Amostragem em Python
James Chapman
Curriculum Manager, DataCamp
Um censo pergunta a cada domicílio quantas pessoas moram ali.
Censos são bem caros!
É mais barato perguntar a poucas casas e usar estatística para estimar a população
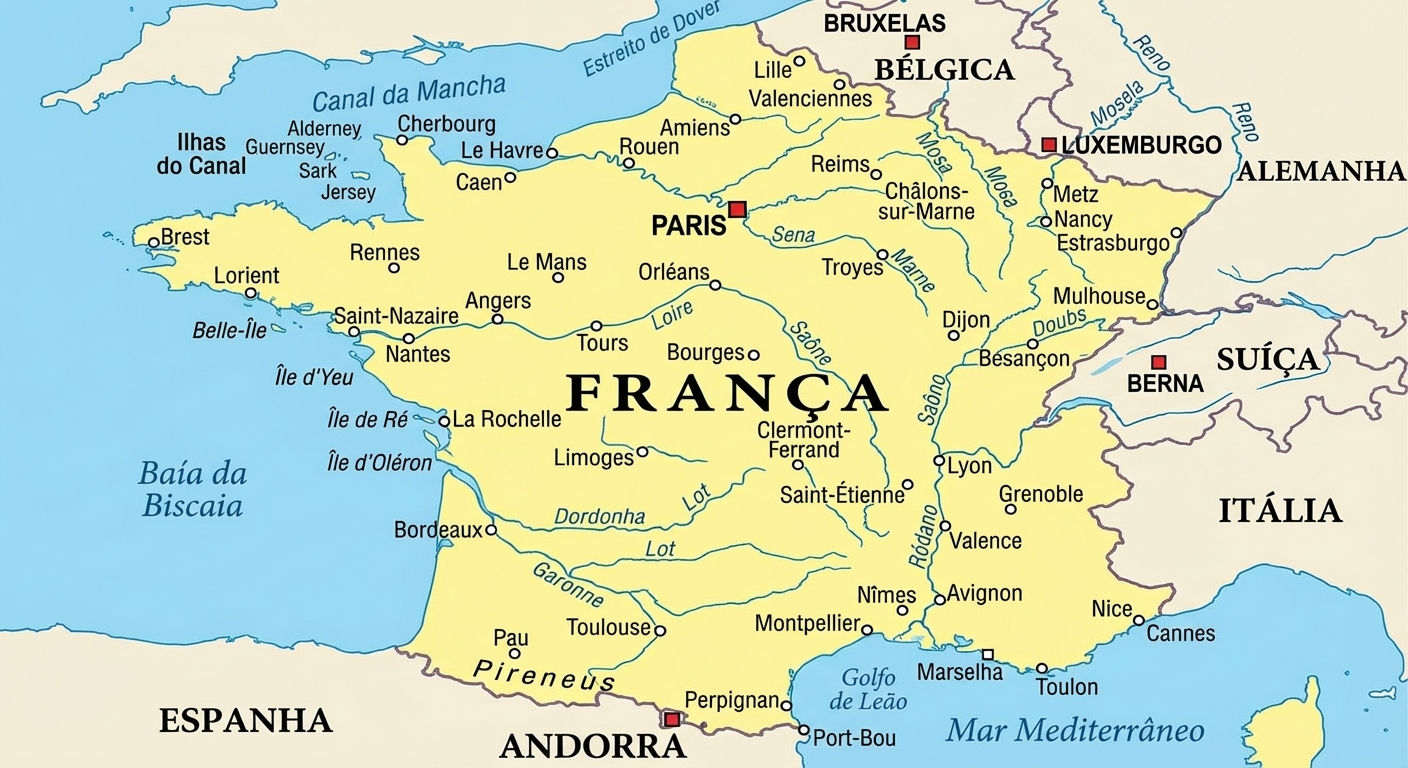
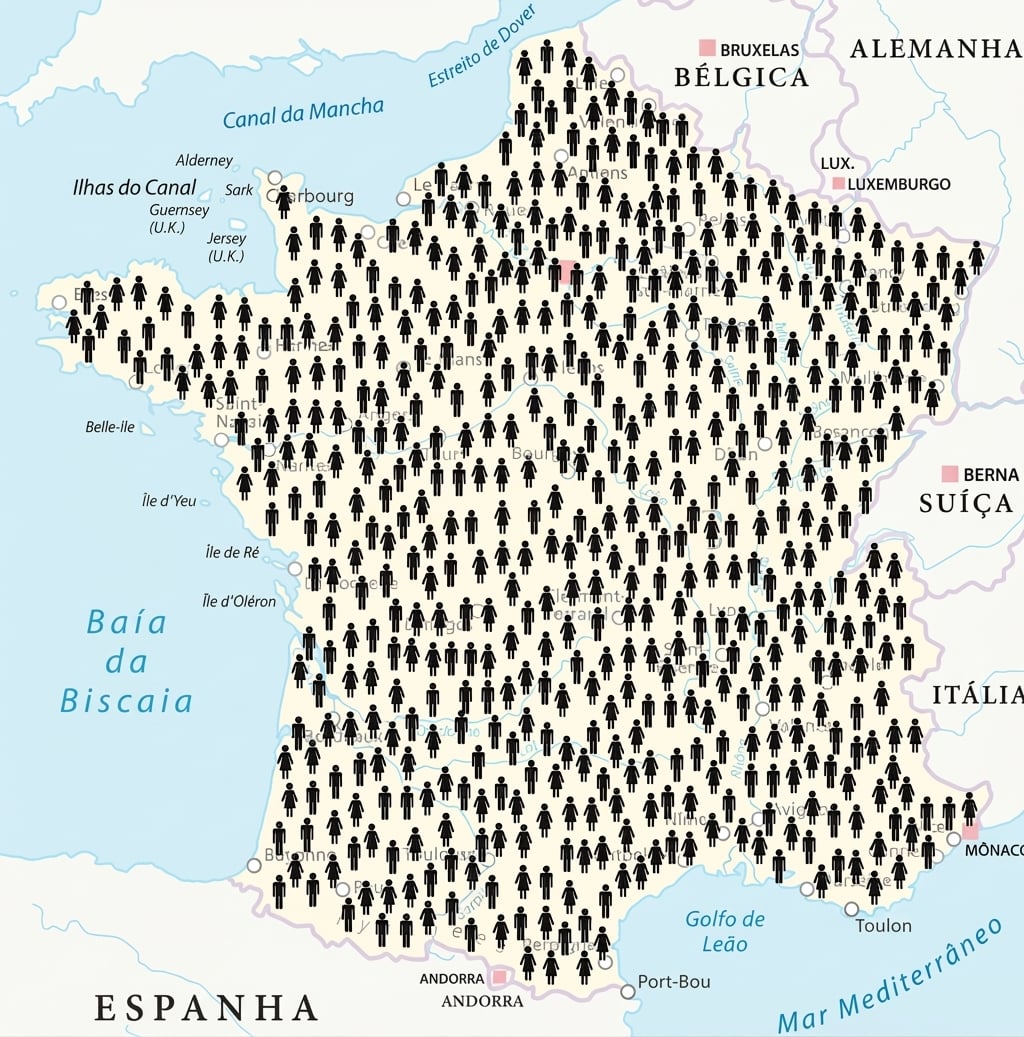
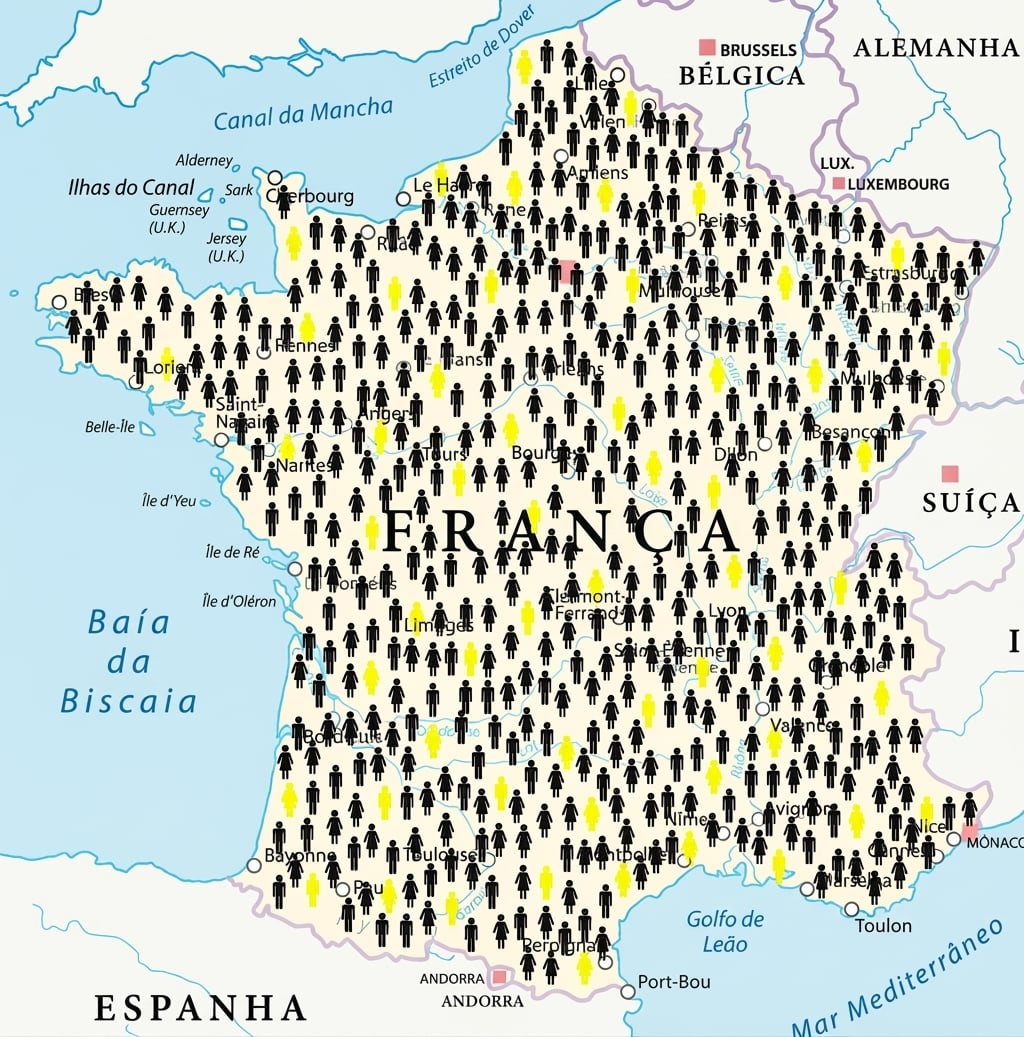
Trabalhar com um subconjunto da população inteira se chama amostragem
A população é o conjunto completo de dados
A amostra é o subconjunto em que você calcula
