Comparando distribuições de amostragem e bootstrap
Amostragem em Python

James Chapman
Curriculum Manager, DataCamp
Subconjunto focado em café
coffee_sample = coffee_ratings[["variety", "country_of_origin", "flavor"]]\
.reset_index().sample(n=500)
index variety country_of_origin flavor
132 132 Other Costa Rica 7.58
51 51 None United States (Hawaii) 8.17
42 42 Yellow Bourbon Brazil 7.92
569 569 Bourbon Guatemala 7.67
.. ... ... ... ...
643 643 Catuai Costa Rica 7.42
356 356 Caturra Colombia 7.58
494 494 None Indonesia 7.58
169 169 None Brazil 7.81
[500 rows x 4 columns]
Bootstrap da média do sabor do café
import numpy as np
mean_flavors_5000 = []
for i in range(5000):
mean_flavors_5000.append(
np.mean(coffee_sample.sample(frac=1, replace=True)['flavor'])
)
bootstrap_distn = mean_flavors_5000
Distribuição bootstrap da média do sabor
import matplotlib.pyplot as plt
plt.hist(bootstrap_distn, bins=15)
plt.show()
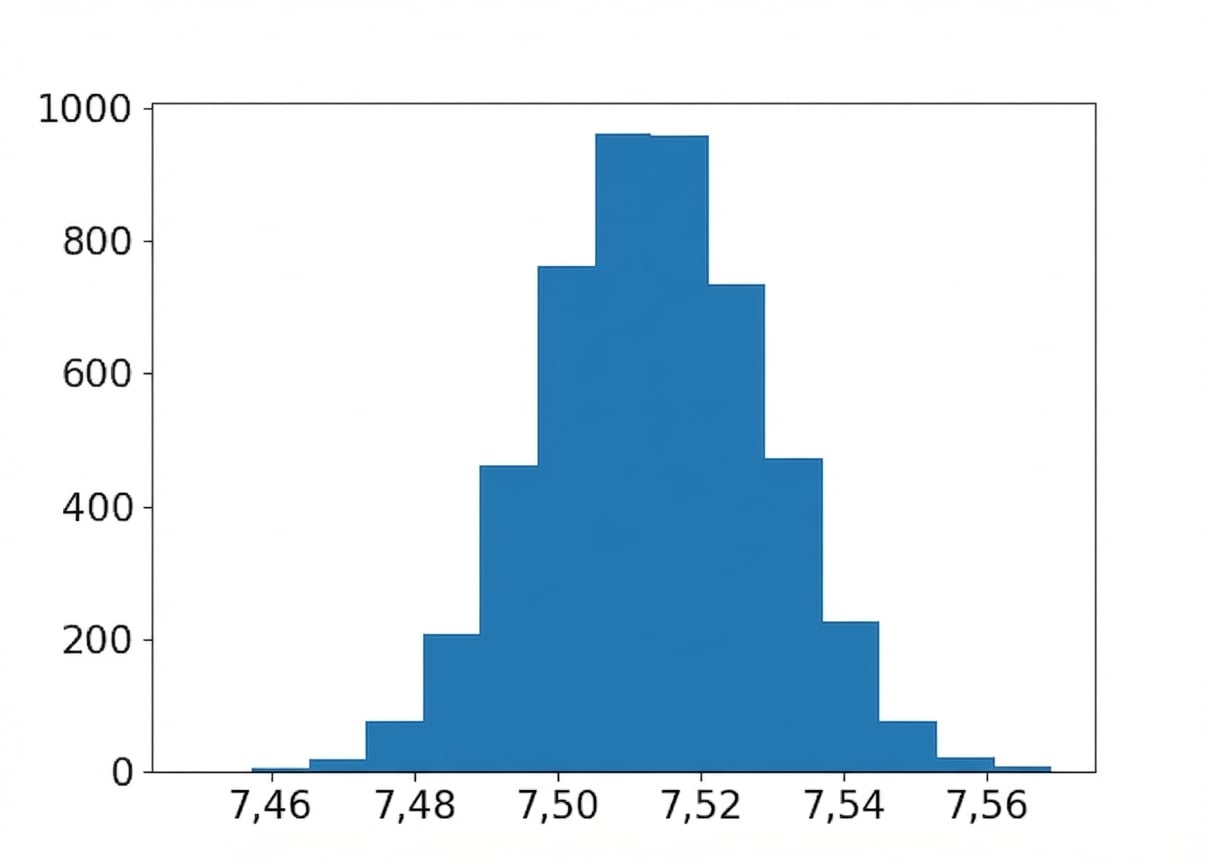
Médias: amostra, dist. bootstrap e população
Média da amostra:
coffee_sample['flavor'].mean()
7.5132200000000005
Média populacional estimada:
np.mean(bootstrap_distn)
7.513357731999999
Média populacional verdadeira:
coffee_ratings['flavor'].mean()
7.526046337817639
Interpretando as médias
Média da distribuição bootstrap:
- Geralmente perto da média da amostra
- Pode não estimar bem a média da população
Bootstrap não corrige vieses da amostragem
DP da amostra vs. DP da distribuição bootstrap
Desvio padrão da amostra:
coffee_sample['flavor'].std()
0.3540883911928703
Estimativa do desvio padrão populacional?
np.std(bootstrap_distn, ddof=1)
0.015768474367958217
DPs: amostra, dist. bootstrap e população
Desvio padrão da amostra:
coffee_sample['flavor'].std()
0.3540883911928703
Desvio padrão populacional estimado:
standard_error = np.std(bootstrap_distn, ddof=1)
Erro padrão é o desvio padrão da estatística de interesse
Desvio padrão verdadeiro:
coffee_ratings['flavor'].std(ddof=0)
0.34125481224622645
standard_error * np.sqrt(500)
0.3525938058821761
Erro padrão vezes a raiz quadrada do tamanho da amostra estima o desvio padrão populacional
Interpretando os erros padrão
- Erro padrão estimado → desvio padrão da distribuição bootstrap de uma estatística amostral
- $\text{DP populacional} \approx \text{Erro padrão} \times \sqrt{\text{Tamanho da amostra}}$
Vamos praticar!
Amostragem em Python

