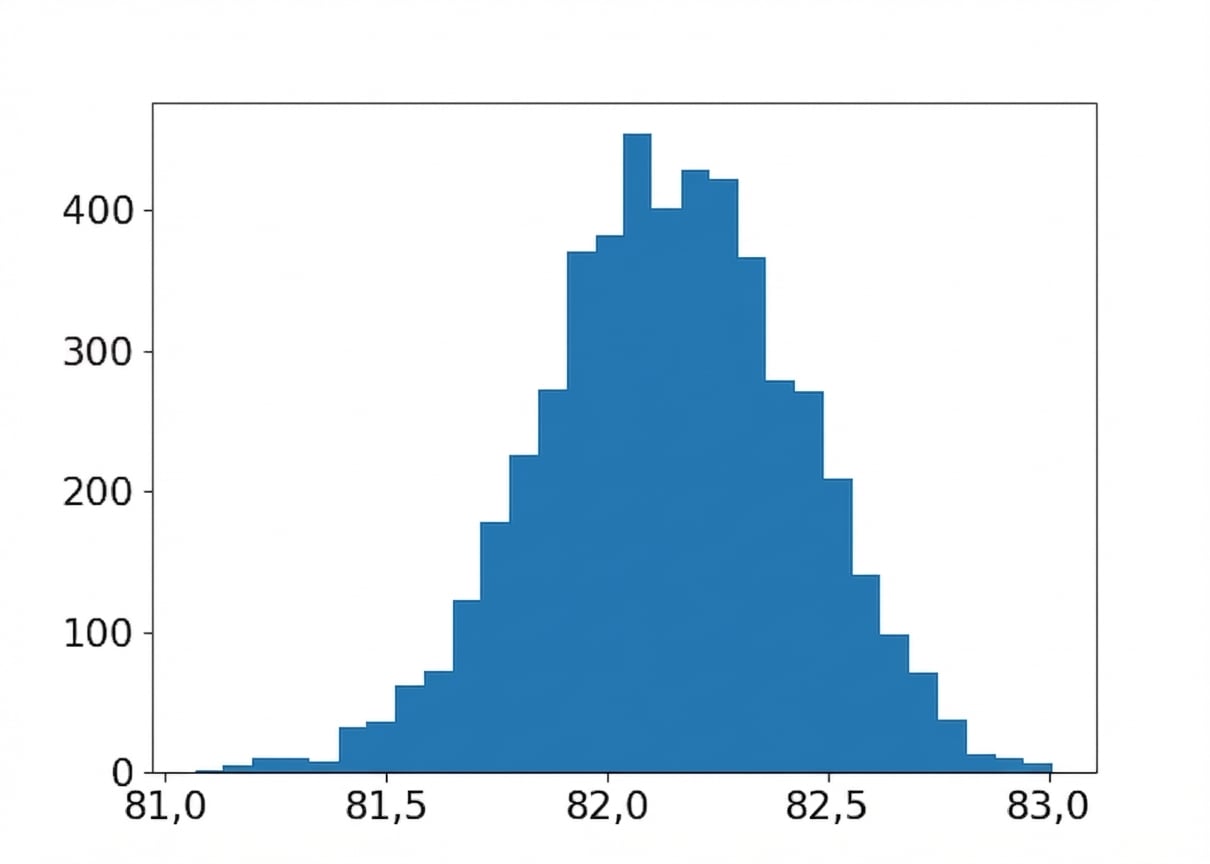
Tamanho da amostra: 320