pts_vs_flavor_pop = coffee_ratings[["total_cup_points", "flavor"]]
total_cup_points flavor 0 90.58 8.83 1 89.92 8.67 2 89.75 8.50 3 89.00 8.58 4 88.83 8.50 ... ... ... 1333 78.75 7.58 1334 78.08 7.67 1335 77.17 7.33 1336 75.08 6.83 1337 73.75 6.67 [1338 linhas x 2 colunas]
pts_vs_flavor_samp = pts_vs_flavor_pop.sample(n=10)
total_cup_points flavor 1088 80.33 7.17 1157 79.67 7.42 1267 76.17 7.33 506 83.00 7.67 659 82.50 7.42 817 81.92 7.50 1050 80.67 7.42 685 82.42 7.50 1027 80.92 7.25 62 85.58 8.17 [10 linhas x 2 colunas]
.sample()
pandas
cup_points_samp = coffee_ratings['total_cup_points'].sample(n=10)
1088 80.33 1157 79.67 1267 76.17 ... ... 685 82.42 1027 80.92 62 85.58 Name: total_cup_points, dtype: float64
Um parâmetro populacional é um cálculo feito no conjunto da população
import numpy as np np.mean(pts_vs_flavor_pop['total_cup_points'])
82.15120328849028
Uma estimativa pontual, ou estatística da amostra, é um cálculo feito na amostra
np.mean(cup_points_samp)
81.31800000000001
pts_vs_flavor_pop['flavor'].mean()
7.526046337817639
pts_vs_flavor_samp['flavor'].mean()
7.485000000000001