Frameworks de computação paralela
Introdução à Engenharia de Dados

Vincent Vankrunkelsven
Data Engineer @ DataCamp
![]()
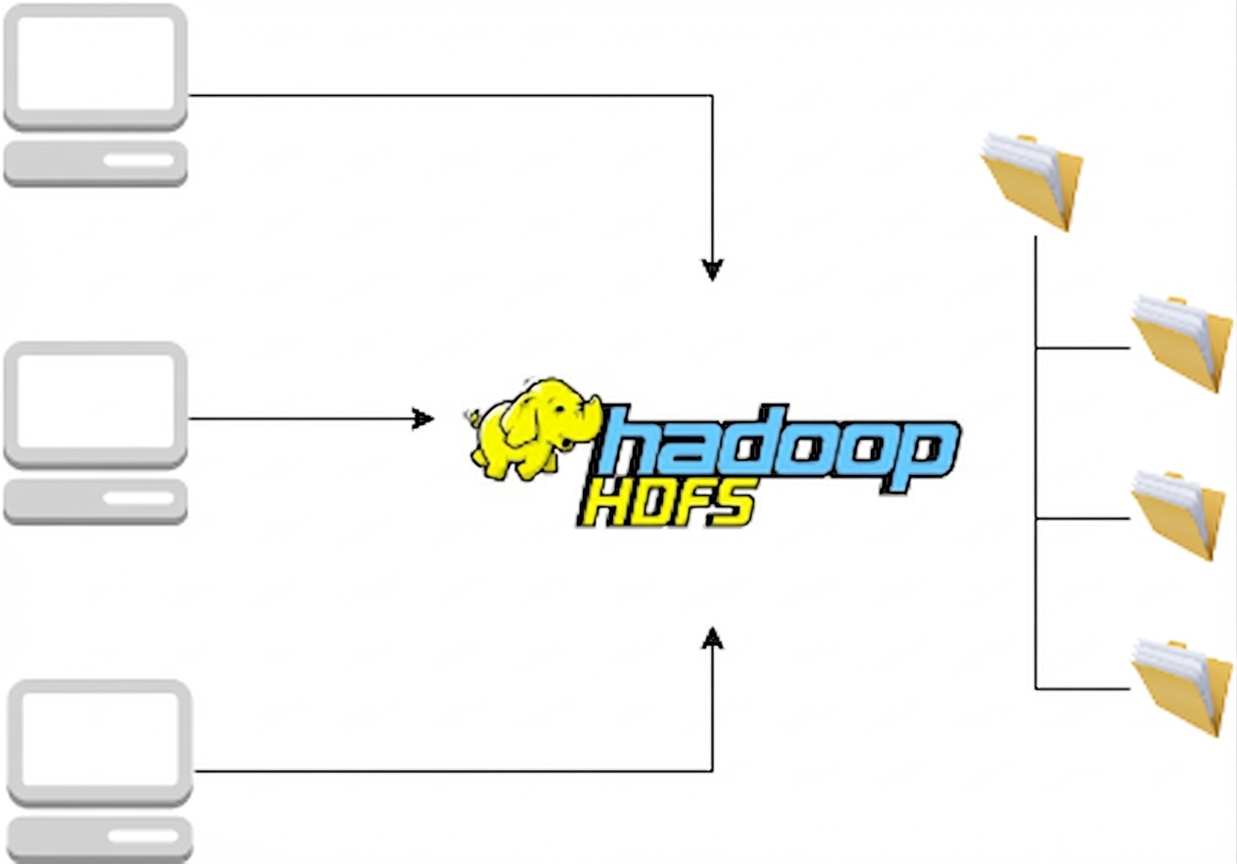
HDFS
MapReduce
![]()

Hive
- Roda no Hadoop
- Linguagem de consulta estruturada: Hive SQL
- Antes usava MapReduce; hoje, outras ferramentas
![]()
Hive: um exemplo

![]()
- Evita gravações em disco
- Mantido pela Apache Software Foundation

