Loading Documents for RAG with LangChain
Retrieval Augmented Generation (RAG) with LangChain

Meri Nova
Machine Learning Engineer
Meet your instructor...


1 Generated with DALL·E 3
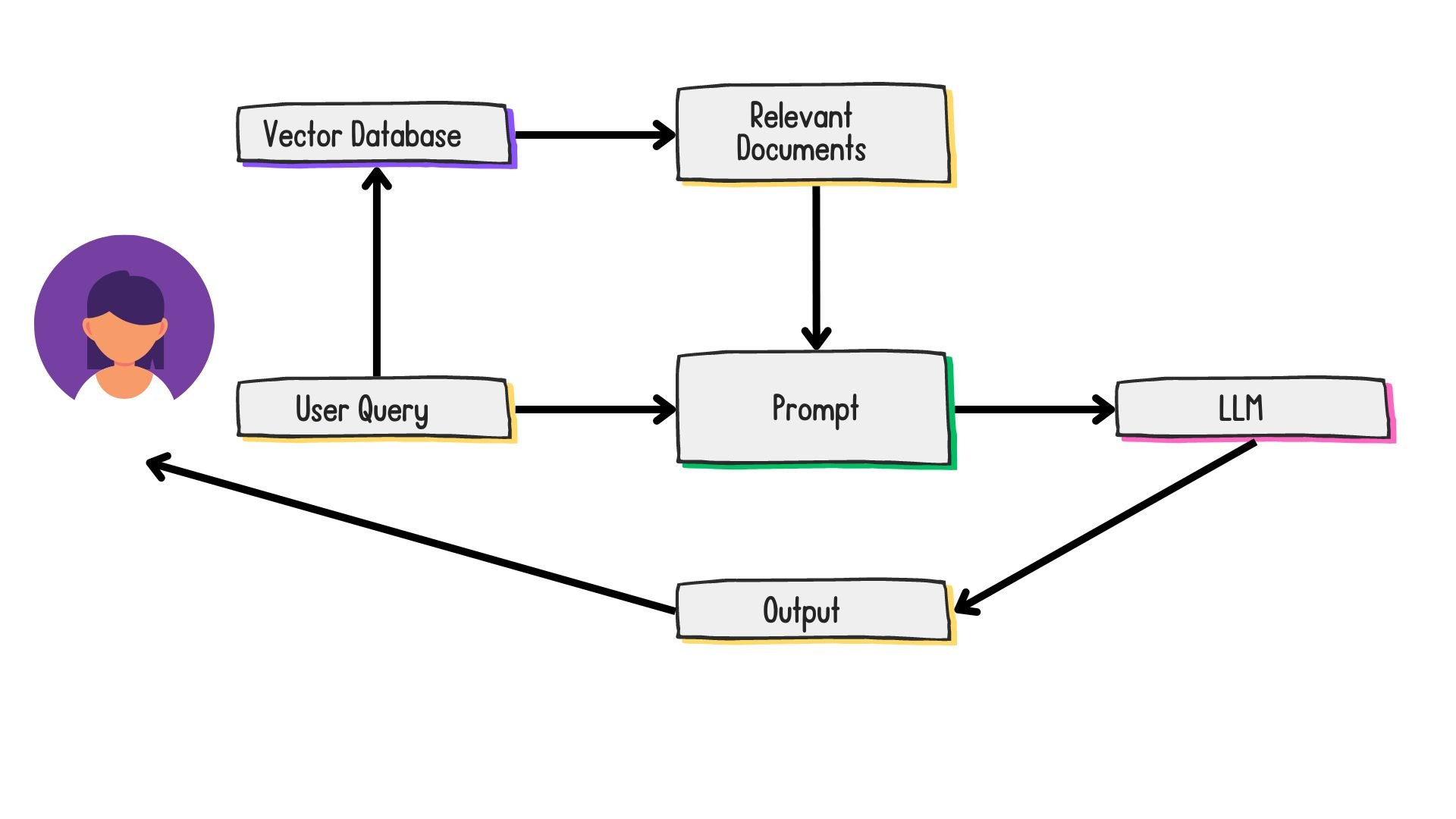
