Advanced splitting methods
Retrieval Augmented Generation (RAG) with LangChain

Meri Nova
Machine Learning Engineer
Splitting on tokens
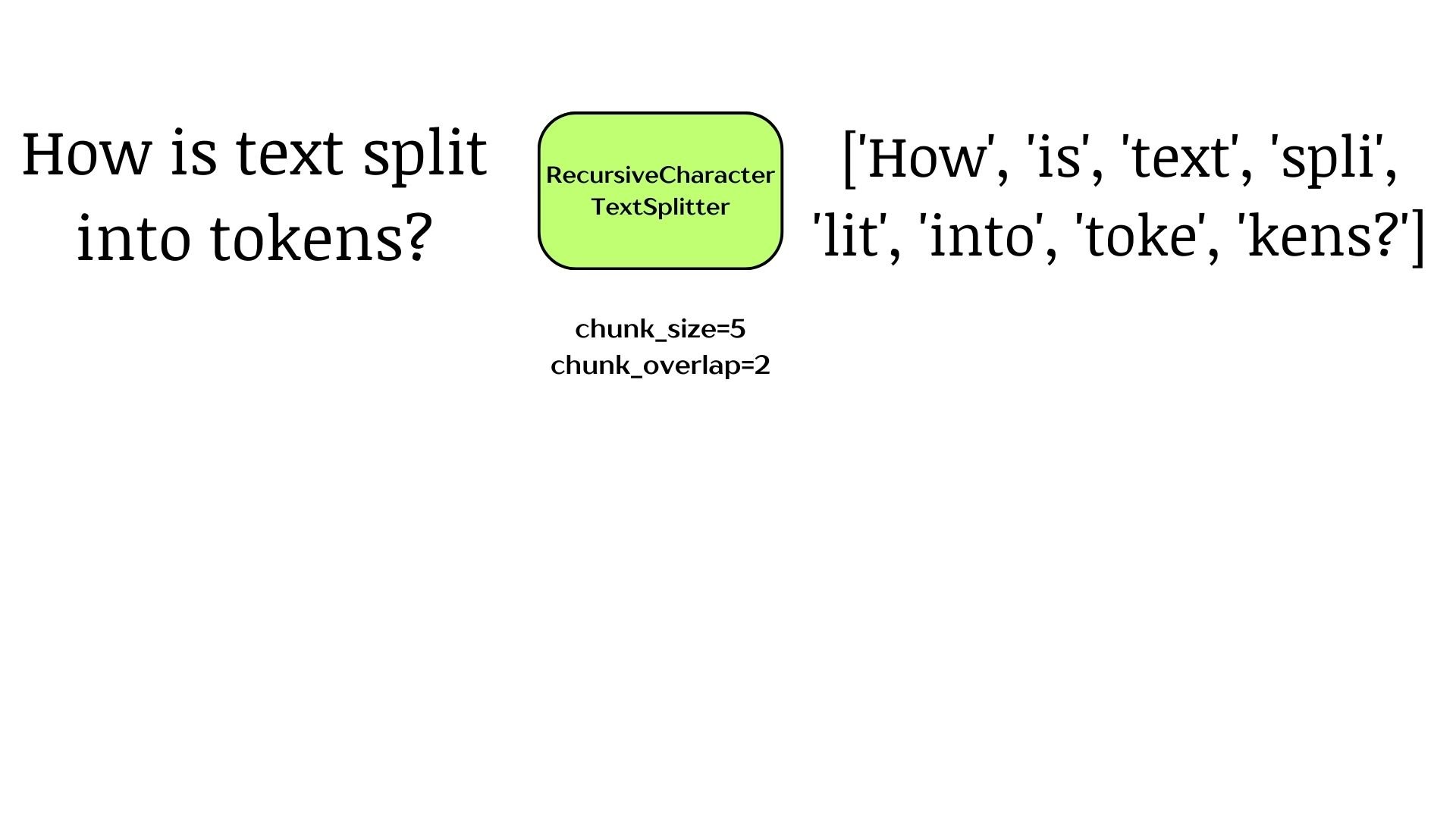
Splitting on tokens
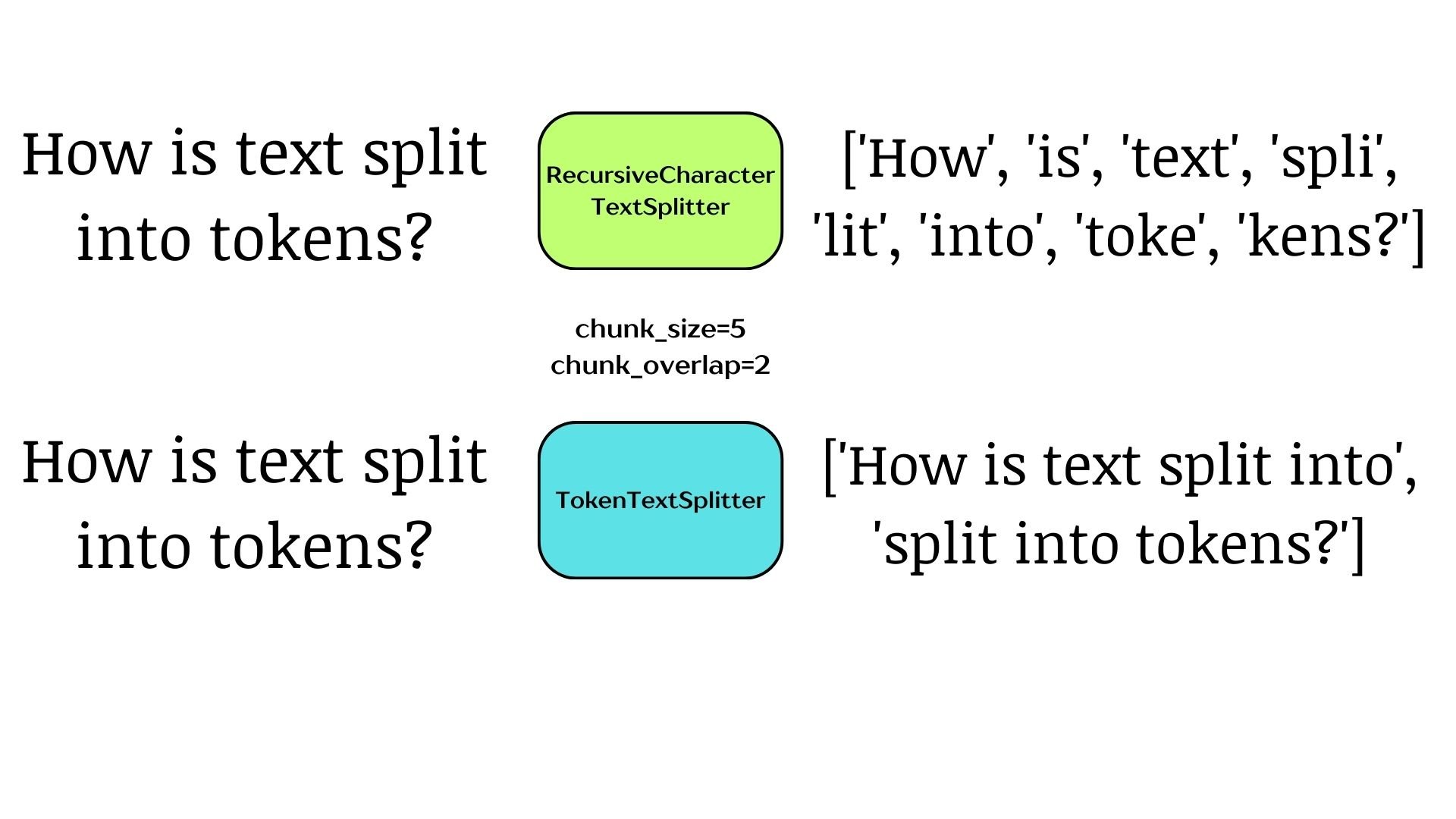
Splitting on tokens
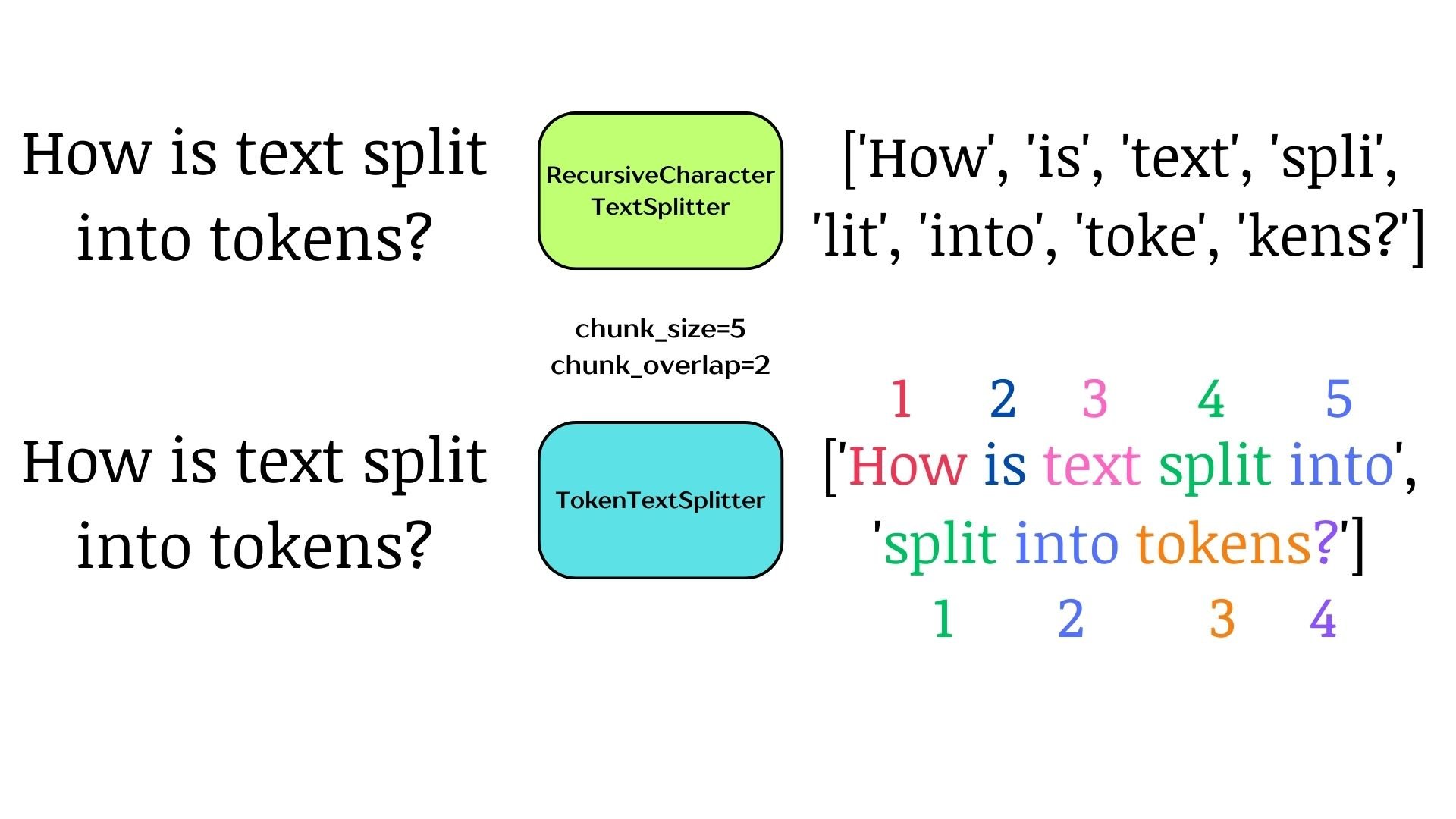
Semantic splitting

Semantic splitting

Semantic splitting

Retrieval Augmented Generation (RAG) with LangChain
Meri Nova
Machine Learning Engineer

