Carregamento
Introdução à Engenharia de Dados

Vincent Vankrunkelsven
Data Engineer @ DataCamp
Bancos para analytics ou aplicações
Analytics

- Consultas agregadas
- Processamento analítico online (OLAP)
Aplicações

- Muitas transações
- Processamento de transações online (OLTP)
Orientação a colunas vs. linhas
Analytics
- Orientado a colunas

- Consultas em subconjunto de colunas
- Paralelização
Aplicações
- Orientado a linhas
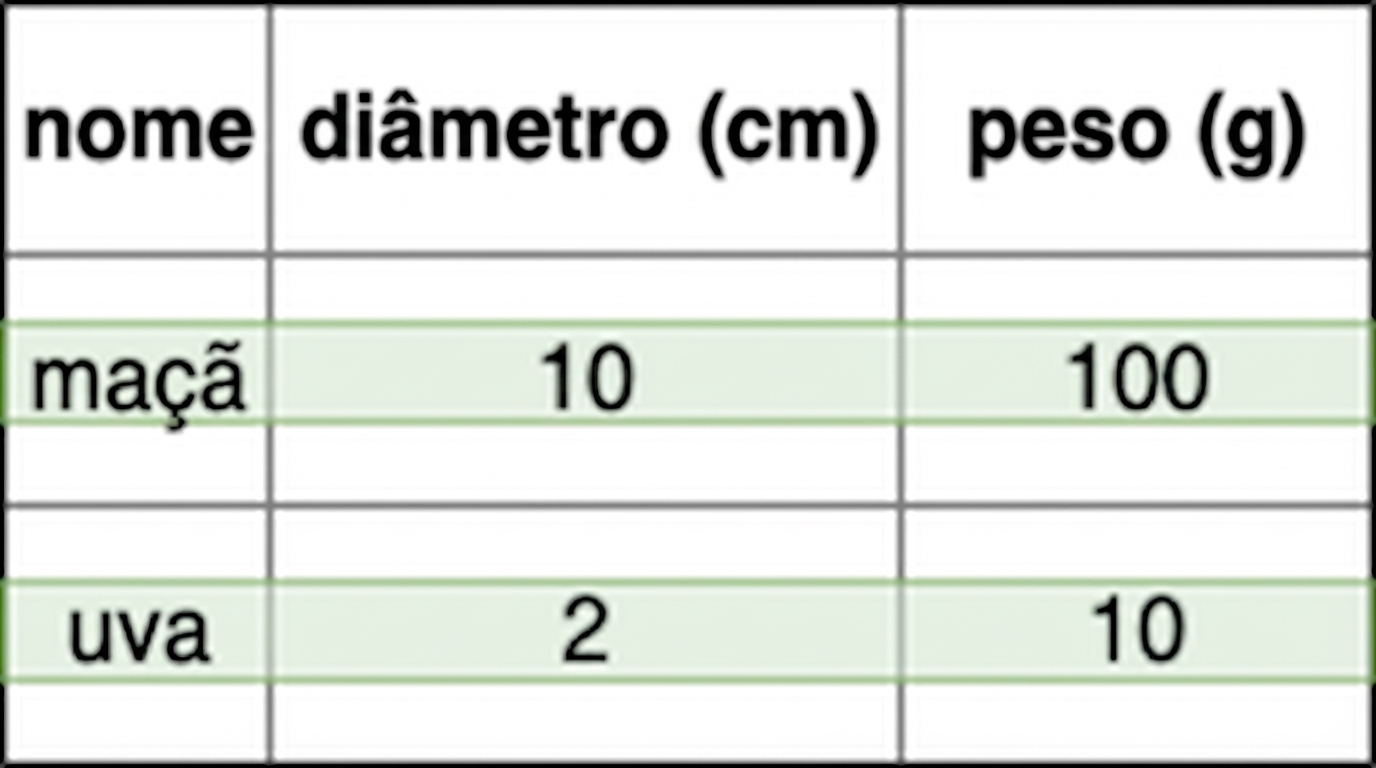
- Armazenado por registro
- Inserido por transação
- Ex.: adicionar cliente é rápido
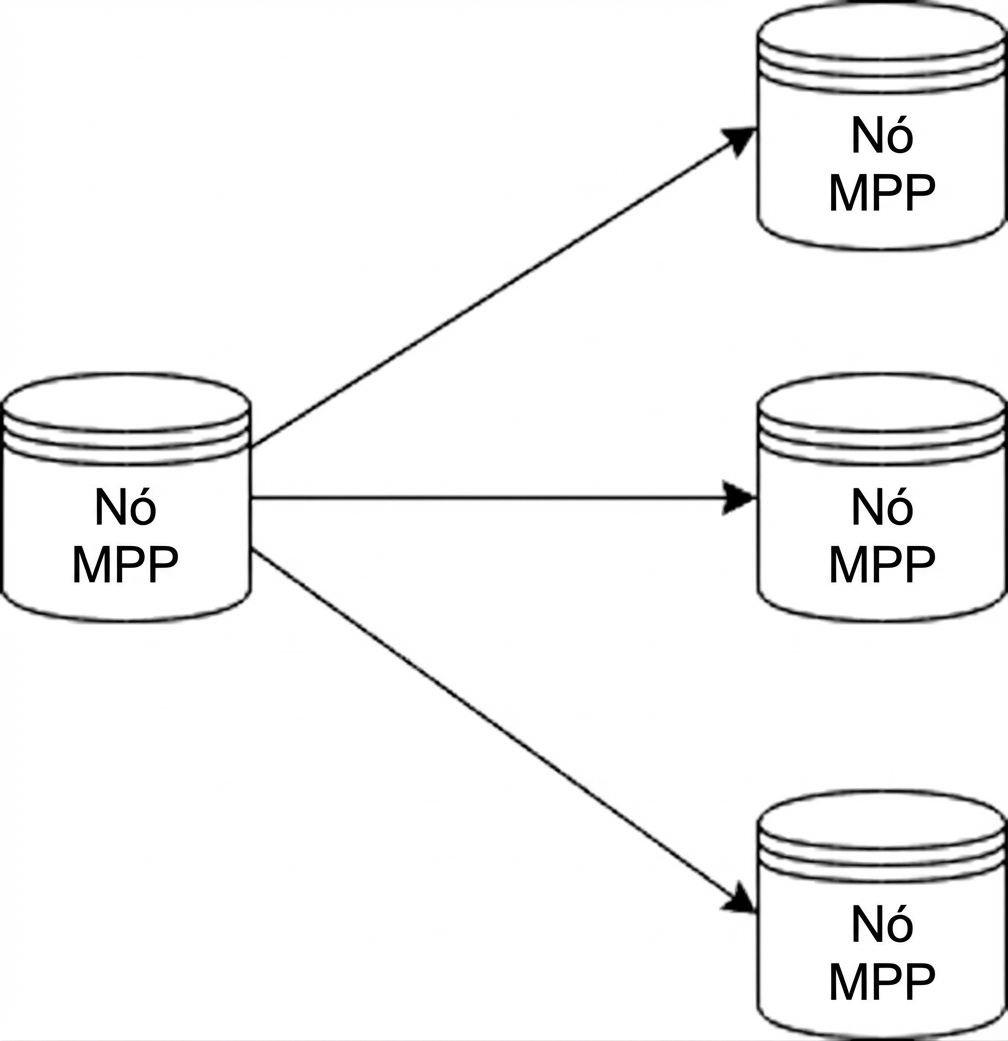
Bancos MPP
Bancos MPP (Processamento Massivo Paralelo)