Vergleich von Stichprobe und Bootstrap-Verteilung
Stichprobenziehung in Python

James Chapman
Curriculum Manager, DataCamp
Kaffee-Fokus-Subset
coffee_sample = coffee_ratings[["variety", "country_of_origin", "flavor"]]\
.reset_index().sample(n=500)
index variety country_of_origin flavor
132 132 Other Costa Rica 7.58
51 51 None United States (Hawaii) 8.17
42 42 Yellow Bourbon Brazil 7.92
569 569 Bourbon Guatemala 7.67
.. ... ... ... ...
643 643 Catuai Costa Rica 7.42
356 356 Caturra Colombia 7.58
494 494 None Indonesia 7.58
169 169 None Brazil 7.81
[500 rows x 4 columns]
Bootstrap der mittleren Kaffeearomen
import numpy as np
mean_flavors_5000 = []
for i in range(5000):
mean_flavors_5000.append(
np.mean(coffee_sample.sample(frac=1, replace=True)['flavor'])
)
bootstrap_distn = mean_flavors_5000
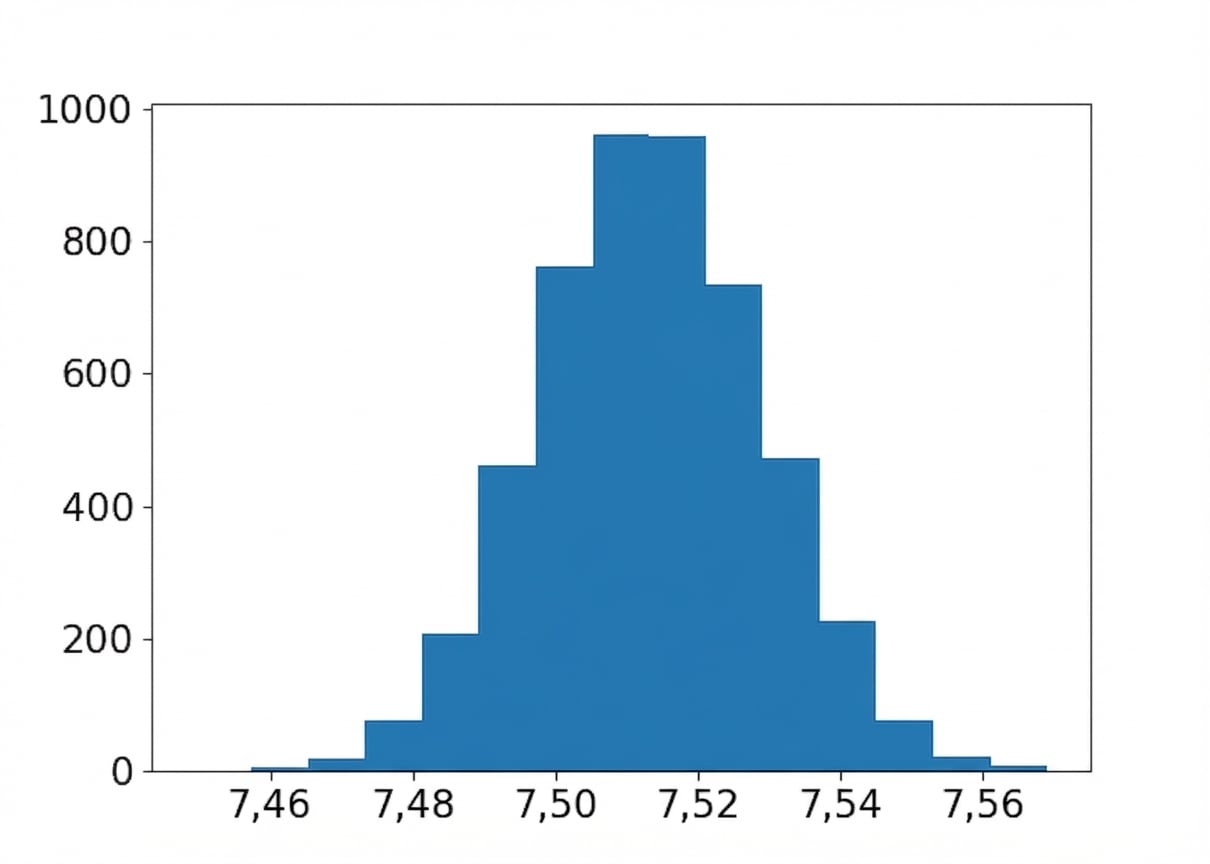
Mittelwert: Bootstrap-Verteilung der Aromen
import matplotlib.pyplot as plt
plt.hist(bootstrap_distn, bins=15)
plt.show()
Mittelwerte: Stichprobe, Bootstrap-Verteilung, Population
Stichprobenmittel:
coffee_sample['flavor'].mean()
7.5132200000000005
Geschätzter Populationsmittelwert:
np.mean(bootstrap_distn)
7.513357731999999
Wahrer Populationsmittelwert:
coffee_ratings['flavor'].mean()
7.526046337817639
Mittelwerte interpretieren
Mittelwert der Bootstrap-Verteilung:
- Meist nah am Stichprobenmittel
- Schätzt den Populationsmittelwert evtl. schlecht
Bootstrapping korrigiert keine Stichprobenverzerrungen
Stichproben-SD vs. Bootstrap-Verteilungs-SD
Stichproben-Standardabweichung:
coffee_sample['flavor'].std()
0.3540883911928703
Geschätzte Populations-Standardabweichung?
np.std(bootstrap_distn, ddof=1)
0.015768474367958217
SD: Stichprobe, Bootstrap-Verteilung, Population
Stichproben-Standardabweichung:
coffee_sample['flavor'].std()
0.3540883911928703
Geschätzte Populations-Standardabweichung:
standard_error = np.std(bootstrap_distn, ddof=1)
Standardfehler ist die Standardabweichung der interessierenden Statistik
Wahre Standardabweichung:
coffee_ratings['flavor'].std(ddof=0)
0.34125481224622645
standard_error * np.sqrt(500)
0.3525938058821761
Standardfehler mal Wurzel der Stichprobengröße ≈ Populations-Standardabweichung
Standardfehler interpretieren
- Geschätzter Standardfehler → Standardabweichung der Bootstrap-Verteilung einer Stichprobenstatistik
- $\text{Pop.-Stdabw} \approx \text{Std. Fehler} \times \sqrt{\text{Stichprobengröße}}$
Lass uns üben!
Stichprobenziehung in Python

