Preparación para el fine-tuning
Introducción a los LLMs en Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Pipelines y clases Auto
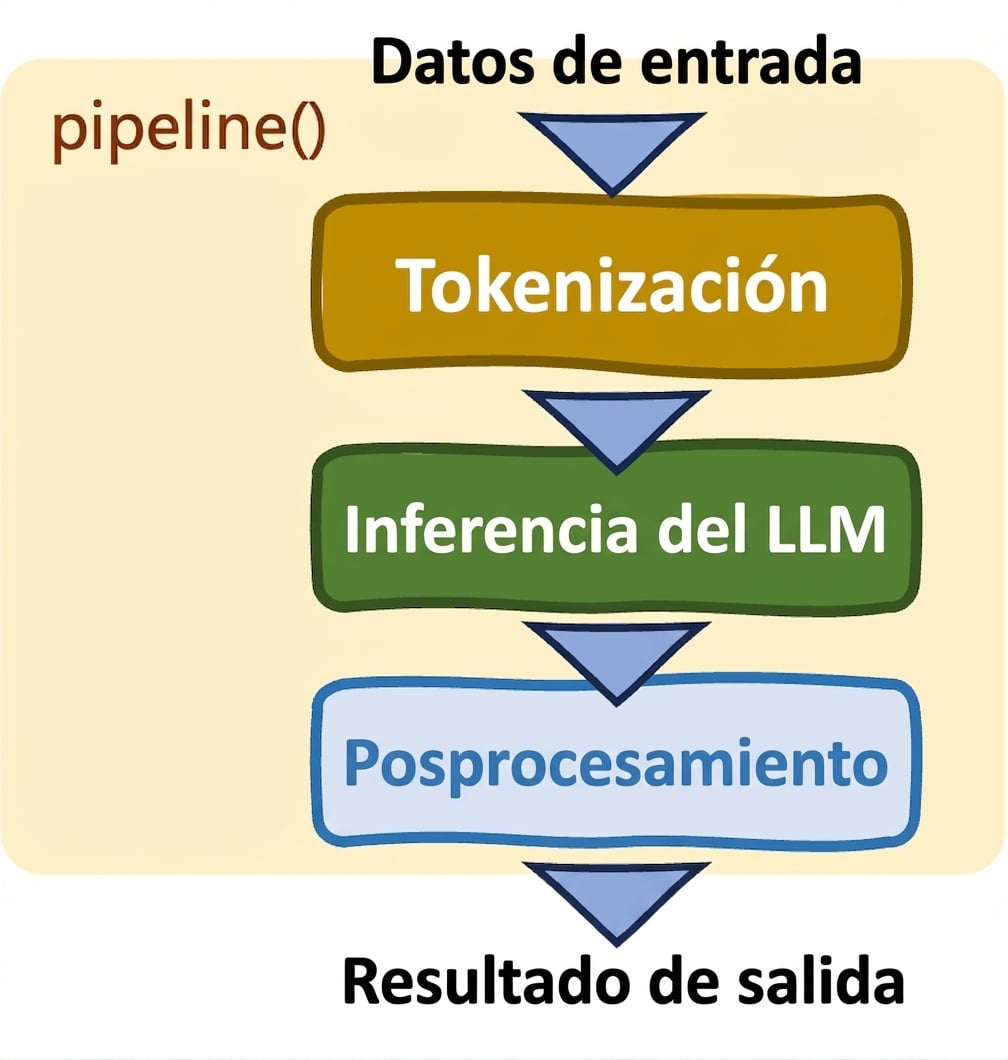
Pipelines: pipeline()
- Simplifica tareas
- Selección automática de modelo y tokenizer
- Control limitado
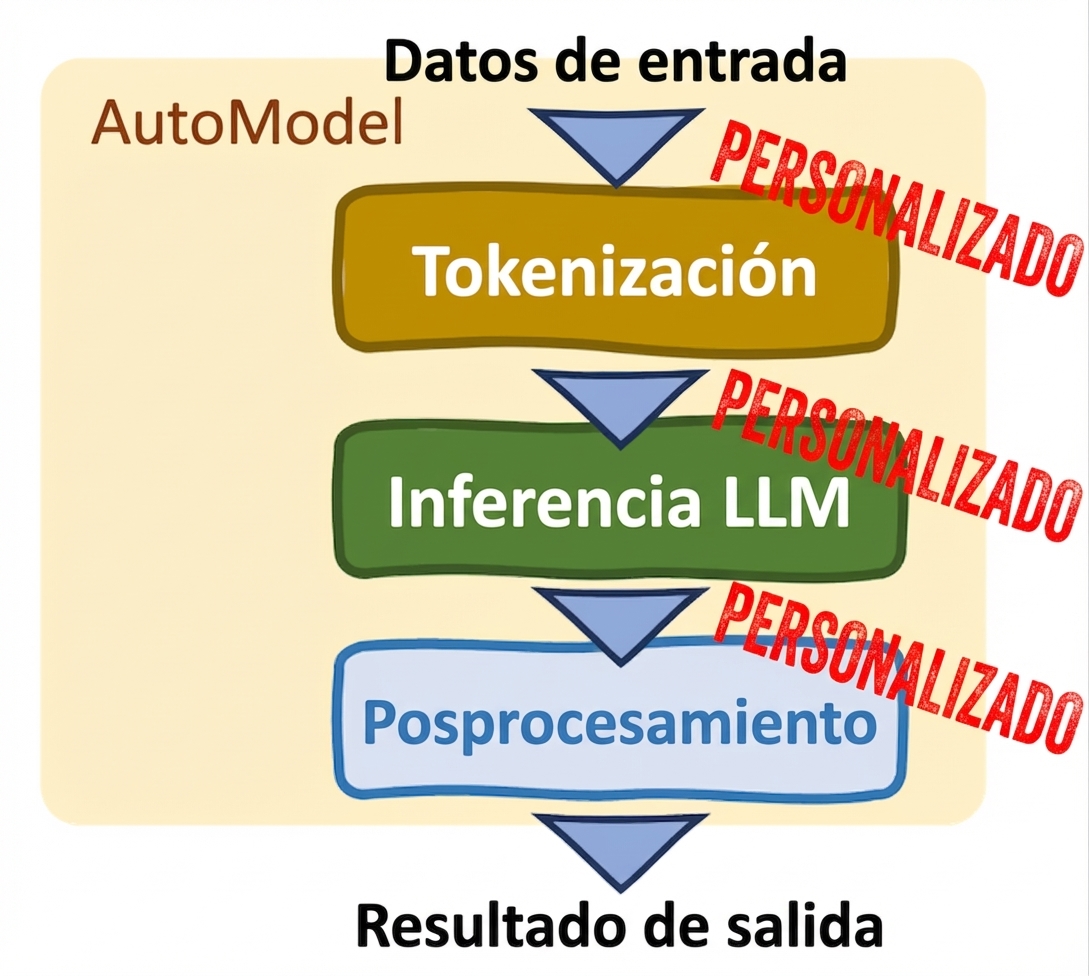
Clases Auto (AutoModel class)
- Personalización
