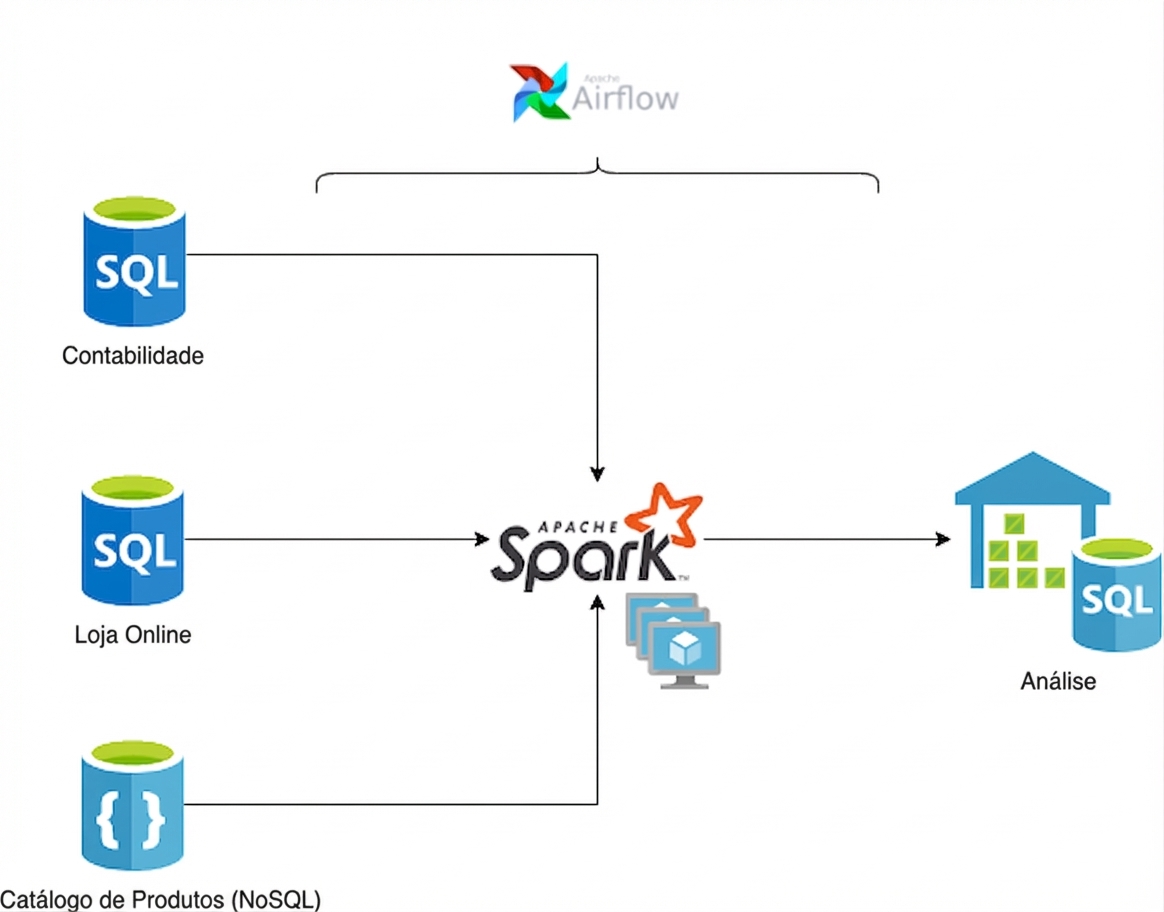
Ferramentas do engenheiro de dados
Introdução à Engenharia de Dados

