Métricas para tareas de lenguaje: ROUGE, METEOR, EM
Introducción a los LLMs en Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Tareas y métricas de LLM
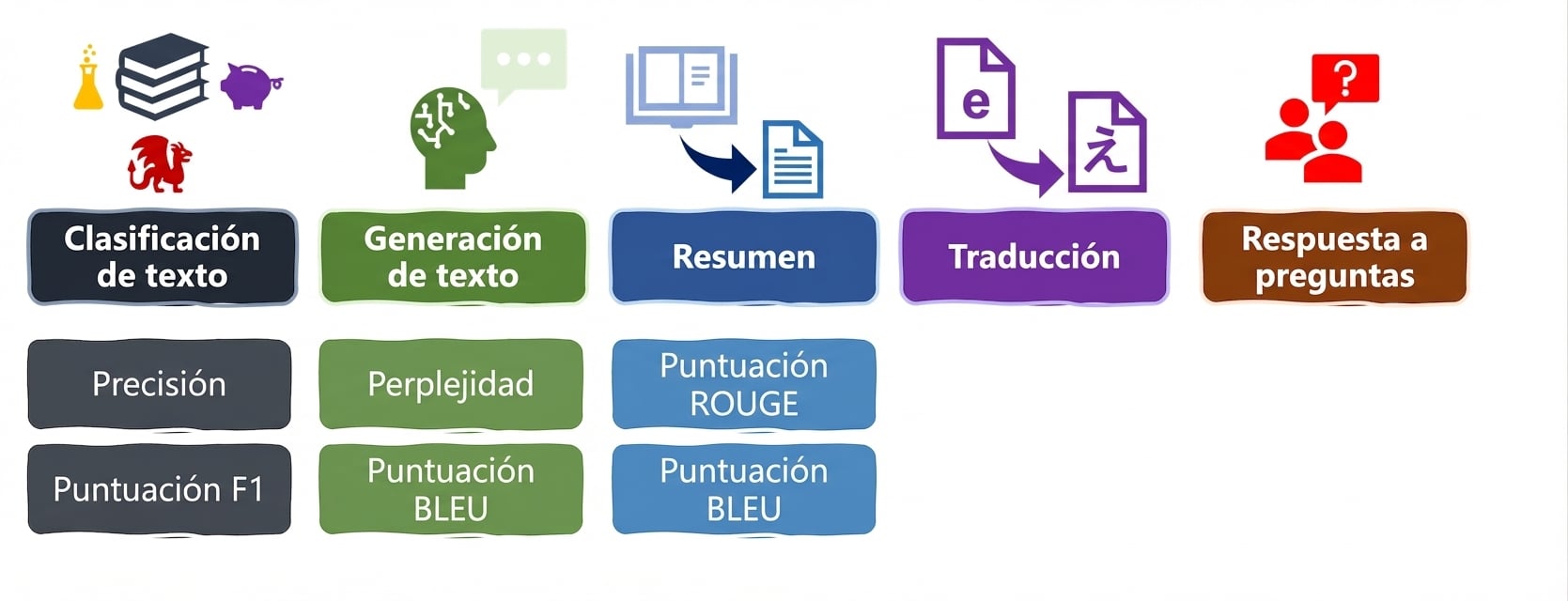
Tareas y métricas de LLM
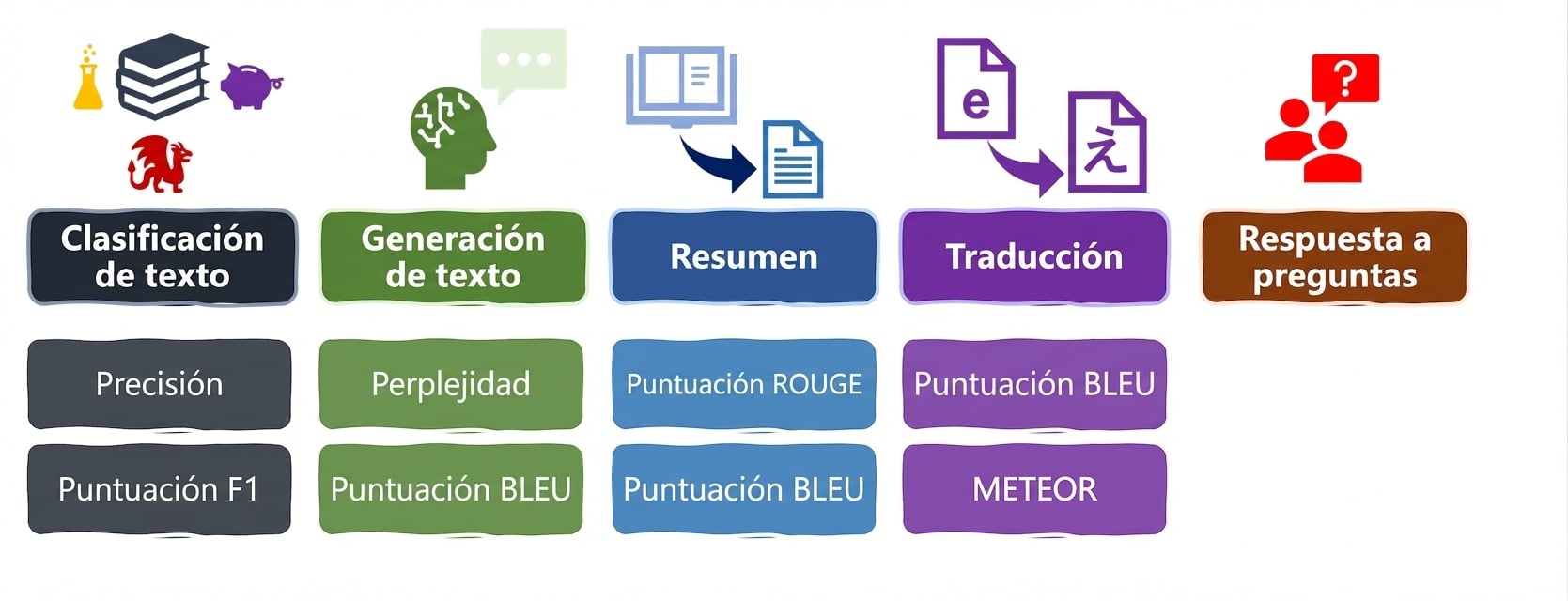