The standard RAG workflow

The standard RAG workflow
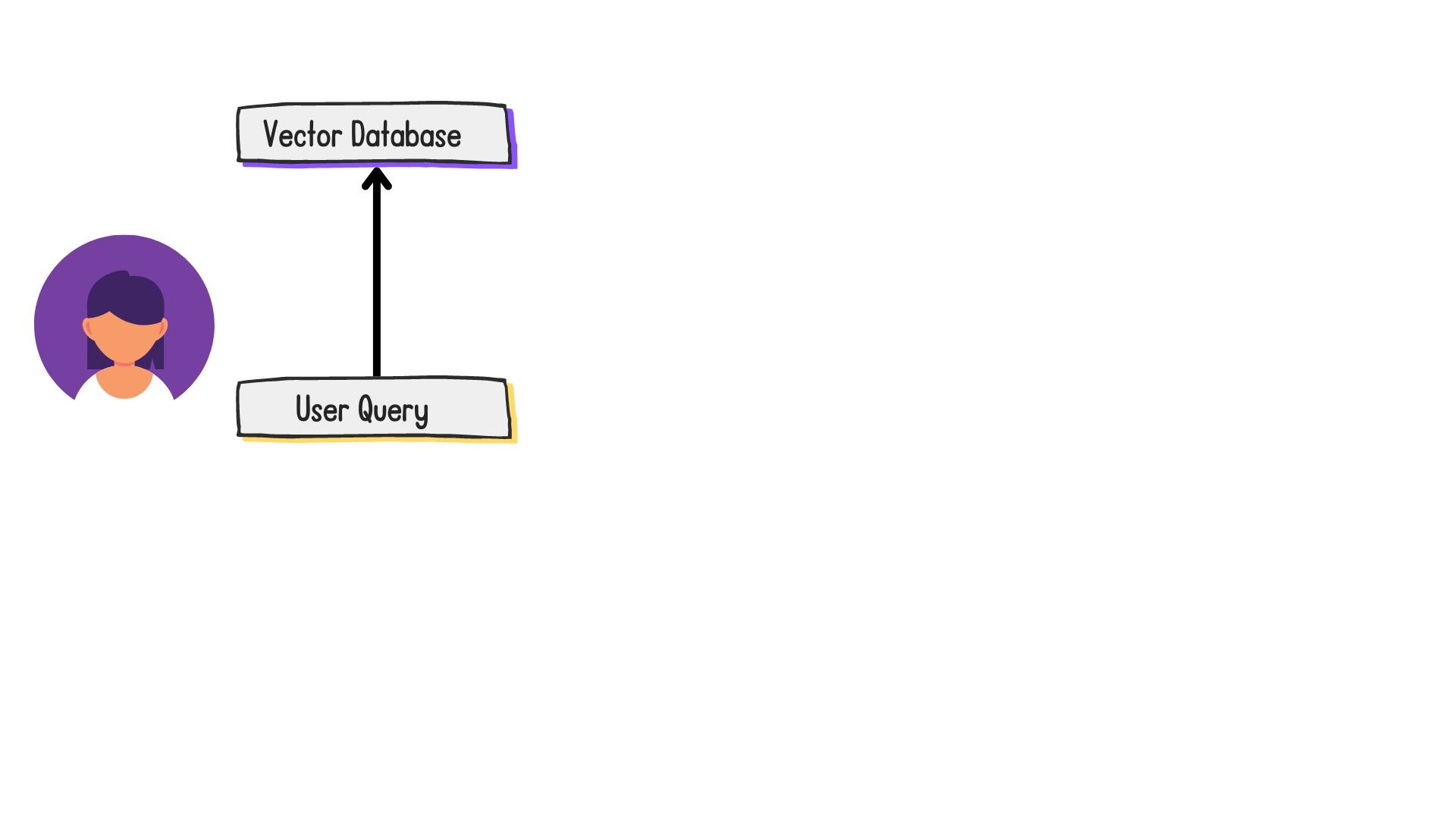
