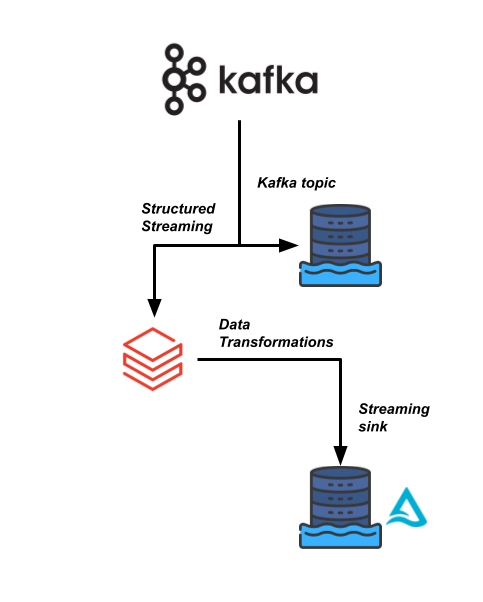
Data transformations in Databricks
Databricks Concepts

Kevin Barlow
Data Practitioner
Auto Loader
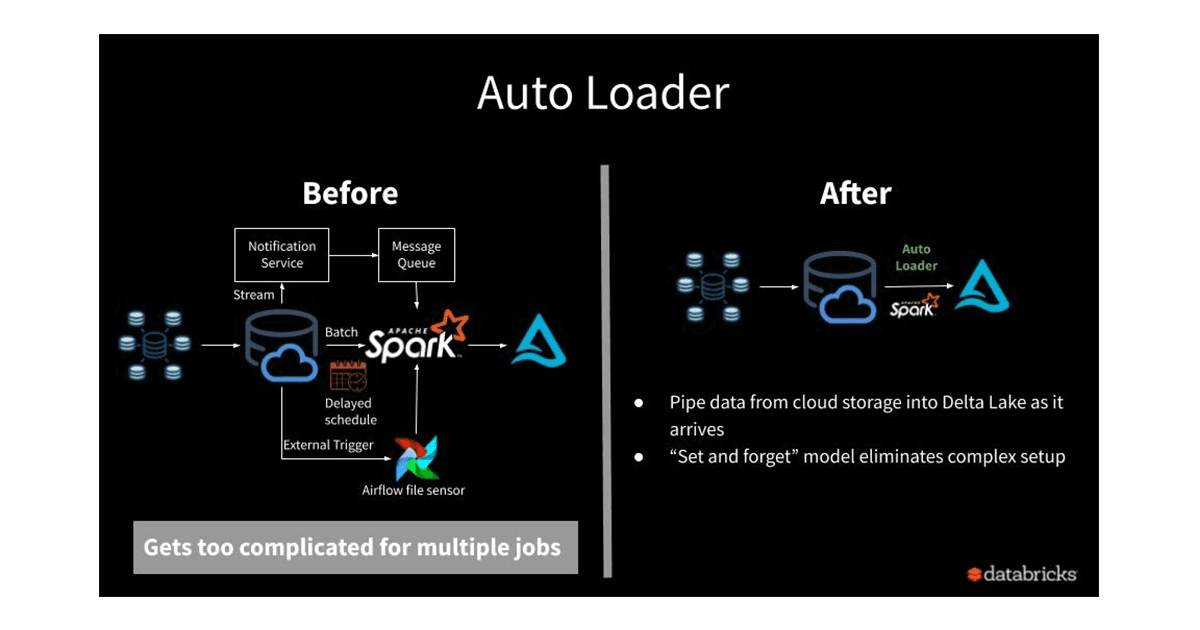
1 https://www.databricks.com/blog/2020/02/24/introducing-databricks-ingest-easy-data-ingestion-into-delta-lake.html
Structured Streaming