Introdução ao bootstrapping
Amostragem em Python

James Chapman
Curriculum Manager, DataCamp
Com ou sem
Amostragem sem reposição:

Amostragem com reposição ("reamostragem"):

Amostragem aleatória simples sem reposição
População:

Amostra:

Amostragem aleatória simples com reposição
População:
Reamostra:

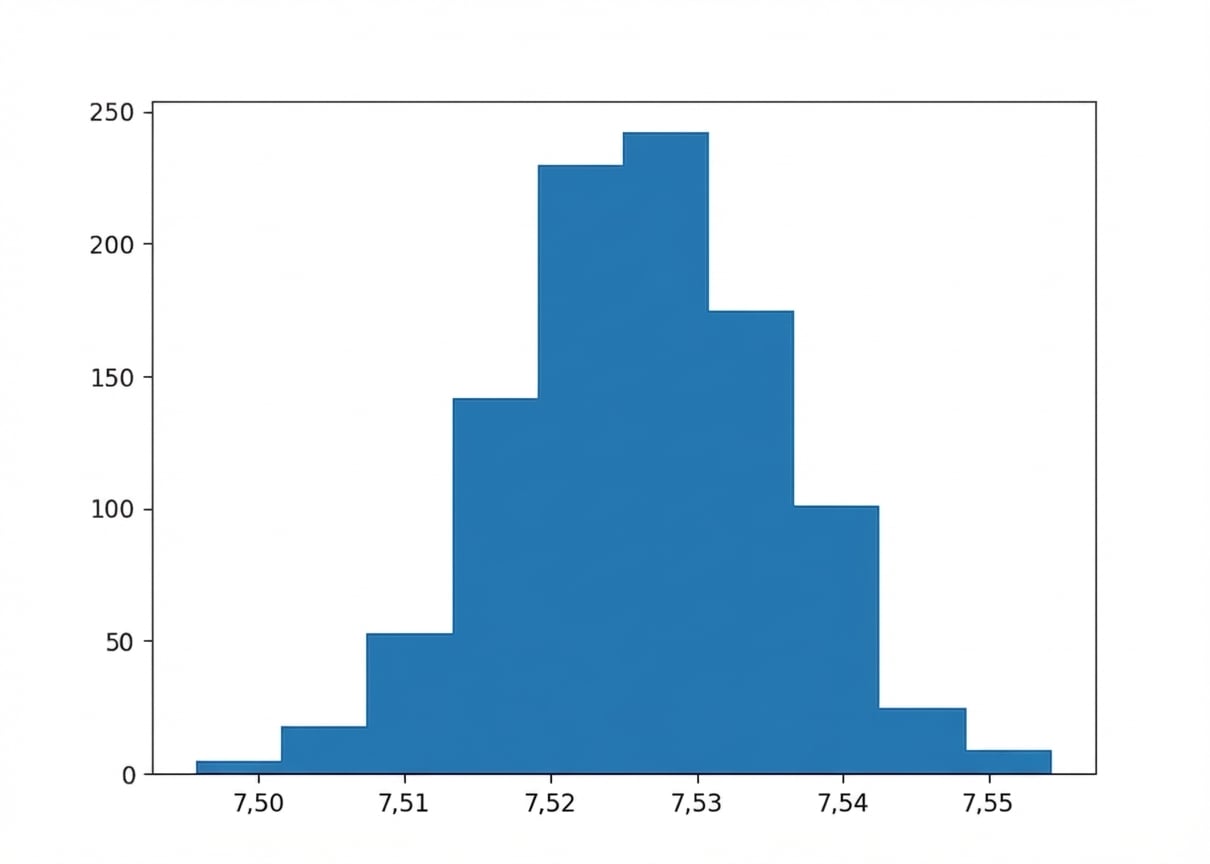
Bootstrapping

Histograma da distribuição bootstrap