The standard RAG workflow
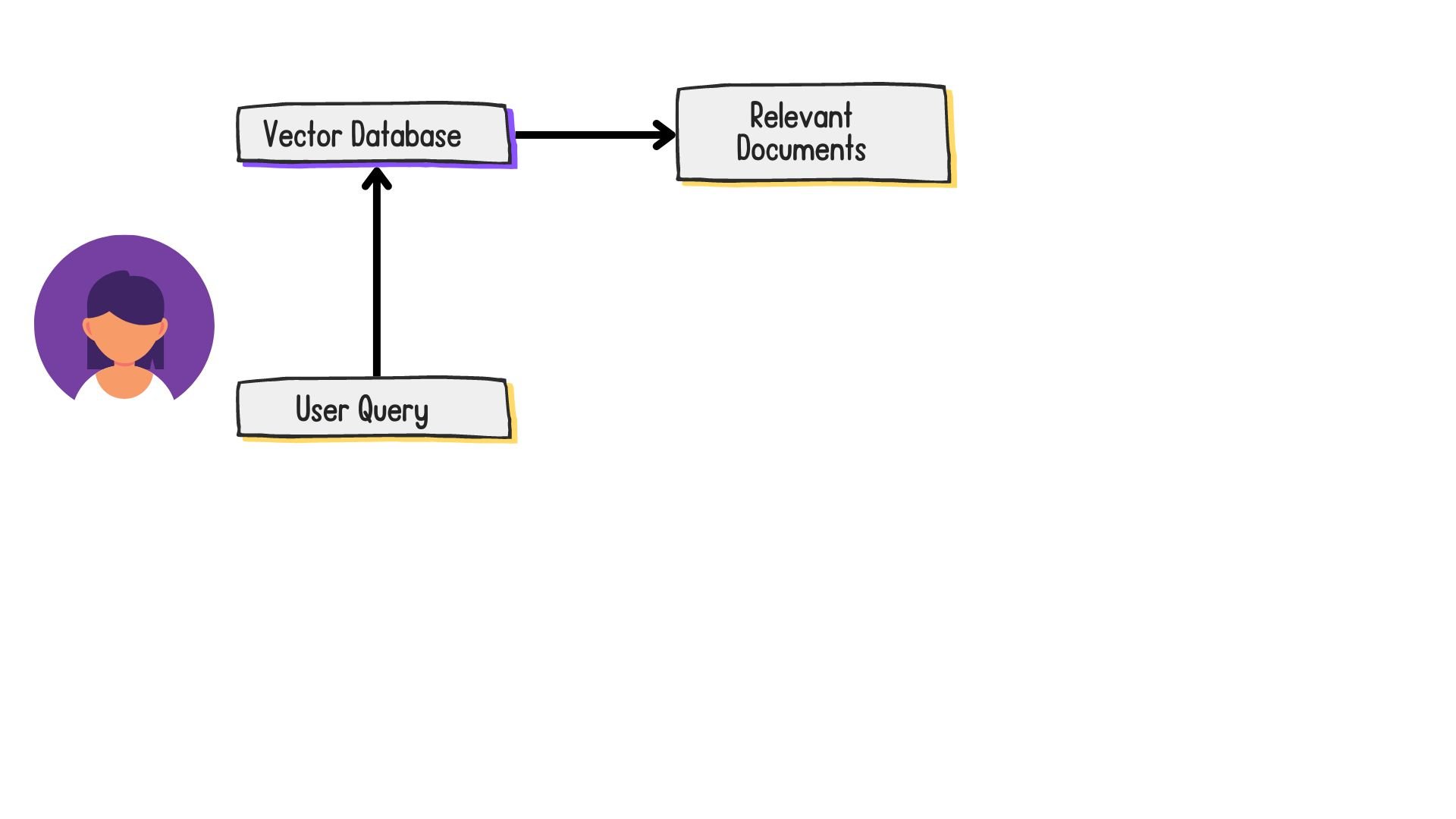
The standard RAG workflow