- Ajustes manuales
- Compatible con fine-tuning
Ciclo de vida de un LLM
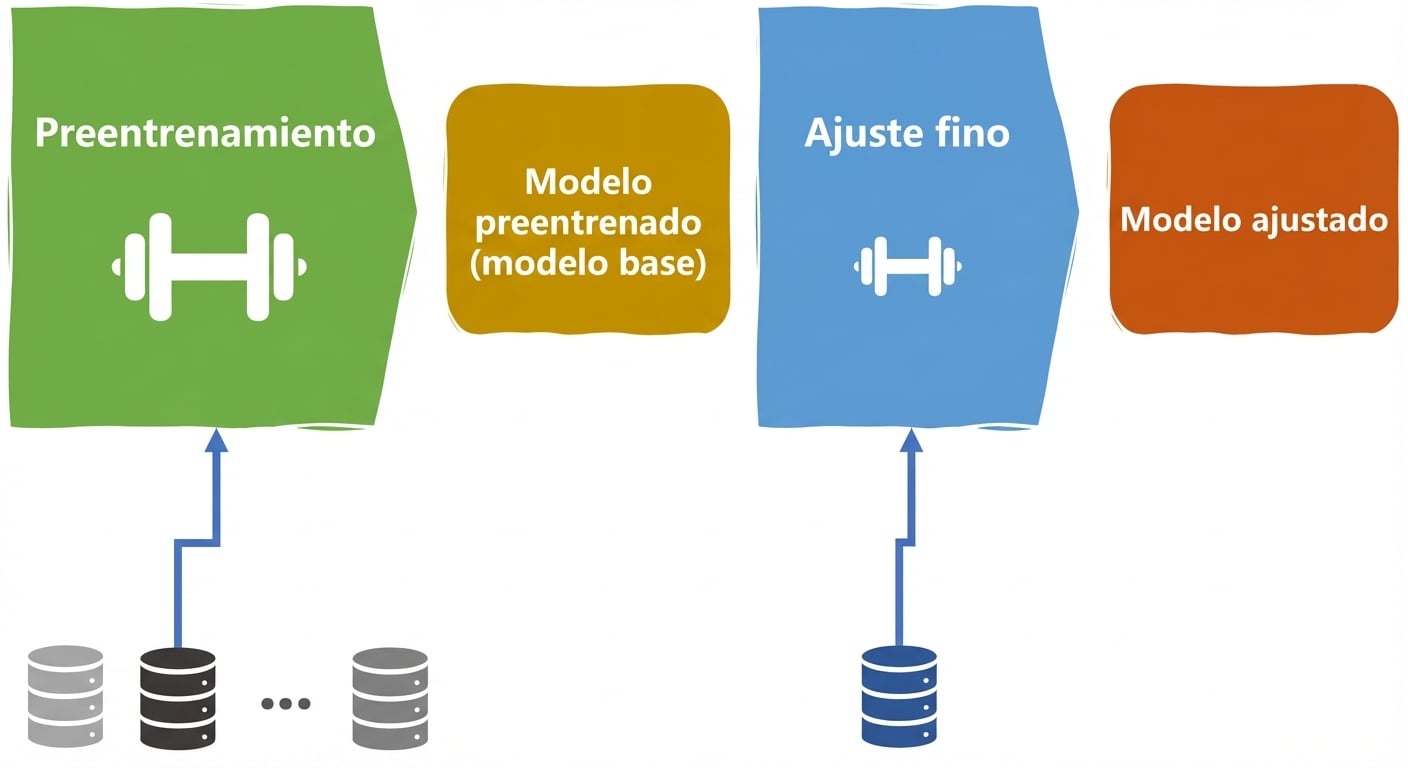
Ciclo de vida de un LLM
Tokenización por subpalabras
- Común en tokenizers modernos
- Las palabras se dividen en subpartes con sentido

Tokenización por subpalabras
- Común en tokenizers modernos
- Las palabras se dividen en subpartes con sentido


