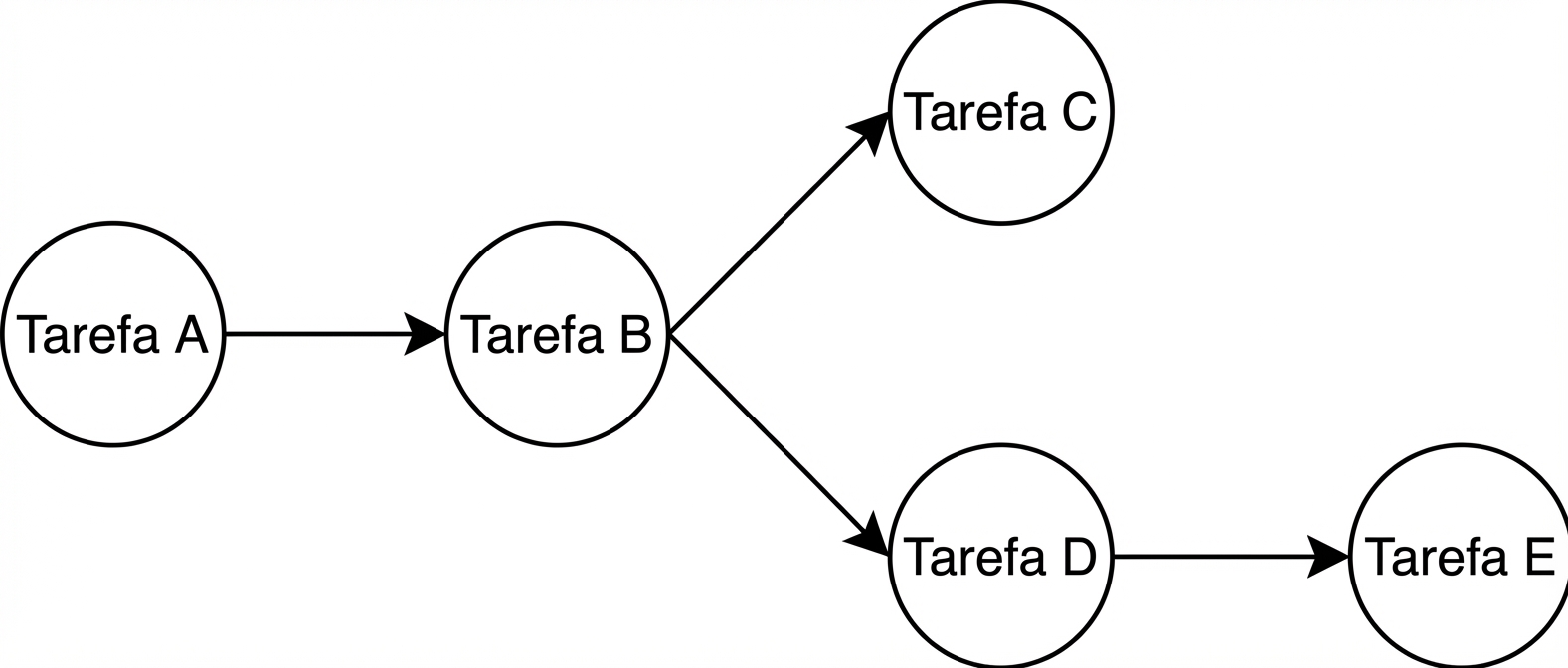
A função ETL
def extract_table_to_df(tablename, db_engine):
return pd.read_sql("SELECT * FROM {}".format(tablename), db_engine)
def split_columns_transform(df, column, pat, suffixes):
# Converts column into str and splits it on pat...
def load_df_into_dwh(film_df, tablename, schema, db_engine):
return pd.to_sql(tablename, db_engine, schema=schema, if_exists="replace")
db_engines = { ... } # Needs to be configured
def etl():
# Extract
film_df = extract_table_to_df("film", db_engines["store"])
# Transform
film_df = split_columns_transform(film_df, "rental_rate", ".", ["_dollar", "_cents"])
# Load
load_df_into_dwh(film_df, "film", "store", db_engines["dwh"])