O que é computação paralela
Introdução à Engenharia de Dados

Vincent Vankrunkelsven
Data Engineer @ DataCamp
Ideia por trás da computação paralela
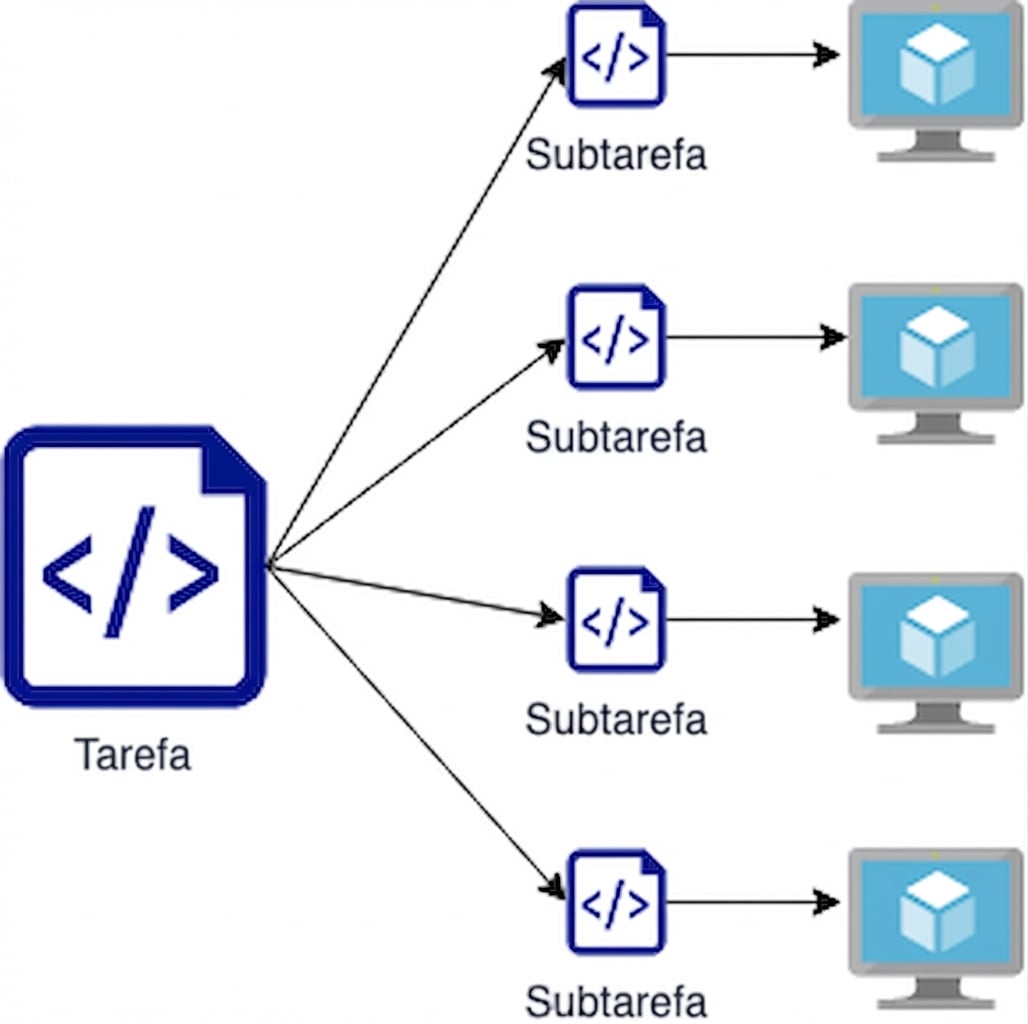
A alfaiataria
