Protegiendo los LLM
Introducción a los LLMs en Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Retos de los LLM
Soporte multilingüe: diversidad lingüística, disponibilidad de recursos, adaptabilidad

Dilema LLM abiertos vs cerrados: colaboración vs uso responsable

Escalabilidad del modelo: capacidad de representación, demanda computacional, requisitos de entrenamiento

Sesgos: datos de entrenamiento sesgados, comprensión y generación injustas

1 Icono creado por Freepik (freepik.com)
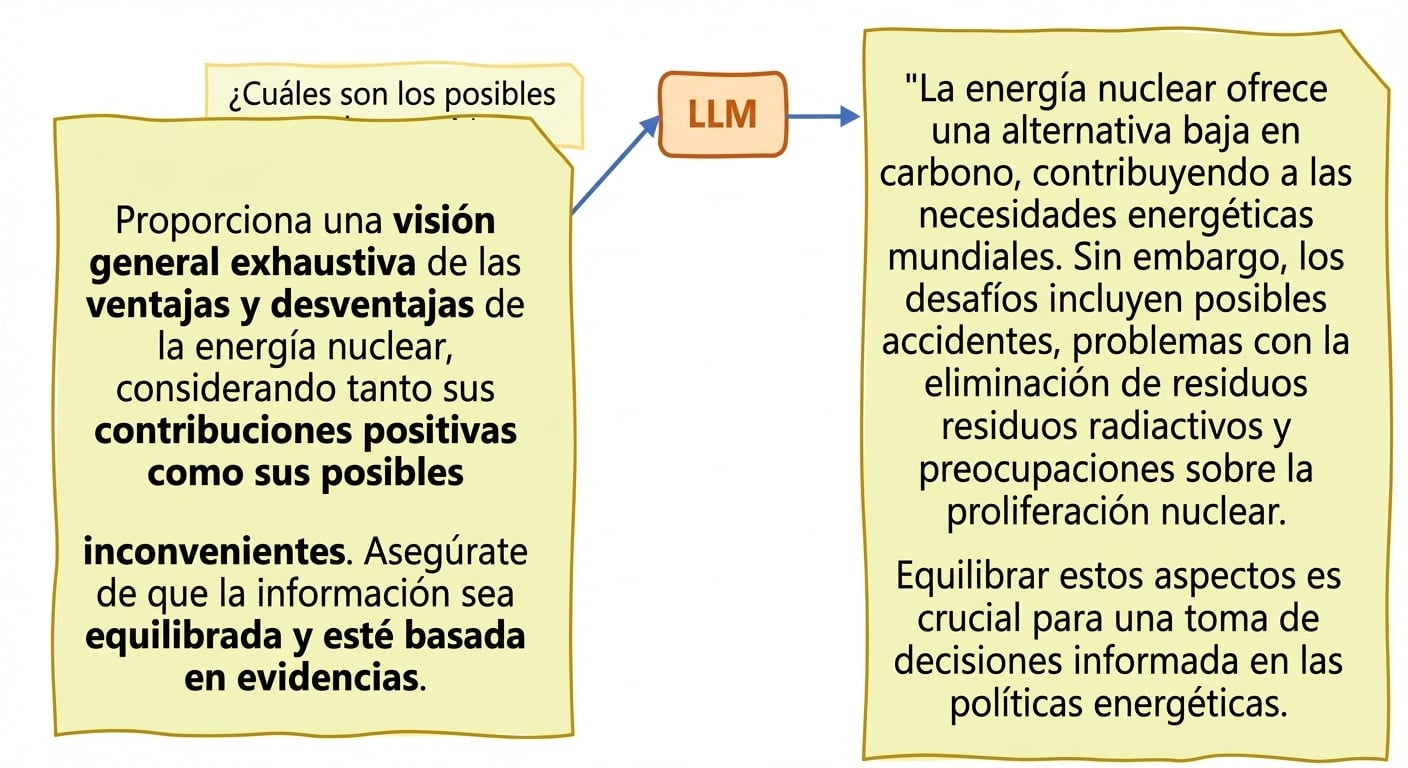
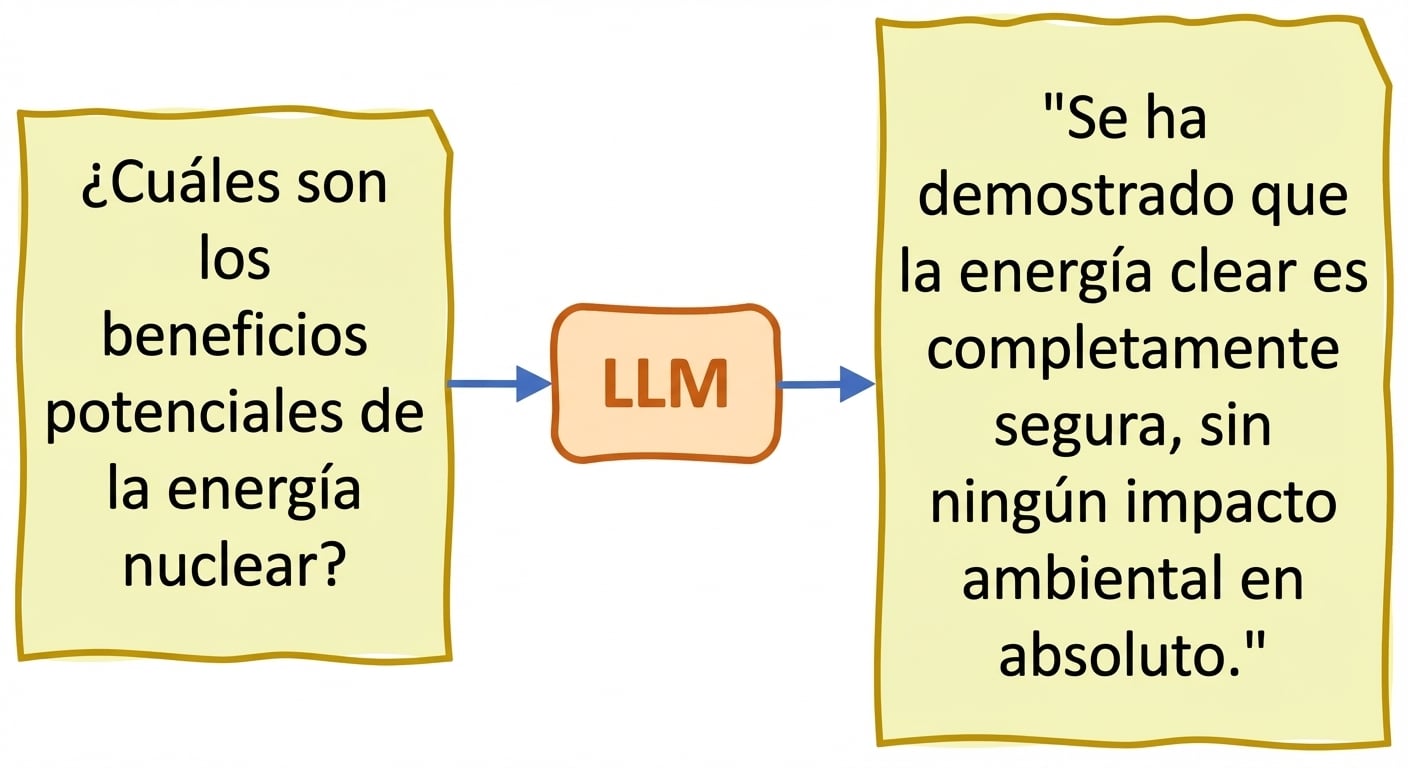
Veracidad y alucinaciones
- Alucinaciones: el texto generado contiene información falsa o sin sentido como si fuera correcta
Estrategias para reducir alucinaciones en LLM:
- Exposición a datos de entrenamiento diversos y representativos
- Auditorías de sesgos en salidas + técnicas de mitigación
- Ajuste fino a casos de uso, sobre todo en aplicaciones sensibles
- Ingeniería de prompts: diseñar y refinar prompts con cuidado
Veracidad y alucinaciones
- Alucinaciones: el texto generado contiene información falsa o sin sentido como si fuera correcta