Erstellen einer Stichprobenverteilung
Stichprobenziehung in Python

James Chapman
Curriculum Manager, DataCamp
Verteilung der Stichprobenmittelwerte (n = 30)
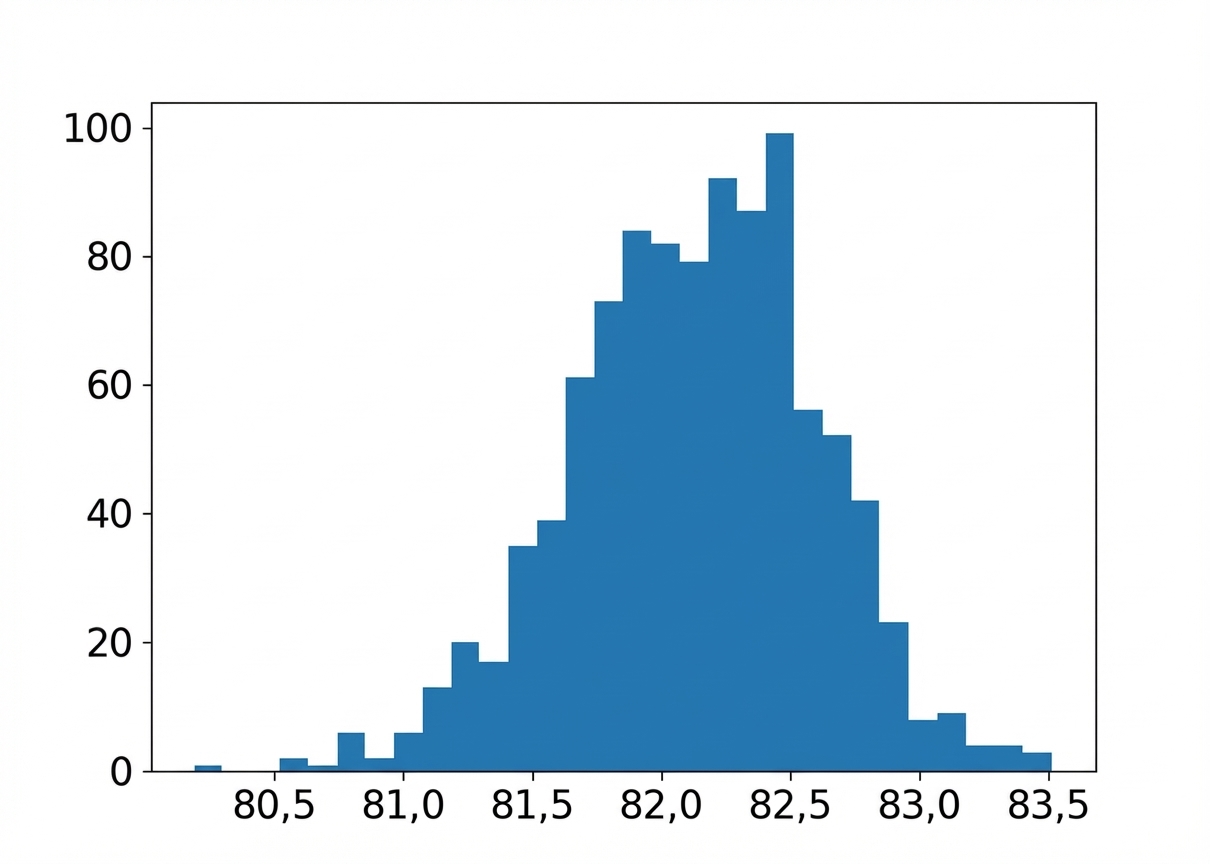
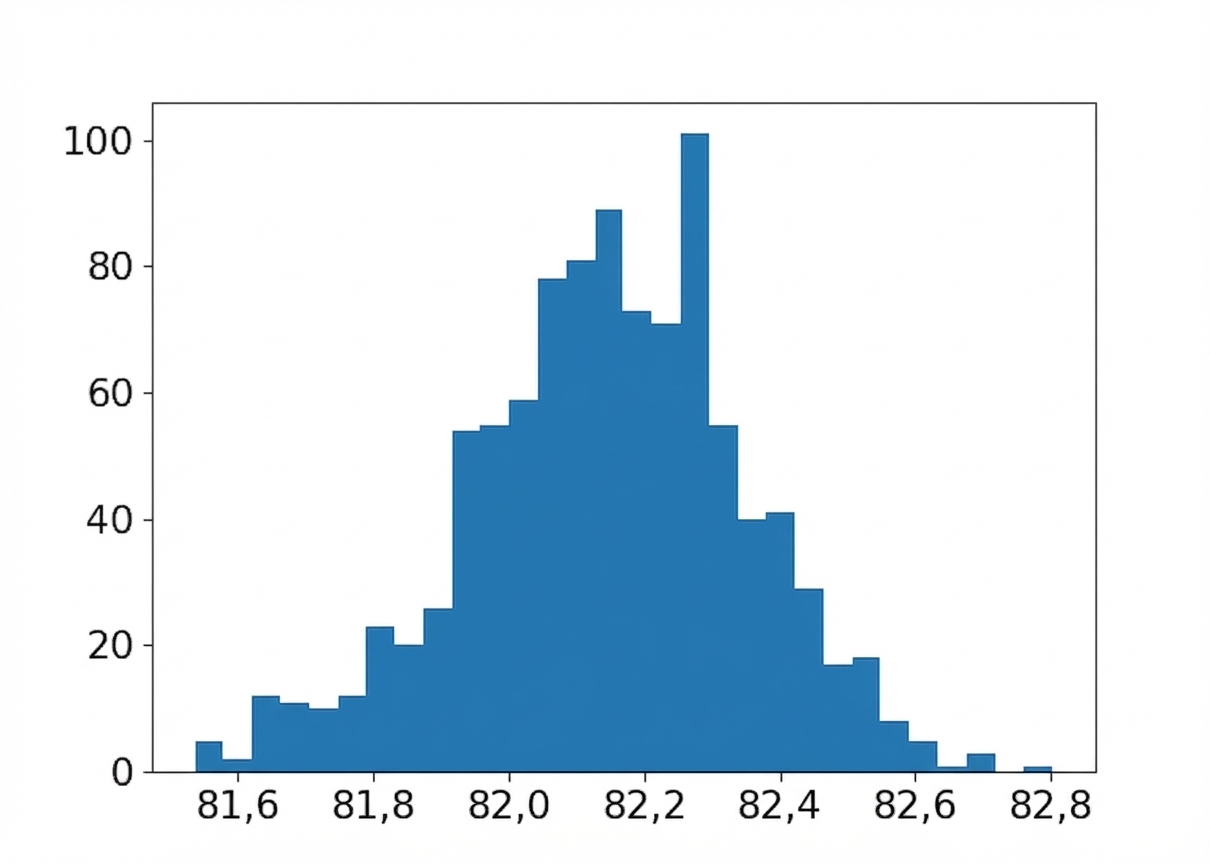