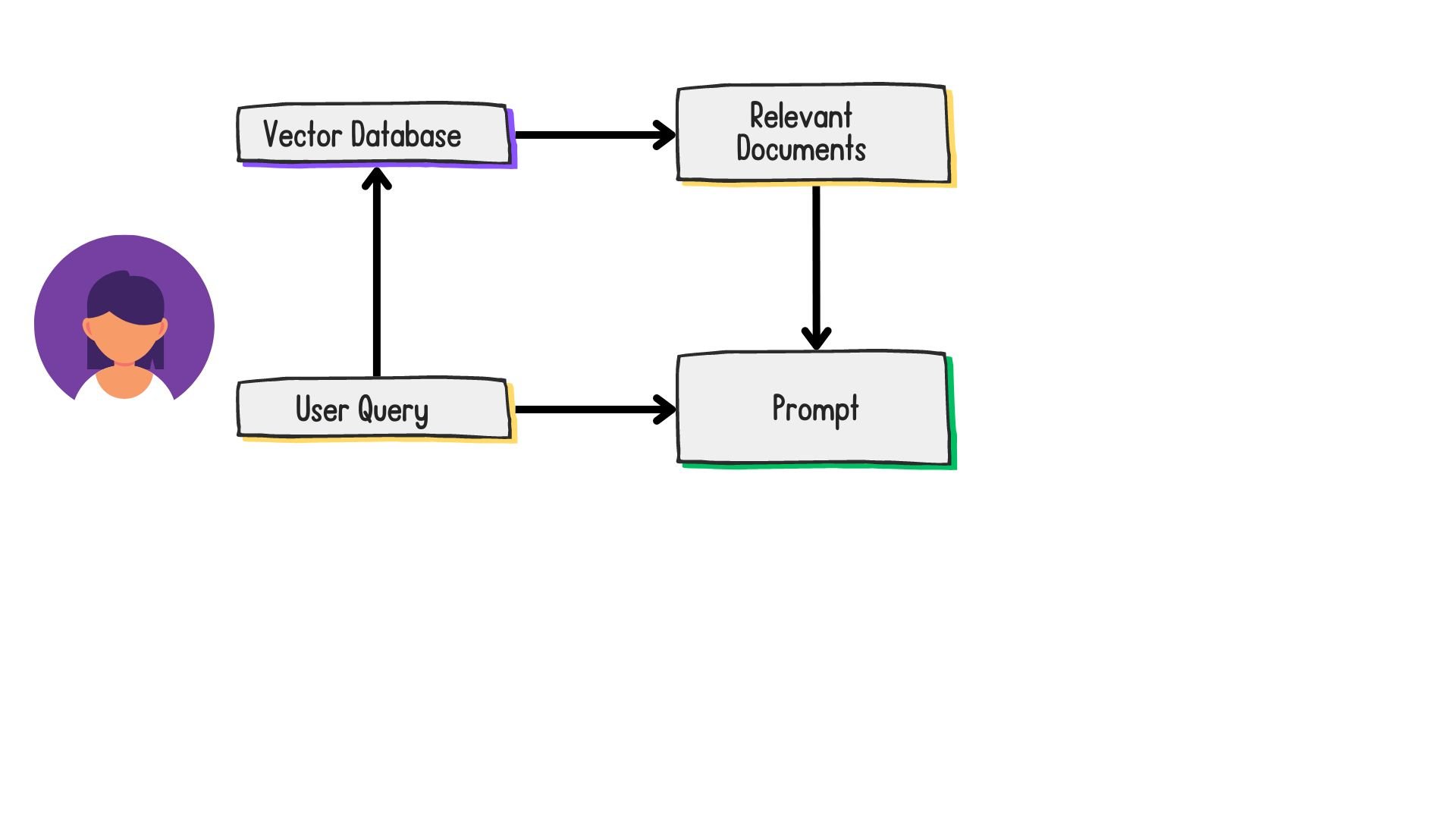
The standard RAG workflow
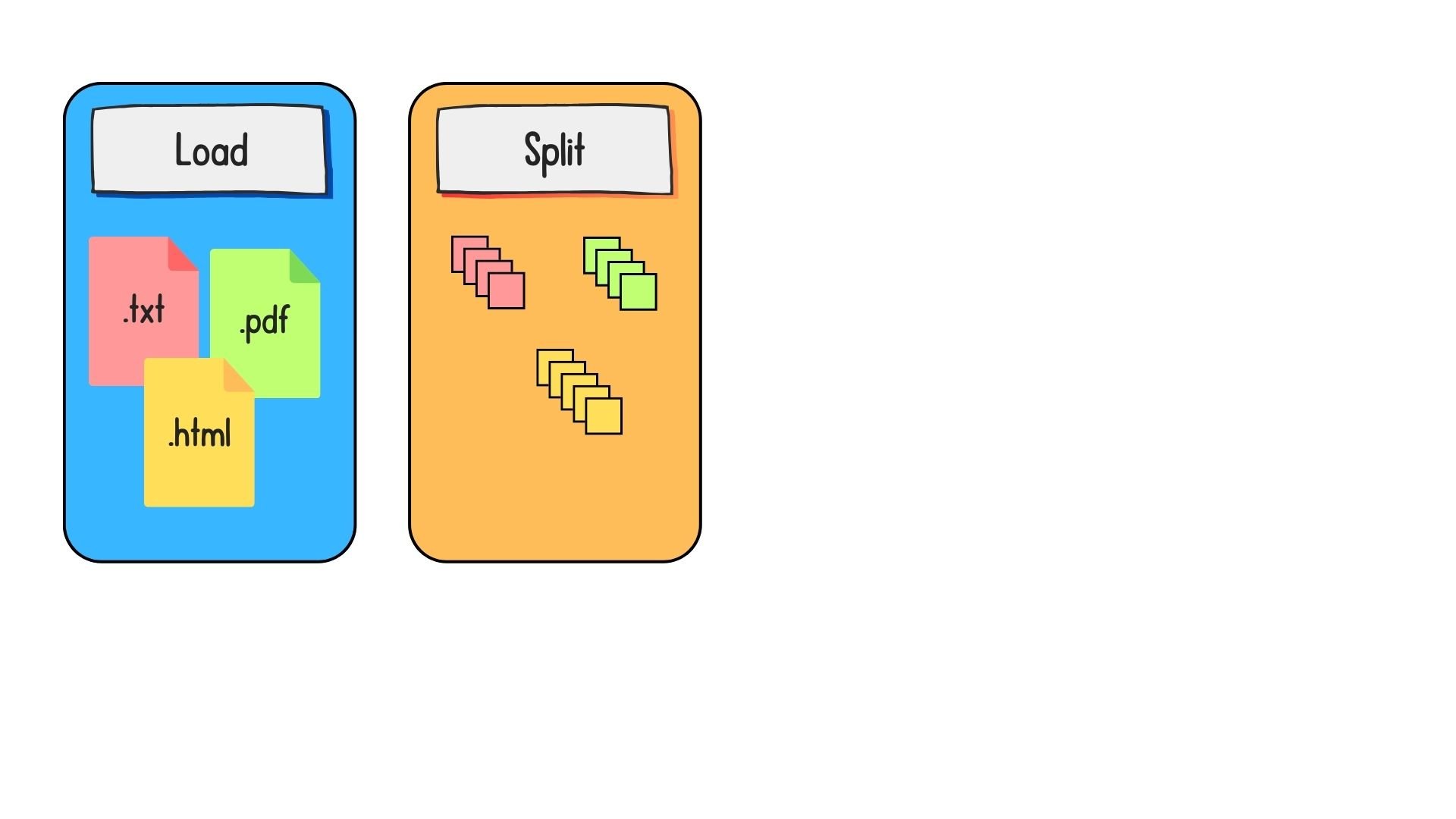