Tareas y métricas de LLM
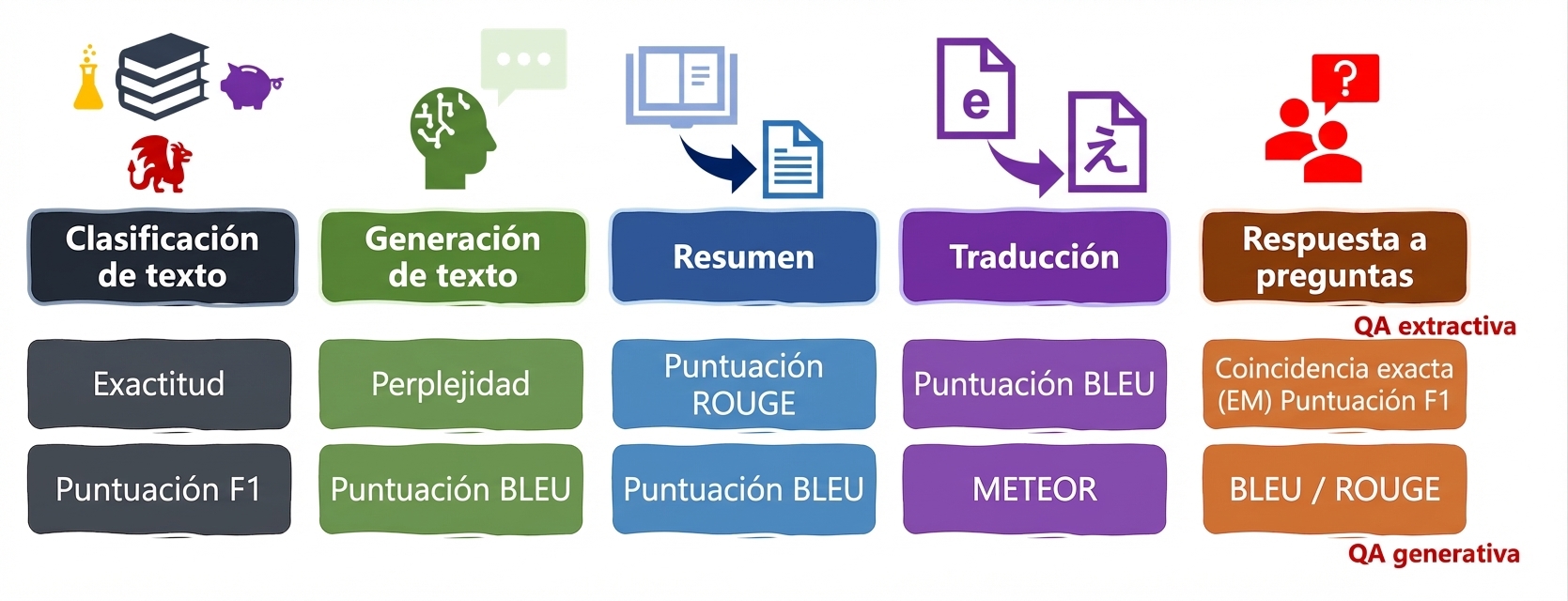
ROUGE
- ROUGE: similitud entre un resumen generado y resúmenes de referencia
- Mira n-gramas y solapamientos
predictions:salidas del LLMreferences: resúmenes humanos

Preguntas y respuestas