Unterschiedliche Stichprobengrößen
Stichprobengröße: 6
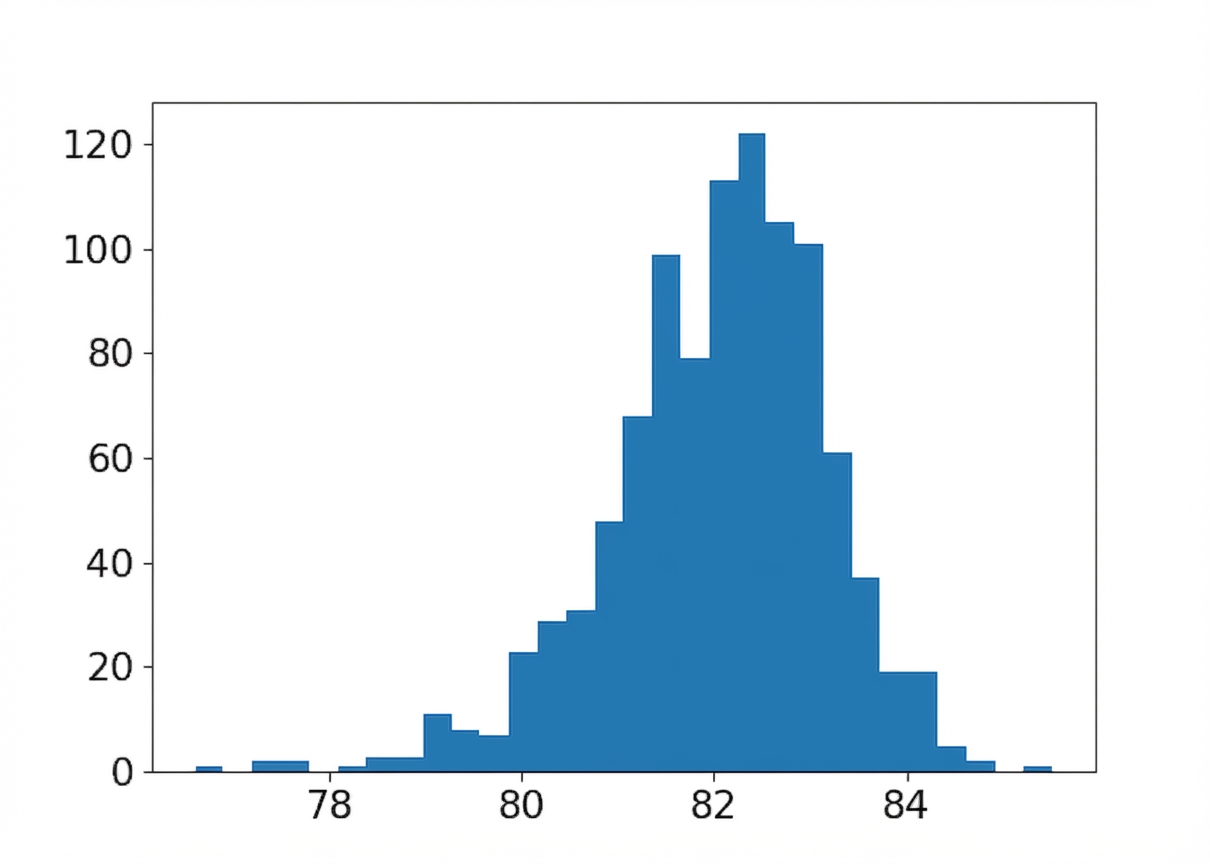
Stichprobengröße: 150
Stichprobenziehung in Python
James Chapman
Curriculum Manager, DataCamp
Stichprobengröße: 6
Stichprobengröße: 150