Preparing data for retrieval

Preparing data for retrieval
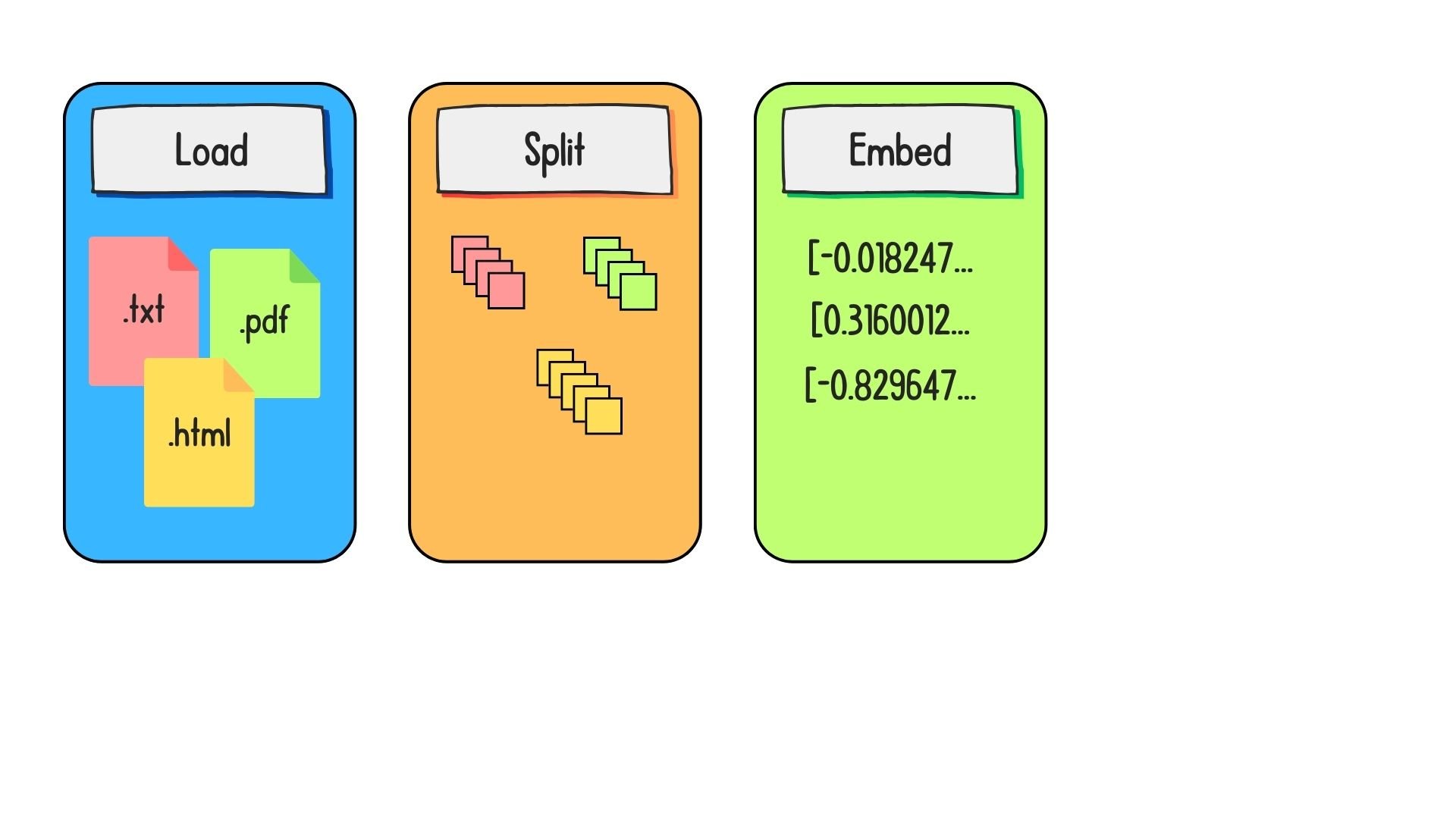