Vincent Vankrunkelsven
Data Engineer @ DataCamp
Bancos de dados


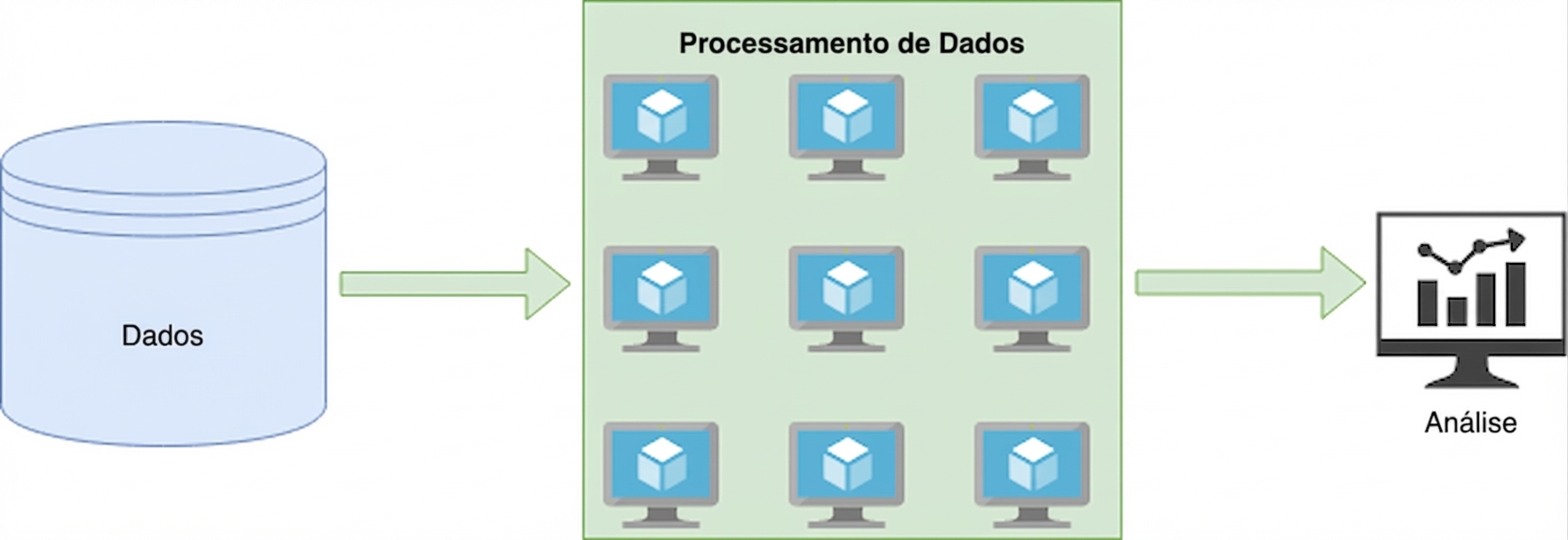
Processamento
Orquestração
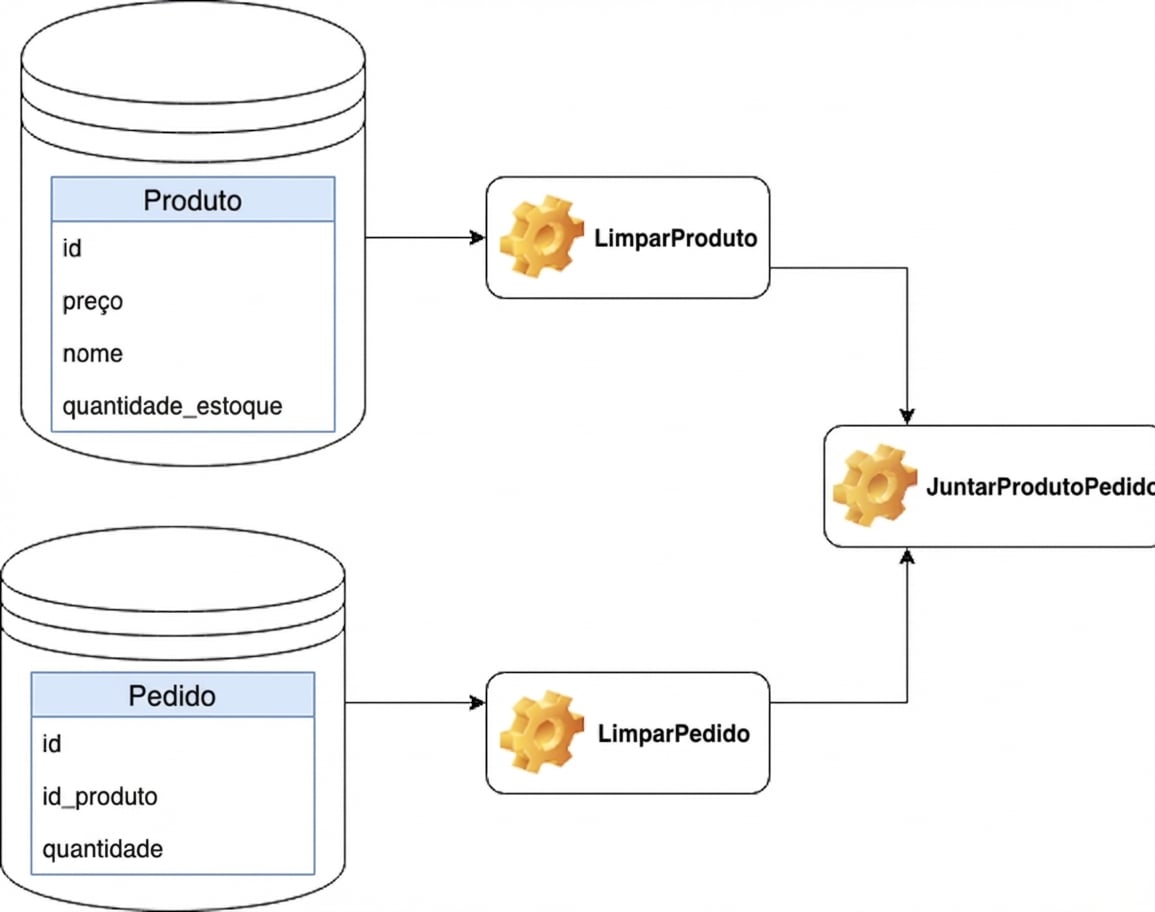
JoinProductOrder precisa rodar depois de CleanProduct e CleanOrder
Ferramentas existentes
Bancos de dados


Processamento
![]()
![]()
Orquestração
![]()
![]()

Um pipeline de dados