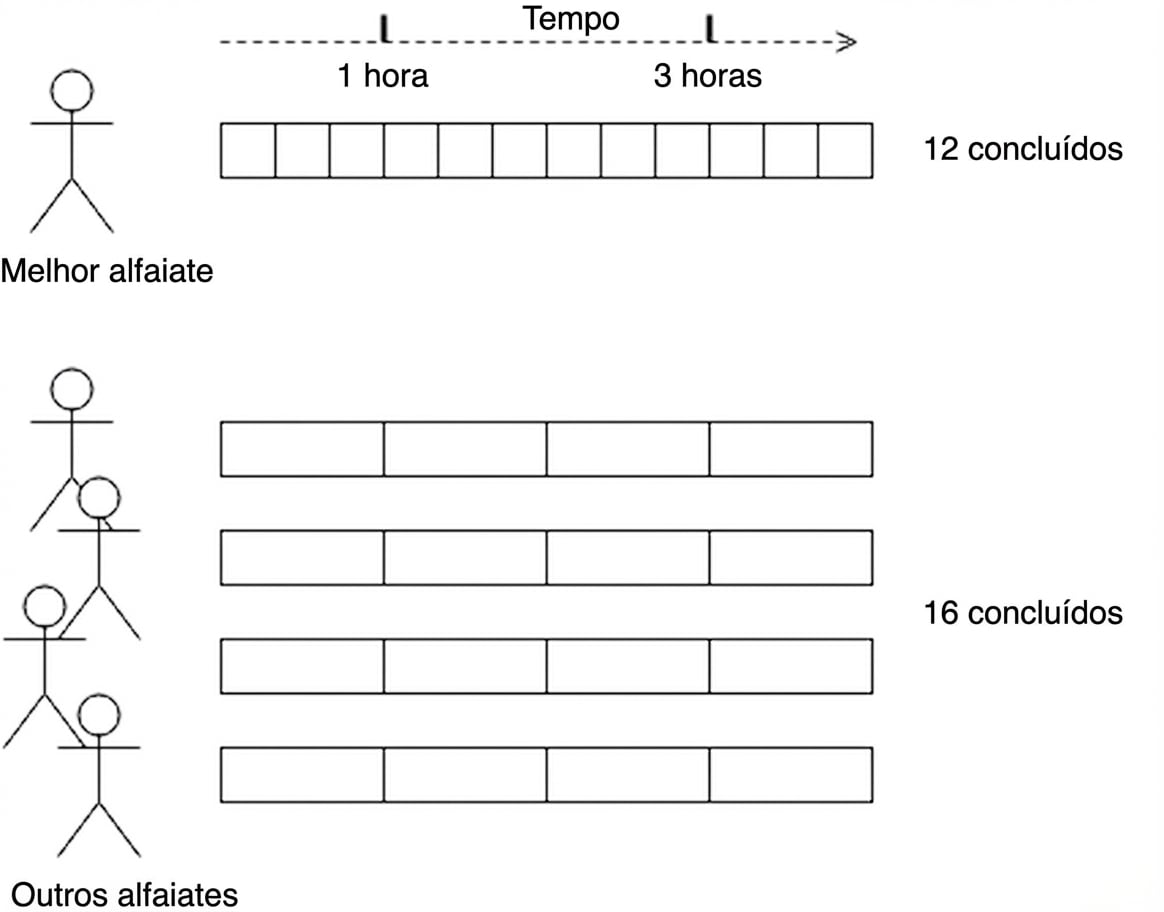
Benefícios da computação paralela
Módulo de memória RAM:

Riscos da computação paralela
Lentidão paralela:
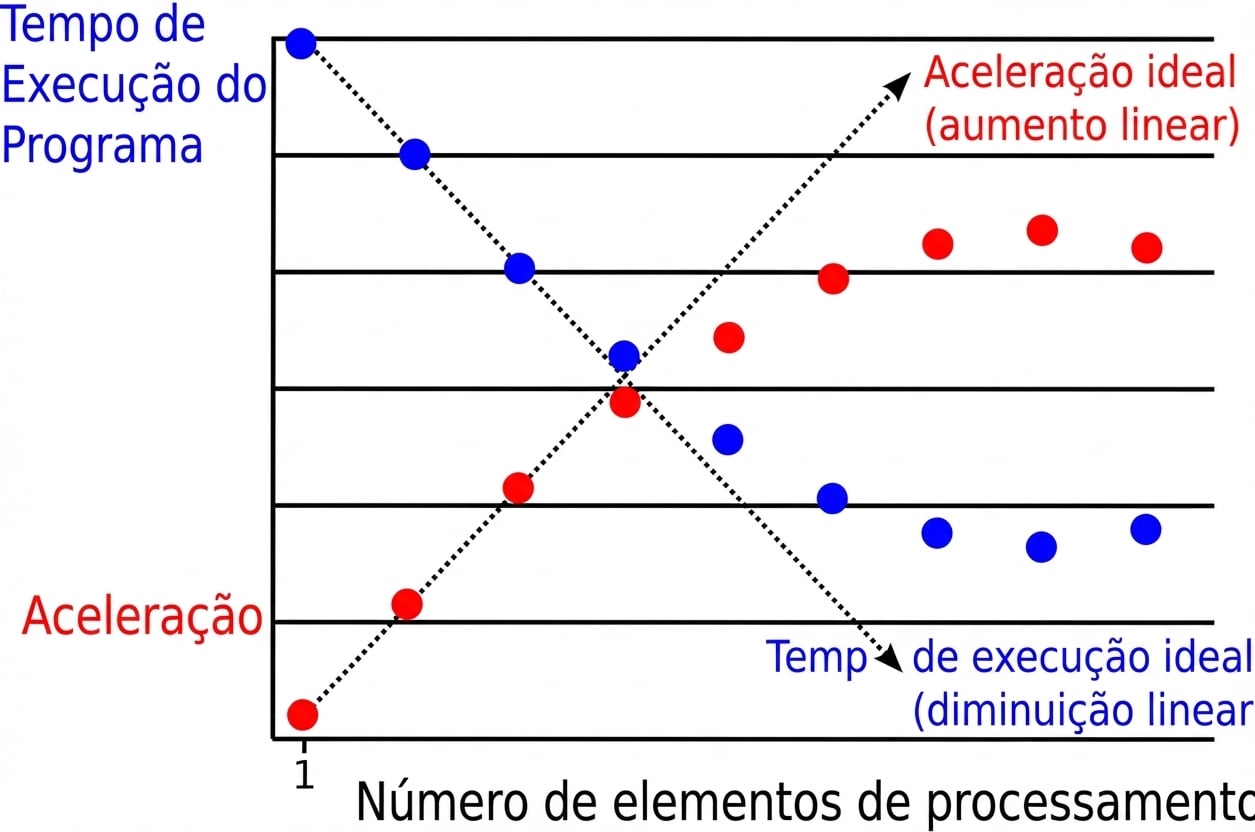
Um exemplo