Preparing data for retrieval
Preparing data for retrieval
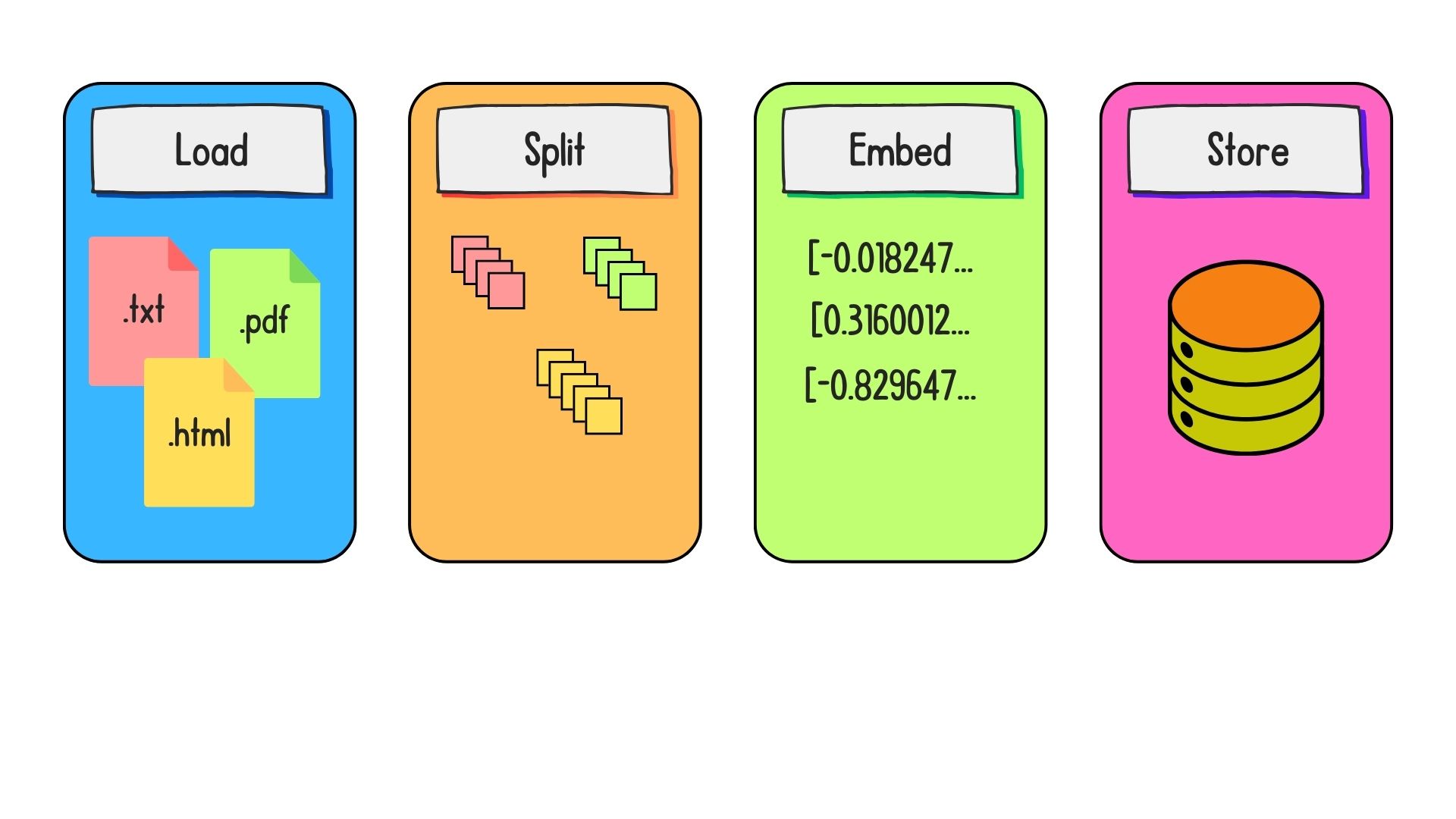
Document loaders